 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFMBench: Adaptive Large Language Model Output Formatting
Feb 06, 2026Producing outputs that satisfy both semantic intent and format constraints is essential for deploying large language models in user-facing and system-integrated workflows. In this work, we focus on Markdown formatting, which is ubiquitous in assistants, documentation, and tool-augmented pipelines but still prone to subtle, hard-to-detect errors (e.g., broken lists, malformed tables, inconsistent headings, and invalid code blocks) that can significantly degrade downstream usability. We present FMBench, a benchmark for adaptive Markdown output formatting that evaluates models under a wide range of instruction-following scenarios with diverse structural requirements. FMBench emphasizes real-world formatting behaviors such as multi-level organization, mixed content (natural language interleaved with lists/tables/code), and strict adherence to user-specified layout constraints. To improve Markdown compliance without relying on hard decoding constraints, we propose a lightweight alignment pipeline that combines supervised fine-tuning (SFT) with reinforcement learning fine-tuning. Starting from a base model, we first perform SFT on instruction-response pairs, and then optimize a composite objective that balances semantic fidelity with structural correctness. Experiments on two model families (OpenPangu and Qwen) show that SFT consistently improves semantic alignment, while reinforcement learning provides additional gains in robustness to challenging Markdown instructions when initialized from a strong SFT policy. Our results also reveal an inherent trade-off between semantic and structural objectives, highlighting the importance of carefully designed rewards for reliable formatted generation. Code is available at: https://github.com/FudanCVL/FMBench.
Audit After Segmentation: Reference-Free Mask Quality Assessment for Language-Referred Audio-Visual Segmentation
Feb 03, 2026Language-referred audio-visual segmentation (Ref-AVS) aims to segment target objects described by natural language by jointly reasoning over video, audio, and text. Beyond generating segmentation masks, providing rich and interpretable diagnoses of mask quality remains largely underexplored. In this work, we introduce Mask Quality Assessment in the Ref-AVS context (MQA-RefAVS), a new task that evaluates the quality of candidate segmentation masks without relying on ground-truth annotations as references at inference time. Given audio-visual-language inputs and each provided segmentation mask, the task requires estimating its IoU with the unobserved ground truth, identifying the corresponding error type, and recommending an actionable quality-control decision. To support this task, we construct MQ-RAVSBench, a benchmark featuring diverse and representative mask error modes that span both geometric and semantic issues. We further propose MQ-Auditor, a multimodal large language model (MLLM)-based auditor that explicitly reasons over multimodal cues and mask information to produce quantitative and qualitative mask quality assessments. Extensive experiments demonstrate that MQ-Auditor outperforms strong open-source and commercial MLLMs and can be integrated with existing Ref-AVS systems to detect segmentation failures and support downstream segmentation improvement. Data and codes will be released at https://github.com/jasongief/MQA-RefAVS.
