 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDivide and Conquer: Hybrid Pre-training for Person Search
Dec 13, 2023Large-scale pre-training has proven to be an effective method for improving performance across different tasks. Current person search methods use ImageNet pre-trained models for feature extraction, yet it is not an optimal solution due to the gap between the pre-training task and person search task (as a downstream task). Therefore, in this paper, we focus on pre-training for person search, which involves detecting and re-identifying individuals simultaneously. Although labeled data for person search is scarce, datasets for two sub-tasks person detection and re-identification are relatively abundant. To this end, we propose a hybrid pre-training framework specifically designed for person search using sub-task data only. It consists of a hybrid learning paradigm that handles data with different kinds of supervisions, and an intra-task alignment module that alleviates domain discrepancy under limited resources. To the best of our knowledge, this is the first work that investigates how to support full-task pre-training using sub-task data. Extensive experiments demonstrate that our pre-trained model can achieve significant improvements across diverse protocols, such as person search method, fine-tuning data, pre-training data and model backbone. For example, our model improves ResNet50 based NAE by 10.3% relative improvement w.r.t. mAP. Our code and pre-trained models are released for plug-and-play usage to the person search community.
Grouped Adaptive Loss Weighting for Person Search
Sep 23, 2022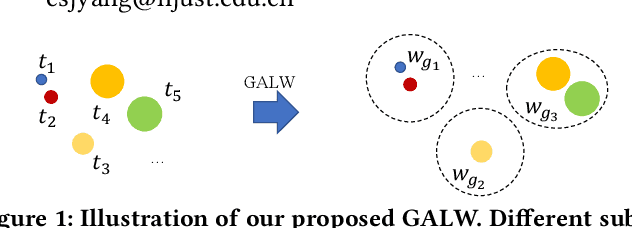
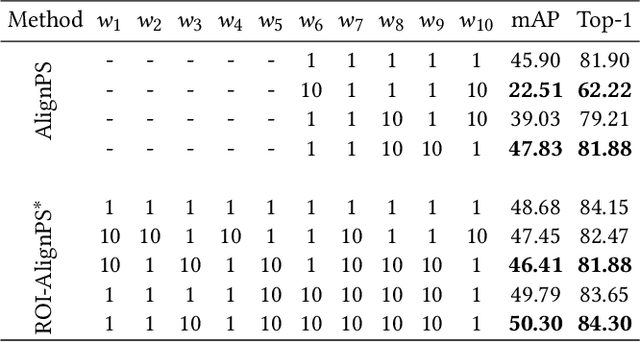
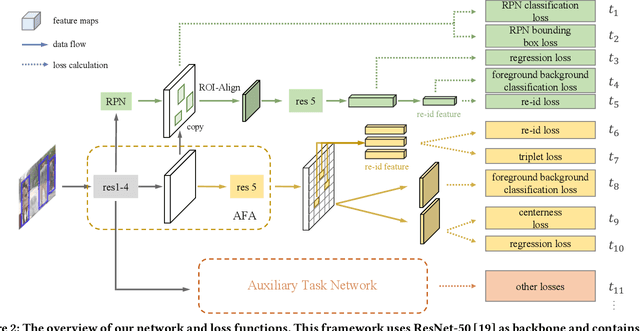
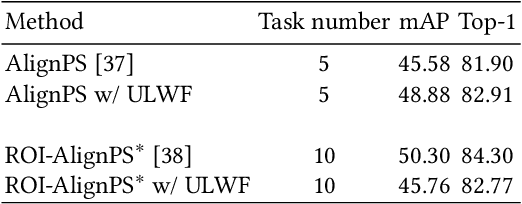
Person search is an integrated task of multiple sub-tasks such as foreground/background classification, bounding box regression and person re-identification. Therefore, person search is a typical multi-task learning problem, especially when solved in an end-to-end manner. Recently, some works enhance person search features by exploiting various auxiliary information, e.g. person joint keypoints, body part position, attributes, etc., which brings in more tasks and further complexifies a person search model. The inconsistent convergence rate of each task could potentially harm the model optimization. A straightforward solution is to manually assign different weights to different tasks, compensating for the diverse convergence rates. However, given the special case of person search, i.e. with a large number of tasks, it is impractical to weight the tasks manually. To this end, we propose a Grouped Adaptive Loss Weighting (GALW) method which adjusts the weight of each task automatically and dynamically. Specifically, we group tasks according to their convergence rates. Tasks within the same group share the same learnable weight, which is dynamically assigned by considering the loss uncertainty. Experimental results on two typical benchmarks, CUHK-SYSU and PRW, demonstrate the effectiveness of our method.