 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAFFORD2ACT: Affordance-Guided Automatic Keypoint Selection for Generalizable and Lightweight Robotic Manipulation
Oct 01, 2025Vision-based robot learning often relies on dense image or point-cloud inputs, which are computationally heavy and entangle irrelevant background features. Existing keypoint-based approaches can focus on manipulation-centric features and be lightweight, but either depend on manual heuristics or task-coupled selection, limiting scalability and semantic understanding. To address this, we propose AFFORD2ACT, an affordance-guided framework that distills a minimal set of semantic 2D keypoints from a text prompt and a single image. AFFORD2ACT follows a three-stage pipeline: affordance filtering, category-level keypoint construction, and transformer-based policy learning with embedded gating to reason about the most relevant keypoints, yielding a compact 38-dimensional state policy that can be trained in 15 minutes, which performs well in real-time without proprioception or dense representations. Across diverse real-world manipulation tasks, AFFORD2ACT consistently improves data efficiency, achieving an 82% success rate on unseen objects, novel categories, backgrounds, and distractors.
Towards Perception-Informed Latent HRTF Representations
Jul 03, 2025Personalized head-related transfer functions (HRTFs) are essential for ensuring a realistic auditory experience over headphones, because they take into account individual anatomical differences that affect listening. Most machine learning approaches to HRTF personalization rely on a learned low-dimensional latent space to generate or select custom HRTFs for a listener. However, these latent representations are typically learned in a manner that optimizes for spectral reconstruction but not for perceptual compatibility, meaning they may not necessarily align with perceptual distance. In this work, we first study whether traditionally learned HRTF representations are well correlated with perceptual relations using auditory-based objective perceptual metrics; we then propose a method for explicitly embedding HRTFs into a perception-informed latent space, leveraging a metric-based loss function and supervision via Metric Multidimensional Scaling (MMDS). Finally, we demonstrate the applicability of these learned representations to the task of HRTF personalization. We suggest that our method has the potential to render personalized spatial audio, leading to an improved listening experience.
ControlTac: Force- and Position-Controlled Tactile Data Augmentation with a Single Reference Image
May 28, 2025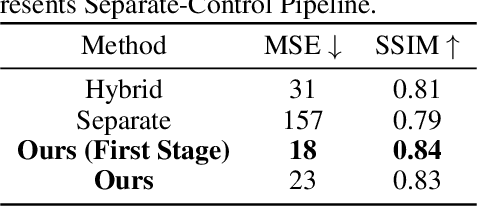
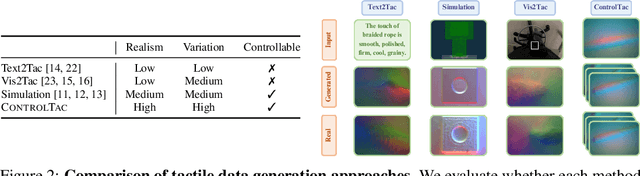
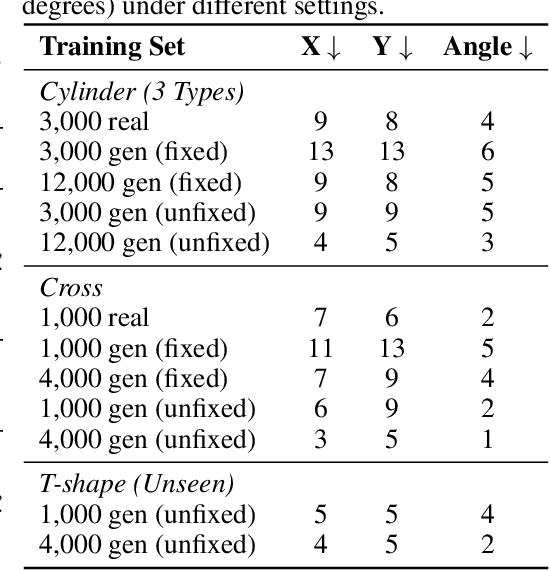
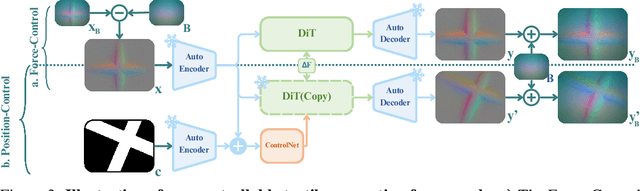
Vision-based tactile sensing has been widely used in perception, reconstruction, and robotic manipulation. However, collecting large-scale tactile data remains costly due to the localized nature of sensor-object interactions and inconsistencies across sensor instances. Existing approaches to scaling tactile data, such as simulation and free-form tactile generation, often suffer from unrealistic output and poor transferability to downstream tasks. To address this, we propose ControlTac, a two-stage controllable framework that generates realistic tactile images conditioned on a single reference tactile image, contact force, and contact position. With those physical priors as control input, ControlTac generates physically plausible and varied tactile images that can be used for effective data augmentation. Through experiments on three downstream tasks, we demonstrate that ControlTac can effectively augment tactile datasets and lead to consistent gains. Our three real-world experiments further validate the practical utility of our approach. Project page: https://dongyuluo.github.io/controltac.
