 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreaking Watermarks in the Frequency Domain: A Modulated Diffusion Attack Framework
Apr 24, 2026Digital image watermarking has advanced rapidly for copyright protection of generative AI, yet the comparatively limited progress in watermark attack techniques has broken the attack-defense balance and hindered further advances in the field. In this paper, we propose FMDiffWA, a frequency-domain modulated diffusion framework for watermark attacks. Specifically, we introduce a frequency-domain watermark modulation (FWM) module and incorporate it into the sampling stages both the forward and reverse diffusion processes. This mechanism enables selective modulation of watermark-related frequency components, thereby allowing FMDiffWA to effectively neutralize the invisible watermark signals while preserving the perceptual quality of the attacked watermarked images. To achieve a better trade-off between attack efficacy and visual fidelity, we reformulate the training strategy of conventional diffusion models by augmenting the canonical noise estimation objective with an auxiliary refinement constraint. Comprehensive experiments demonstrate that FMDiffWA achieves superior visual fidelity compared to existing watermark attacks, while exhibiting strong generalization across diverse watermarking schemes.
VLGOR: Visual-Language Knowledge Guided Offline Reinforcement Learning for Generalizable Agents
Mar 24, 2026Combining Large Language Models (LLMs) with Reinforcement Learning (RL) enables agents to interpret language instructions more effectively for task execution. However, LLMs typically lack direct perception of the physical environment, which limits their understanding of environmental dynamics and their ability to generalize to unseen tasks. To address this limitation, we propose Visual-Language Knowledge-Guided Offline Reinforcement Learning (VLGOR), a framework that integrates visual and language knowledge to generate imaginary rollouts, thereby enriching the interaction data. The core premise of VLGOR is to fine-tune a vision-language model to predict future states and actions conditioned on an initial visual observation and high-level instructions, ensuring that the generated rollouts remain temporally coherent and spatially plausible. Furthermore, we employ counterfactual prompts to produce more diverse rollouts for offline RL training, enabling the agent to acquire knowledge that facilitates following language instructions while grounding in environments based on visual cues. Experiments on robotic manipulation benchmarks demonstrate that VLGOR significantly improves performance on unseen tasks requiring novel optimal policies, achieving a success rate over 24% higher than the baseline methods.
GLM-5: from Vibe Coding to Agentic Engineering
Feb 17, 2026We present GLM-5, a next-generation foundation model designed to transition the paradigm of vibe coding to agentic engineering. Building upon the agentic, reasoning, and coding (ARC) capabilities of its predecessor, GLM-5 adopts DSA to significantly reduce training and inference costs while maintaining long-context fidelity. To advance model alignment and autonomy, we implement a new asynchronous reinforcement learning infrastructure that drastically improves post-training efficiency by decoupling generation from training. Furthermore, we propose novel asynchronous agent RL algorithms that further improve RL quality, enabling the model to learn from complex, long-horizon interactions more effectively. Through these innovations, GLM-5 achieves state-of-the-art performance on major open benchmarks. Most critically, GLM-5 demonstrates unprecedented capability in real-world coding tasks, surpassing previous baselines in handling end-to-end software engineering challenges. Code, models, and more information are available at https://github.com/zai-org/GLM-5.
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
Aug 08, 2025We present GLM-4.5, an open-source Mixture-of-Experts (MoE) large language model with 355B total parameters and 32B activated parameters, featuring a hybrid reasoning method that supports both thinking and direct response modes. Through multi-stage training on 23T tokens and comprehensive post-training with expert model iteration and reinforcement learning, GLM-4.5 achieves strong performance across agentic, reasoning, and coding (ARC) tasks, scoring 70.1% on TAU-Bench, 91.0% on AIME 24, and 64.2% on SWE-bench Verified. With much fewer parameters than several competitors, GLM-4.5 ranks 3rd overall among all evaluated models and 2nd on agentic benchmarks. We release both GLM-4.5 (355B parameters) and a compact version, GLM-4.5-Air (106B parameters), to advance research in reasoning and agentic AI systems. Code, models, and more information are available at https://github.com/zai-org/GLM-4.5.