On Path to Multimodal Generalist: General-Level and General-Bench
May 07, 2025The Multimodal Large Language Model (MLLM) is currently experiencing rapid growth, driven by the advanced capabilities of LLMs. Unlike earlier specialists, existing MLLMs are evolving towards a Multimodal Generalist paradigm. Initially limited to understanding multiple modalities, these models have advanced to not only comprehend but also generate across modalities. Their capabilities have expanded from coarse-grained to fine-grained multimodal understanding and from supporting limited modalities to arbitrary ones. While many benchmarks exist to assess MLLMs, a critical question arises: Can we simply assume that higher performance across tasks indicates a stronger MLLM capability, bringing us closer to human-level AI? We argue that the answer is not as straightforward as it seems. This project introduces General-Level, an evaluation framework that defines 5-scale levels of MLLM performance and generality, offering a methodology to compare MLLMs and gauge the progress of existing systems towards more robust multimodal generalists and, ultimately, towards AGI. At the core of the framework is the concept of Synergy, which measures whether models maintain consistent capabilities across comprehension and generation, and across multiple modalities. To support this evaluation, we present General-Bench, which encompasses a broader spectrum of skills, modalities, formats, and capabilities, including over 700 tasks and 325,800 instances. The evaluation results that involve over 100 existing state-of-the-art MLLMs uncover the capability rankings of generalists, highlighting the challenges in reaching genuine AI. We expect this project to pave the way for future research on next-generation multimodal foundation models, providing a robust infrastructure to accelerate the realization of AGI. Project page: https://generalist.top/
Multimodal Chain-of-Thought Reasoning: A Comprehensive Survey
Mar 16, 2025

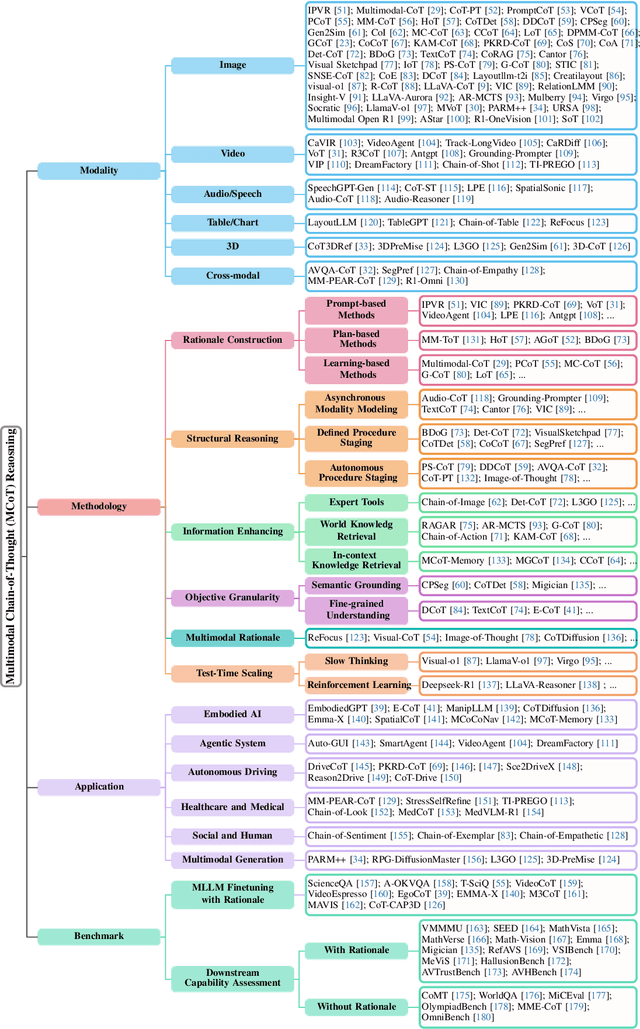
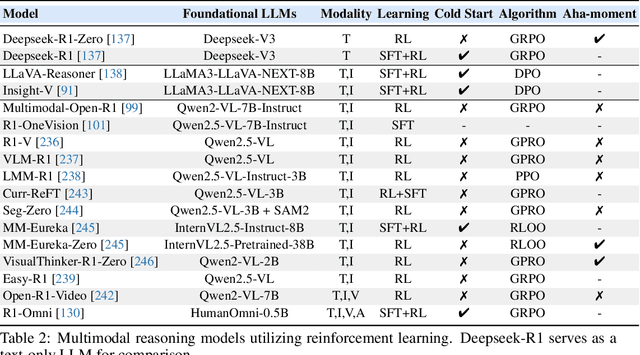
By extending the advantage of chain-of-thought (CoT) reasoning in human-like step-by-step processes to multimodal contexts, multimodal CoT (MCoT) reasoning has recently garnered significant research attention, especially in the integration with multimodal large language models (MLLMs). Existing MCoT studies design various methodologies and innovative reasoning paradigms to address the unique challenges of image, video, speech, audio, 3D, and structured data across different modalities, achieving extensive success in applications such as robotics, healthcare, autonomous driving, and multimodal generation. However, MCoT still presents distinct challenges and opportunities that require further focus to ensure consistent thriving in this field, where, unfortunately, an up-to-date review of this domain is lacking. To bridge this gap, we present the first systematic survey of MCoT reasoning, elucidating the relevant foundational concepts and definitions. We offer a comprehensive taxonomy and an in-depth analysis of current methodologies from diverse perspectives across various application scenarios. Furthermore, we provide insights into existing challenges and future research directions, aiming to foster innovation toward multimodal AGI.