Divide and Conquer: Hybrid Pre-training for Person Search
Dec 13, 2023Large-scale pre-training has proven to be an effective method for improving performance across different tasks. Current person search methods use ImageNet pre-trained models for feature extraction, yet it is not an optimal solution due to the gap between the pre-training task and person search task (as a downstream task). Therefore, in this paper, we focus on pre-training for person search, which involves detecting and re-identifying individuals simultaneously. Although labeled data for person search is scarce, datasets for two sub-tasks person detection and re-identification are relatively abundant. To this end, we propose a hybrid pre-training framework specifically designed for person search using sub-task data only. It consists of a hybrid learning paradigm that handles data with different kinds of supervisions, and an intra-task alignment module that alleviates domain discrepancy under limited resources. To the best of our knowledge, this is the first work that investigates how to support full-task pre-training using sub-task data. Extensive experiments demonstrate that our pre-trained model can achieve significant improvements across diverse protocols, such as person search method, fine-tuning data, pre-training data and model backbone. For example, our model improves ResNet50 based NAE by 10.3% relative improvement w.r.t. mAP. Our code and pre-trained models are released for plug-and-play usage to the person search community.
Online Learning and Optimization for Queues with Unknown Demand Curve and Service Distribution
Mar 06, 2023



We investigate an optimization problem in a queueing system where the service provider selects the optimal service fee p and service capacity \mu to maximize the cumulative expected profit (the service revenue minus the capacity cost and delay penalty). The conventional predict-then-optimize (PTO) approach takes two steps: first, it estimates the model parameters (e.g., arrival rate and service-time distribution) from data; second, it optimizes a model based