AVTrustBench: Assessing and Enhancing Reliability and Robustness in Audio-Visual LLMs
Jan 03, 2025



With the rapid advancement of Multi-modal Large Language Models (MLLMs), several diagnostic benchmarks have recently been developed to assess these models' multi-modal reasoning proficiency. However, these benchmarks are restricted to assessing primarily the visual aspect and do not examine the holistic audio-visual (AV) understanding. Moreover, currently, there are no benchmarks that investigate the capabilities of AVLLMs to calibrate their responses when presented with perturbed inputs. To this end, we introduce Audio-Visual Trustworthiness assessment Benchmark (AVTrustBench), comprising 600K samples spanning over 9 meticulously crafted tasks, evaluating the capabilities of AVLLMs across three distinct dimensions: Adversarial attack, Compositional reasoning, and Modality-specific dependency. Using our benchmark we extensively evaluate 13 state-of-the-art AVLLMs. The findings reveal that the majority of existing models fall significantly short of achieving human-like comprehension, offering valuable insights for future research directions. To alleviate the limitations in the existing approaches, we further propose a robust, model-agnostic calibrated audio-visual preference optimization based training strategy CAVPref, obtaining a gain up to 30.19% across all 9 tasks. We will publicly release our code and benchmark to facilitate future research in this direction.
Stepping Stones: A Progressive Training Strategy for Audio-Visual Semantic Segmentation
Jul 16, 2024



Audio-Visual Segmentation (AVS) aims to achieve pixel-level localization of sound sources in videos, while Audio-Visual Semantic Segmentation (AVSS), as an extension of AVS, further pursues semantic understanding of audio-visual scenes. However, since the AVSS task requires the establishment of audio-visual correspondence and semantic understanding simultaneously, we observe that previous methods have struggled to handle this mashup of objectives in end-to-end training, resulting in insufficient learning and sub-optimization. Therefore, we propose a two-stage training strategy called \textit{Stepping Stones}, which decomposes the AVSS task into two simple subtasks from localization to semantic understanding, which are fully optimized in each stage to achieve step-by-step global optimization. This training strategy has also proved its generalization and effectiveness on existing methods. To further improve the performance of AVS tasks, we propose a novel framework Adaptive Audio Visual Segmentation, in which we incorporate an adaptive audio query generator and integrate masked attention into the transformer decoder, facilitating the adaptive fusion of visual and audio features. Extensive experiments demonstrate that our methods achieve state-of-the-art results on all three AVS benchmarks. The project homepage can be accessed at https://gewu-lab.github.io/stepping_stones/.
Ref-AVS: Refer and Segment Objects in Audio-Visual Scenes
Jul 15, 2024Traditional reference segmentation tasks have predominantly focused on silent visual scenes, neglecting the integral role of multimodal perception and interaction in human experiences. In this work, we introduce a novel task called Reference Audio-Visual Segmentation (Ref-AVS), which seeks to segment objects within the visual domain based on expressions containing multimodal cues. Such expressions are articulated in natural language forms but are enriched with multimodal cues, including audio and visual descriptions. To facilitate this research, we construct the first Ref-AVS benchmark, which provides pixel-level annotations for objects described in corresponding multimodal-cue expressions. To tackle the Ref-AVS task, we propose a new method that adequately utilizes multimodal cues to offer precise segmentation guidance. Finally, we conduct quantitative and qualitative experiments on three test subsets to compare our approach with existing methods from related tasks. The results demonstrate the effectiveness of our method, highlighting its capability to precisely segment objects using multimodal-cue expressions. Dataset is available at \href{https://gewu-lab.github.io/Ref-AVS}{https://gewu-lab.github.io/Ref-AVS}.