on the estimated parameters. A major drawback of PTO is that its solution accuracy can often be highly sensitive to the parameter estimation errors because PTO is unable to properly link these errors (step 1) to the quality of the optimized solutions (step 2). To remedy this issue, we develop an online learning framework that automatically incorporates the aforementioned parameter estimation errors in the solution prescription process; it is an integrated method that can "learn" the optimal solution without needing to set up the parameter estimation as a separate step as in PTO. Effectiveness of our online learning approach is substantiated by (i) theoretical results including the algorithm convergence and analysis of the regret ("cost" to pay over time for the algorithm to learn the optimal policy), and (ii) engineering confirmation via simulation experiments of a variety of representative examples. We also provide careful comparisons for PTO and the online learning method.
Grouped Adaptive Loss Weighting for Person Search
Sep 23, 2022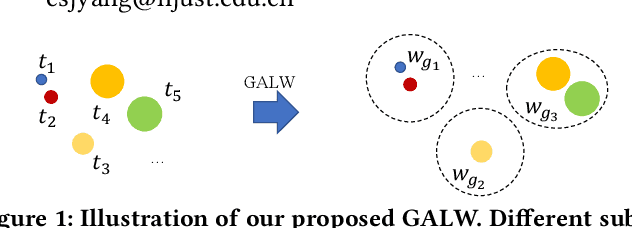
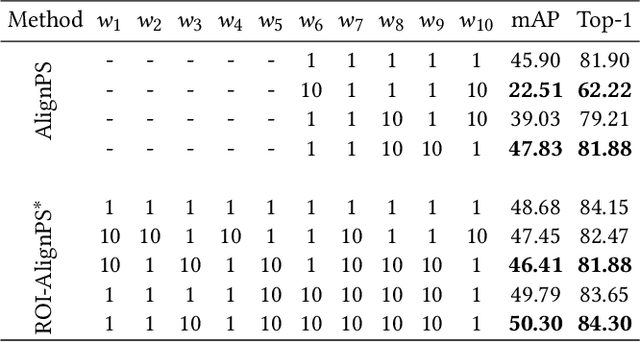
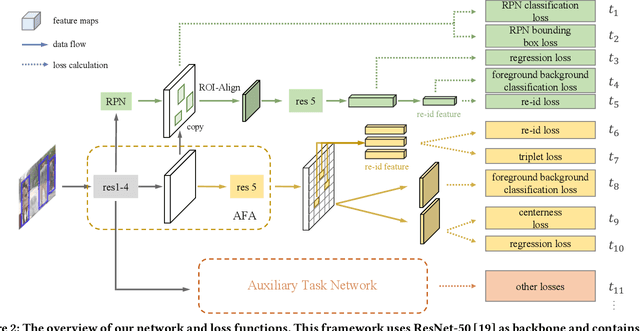
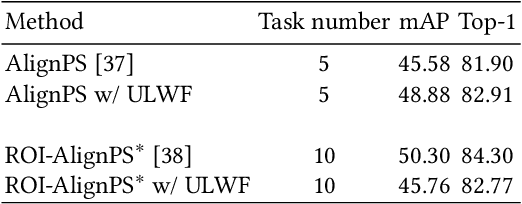
Person search is an integrated task of multiple sub-tasks such as foreground/background classification, bounding box regression and person re-identification. Therefore, person search is a typical multi-task learning problem, especially when solved in an end-to-end manner. Recently, some works enhance person search features by exploiting various auxiliary information, e.g. person joint keypoints, body part position, attributes, etc., which brings in more tasks and further complexifies a person search model. The inconsistent convergence rate of each task could potentially harm the model optimization. A straightforward solution is to manually assign different weights to different tasks, compensating for the diverse convergence rates. However, given the special case of person search, i.e. with a large number of tasks, it is impractical to weight the tasks manually. To this end, we propose a Grouped Adaptive Loss Weighting (GALW) method which adjusts the weight of each task automatically and dynamically. Specifically, we group tasks according to their convergence rates. Tasks within the same group share the same learnable weight, which is dynamically assigned by considering the loss uncertainty. Experimental results on two typical benchmarks, CUHK-SYSU and PRW, demonstrate the effectiveness of our method.
An online learning approach to dynamic pricing and capacity sizing in service systems
Sep 07, 2020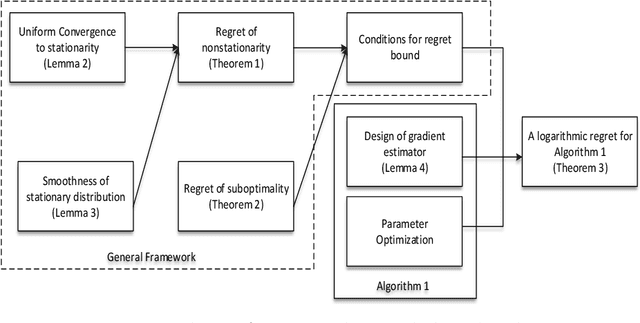
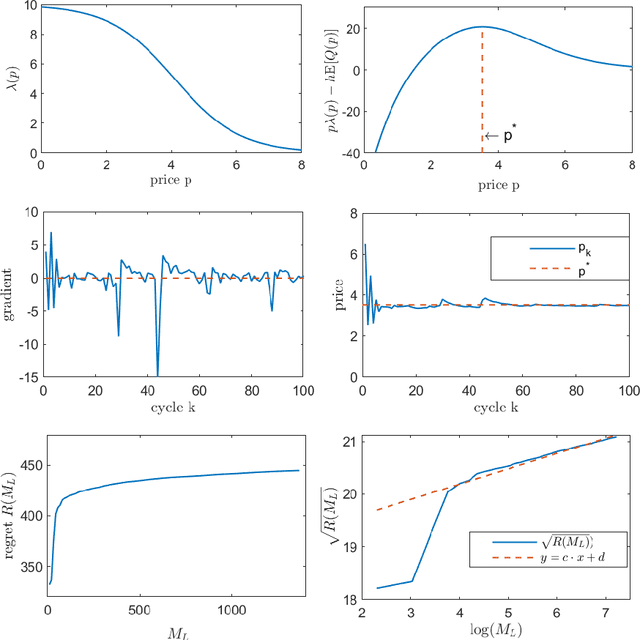
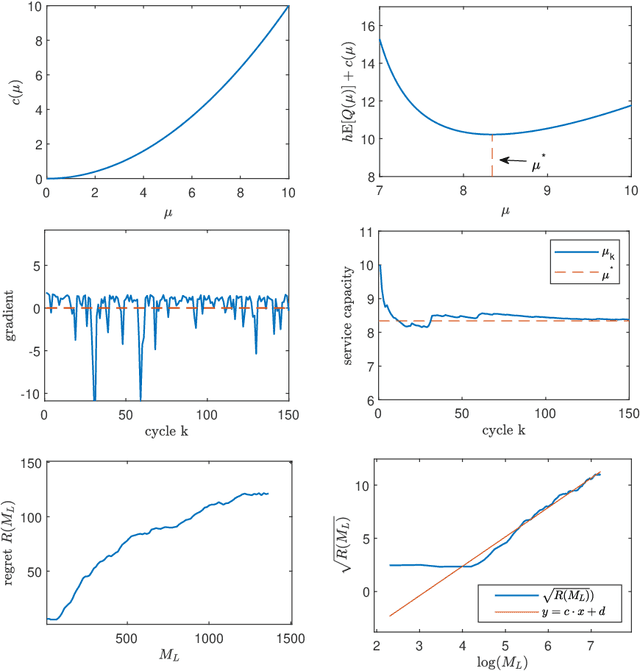
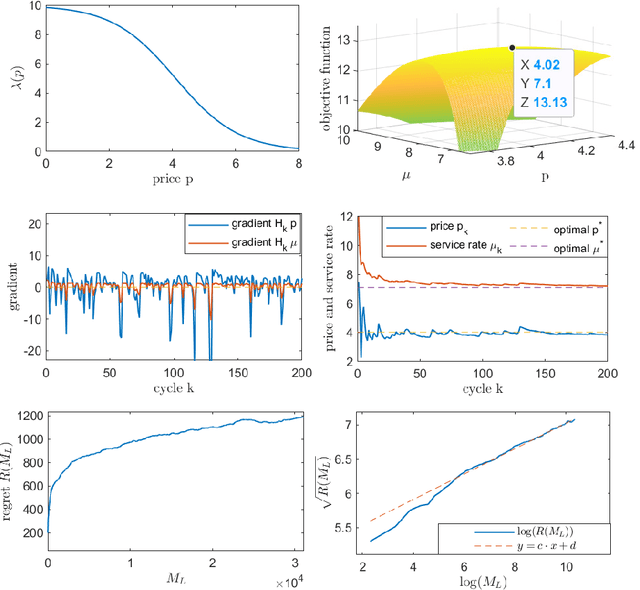
We study a dynamic pricing and capacity sizing problem in a GI/GI/1 queue, where the service provider's objective is to obtain the optimal service fee $p$ and service capacity $\mu$ so as to maximize cumulative expected profit (the service revenue minus the staffing cost and delay penalty). Due to the complex nature of the queueing dynamics, such a problem has no analytic solution so that previous research often resorts to heavy-traffic analysis in that both the arrival rate and service rate are sent to infinity. In this work we propose an online learning framework designed for solving this problem which does not require the system's scale to increase. Our algorithm organizes the time horizon into successive operational cycles and prescribes an efficient procedure to obtain improved pricing and staffing policies in each cycle using data collected in previous cycles. Data here include the number of customer arrivals, waiting times, and the server's busy times. The ingenuity of this approach lies in its online nature, which allows the service provider do better by interacting with the environment. Effectiveness of our online learning algorithm is substantiated by (i) theoretical results including the algorithm convergence and regret analysis (with a logarithmic regret bound), and (ii) engineering confirmation via simulation experiments of a variety of representative GI/GI/1 queues.