Can Textual Semantics Mitigate Sounding Object Segmentation Preference?
Jul 15, 2024



The Audio-Visual Segmentation (AVS) task aims to segment sounding objects in the visual space using audio cues. However, in this work, it is recognized that previous AVS methods show a heavy reliance on detrimental segmentation preferences related to audible objects, rather than precise audio guidance. We argue that the primary reason is that audio lacks robust semantics compared to vision, especially in multi-source sounding scenes, resulting in weak audio guidance over the visual space. Motivated by the the fact that text modality is well explored and contains rich abstract semantics, we propose leveraging text cues from the visual scene to enhance audio guidance with the semantics inherent in text. Our approach begins by obtaining scene descriptions through an off-the-shelf image captioner and prompting a frozen large language model to deduce potential sounding objects as text cues. Subsequently, we introduce a novel semantics-driven audio modeling module with a dynamic mask to integrate audio features with text cues, leading to representative sounding object features. These features not only encompass audio cues but also possess vivid semantics, providing clearer guidance in the visual space. Experimental results on AVS benchmarks validate that our method exhibits enhanced sensitivity to audio when aided by text cues, achieving highly competitive performance on all three subsets. Project page: \href{https://github.com/GeWu-Lab/Sounding-Object-Segmentation-Preference}{https://github.com/GeWu-Lab/Sounding-Object-Segmentation-Preference}
Prompting Segmentation with Sound is Generalizable Audio-Visual Source Localizer
Sep 18, 2023Never having seen an object and heard its sound simultaneously, can the model still accurately localize its visual position from the input audio? In this work, we concentrate on the Audio-Visual Localization and Segmentation tasks but under the demanding zero-shot and few-shot scenarios. To achieve this goal, different from existing approaches that mostly employ the encoder-fusion-decoder paradigm to decode localization information from the fused audio-visual feature, we introduce the encoder-prompt-decoder paradigm, aiming to better fit the data scarcity and varying data distribution dilemmas with the help of abundant knowledge from pre-trained models. Specifically, we first propose to construct Semantic-aware Audio Prompt (SAP) to help the visual foundation model focus on sounding objects, meanwhile, the semantic gap between the visual and audio modalities is also encouraged to shrink. Then, we develop a Correlation Adapter (ColA) to keep minimal training efforts as well as maintain adequate knowledge of the visual foundation model. By equipping with these means, extensive experiments demonstrate that this new paradigm outperforms other fusion-based methods in both the unseen class and cross-dataset settings. We hope that our work can further promote the generalization study of Audio-Visual Localization and Segmentation in practical application scenarios.
Cross-Attention is Not Enough: Incongruity-Aware Multimodal Sentiment Analysis and Emotion Recognition
May 23, 2023



Fusing multiple modalities for affective computing tasks has proven effective for performance improvement. However, how multimodal fusion works is not well understood, and its use in the real world usually results in large model sizes. In this work, on sentiment and emotion analysis, we first analyze how the salient affective information in one modality can be affected by the other in crossmodal attention. We find that inter-modal incongruity exists at the latent level due to crossmodal attention. Based on this finding, we propose a lightweight model via Hierarchical Crossmodal Transformer with Modality Gating (HCT-MG), which determines a primary modality according to its contribution to the target task and then hierarchically incorporates auxiliary modalities to alleviate inter-modal incongruity and reduce information redundancy. The experimental evaluation on three benchmark datasets: CMU-MOSI, CMU-MOSEI, and IEMOCAP verifies the efficacy of our approach, showing that it: 1) outperforms major prior work by achieving competitive results and can successfully recognize hard samples; 2) mitigates the inter-modal incongruity at the latent level when modalities have mismatched affective tendencies; 3) reduces model size to less than 1M parameters while outperforming existing models of similar sizes.