Learning to Highlight Audio by Watching Movies
May 17, 2025

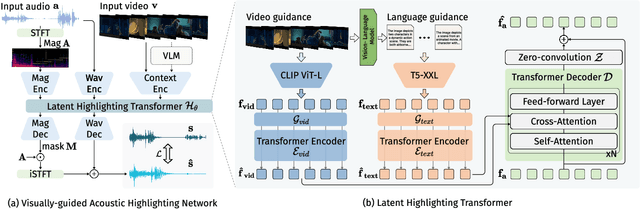
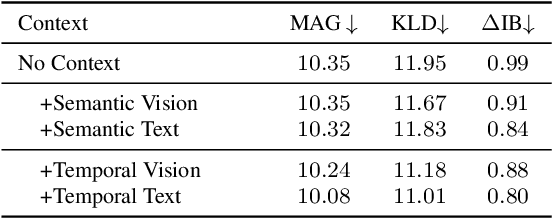
Recent years have seen a significant increase in video content creation and consumption. Crafting engaging content requires the careful curation of both visual and audio elements. While visual cue curation, through techniques like optimal viewpoint selection or post-editing, has been central to media production, its natural counterpart, audio, has not undergone equivalent advancements. This often results in a disconnect between visual and acoustic saliency. To bridge this gap, we introduce a novel task: visually-guided acoustic highlighting, which aims to transform audio to deliver appropriate highlighting effects guided by the accompanying video, ultimately creating a more harmonious audio-visual experience. We propose a flexible, transformer-based multimodal framework to solve this task. To train our model, we also introduce a new dataset -- the muddy mix dataset, leveraging the meticulous audio and video crafting found in movies, which provides a form of free supervision. We develop a pseudo-data generation process to simulate poorly mixed audio, mimicking real-world scenarios through a three-step process -- separation, adjustment, and remixing. Our approach consistently outperforms several baselines in both quantitative and subjective evaluation. We also systematically study the impact of different types of contextual guidance and difficulty levels of the dataset. Our project page is here: https://wikichao.github.io/VisAH/.
Differentiable Room Acoustic Rendering with Multi-View Vision Priors
Apr 30, 2025An immersive acoustic experience enabled by spatial audio is just as crucial as the visual aspect in creating realistic virtual environments. However, existing methods for room impulse response estimation rely either on data-demanding learning-based models or computationally expensive physics-based modeling. In this work, we introduce Audio-Visual Differentiable Room Acoustic Rendering (AV-DAR), a framework that leverages visual cues extracted from multi-view images and acoustic beam tracing for physics-based room acoustic rendering. Experiments across six real-world environments from two datasets demonstrate that our multimodal, physics-based approach is efficient, interpretable, and accurate, significantly outperforming a series of prior methods. Notably, on the Real Acoustic Field dataset, AV-DAR achieves comparable performance to models trained on 10 times more data while delivering relative gains ranging from 16.6% to 50.9% when trained at the same scale.
Hearing Anywhere in Any Environment
Apr 14, 2025In mixed reality applications, a realistic acoustic experience in spatial environments is as crucial as the visual experience for achieving true immersion. Despite recent advances in neural approaches for Room Impulse Response (RIR) estimation, most existing methods are limited to the single environment on which they are trained, lacking the ability to generalize to new rooms with different geometries and surface materials. We aim to develop a unified model capable of reconstructing the spatial acoustic experience of any environment with minimum additional measurements. To this end, we present xRIR, a framework for cross-room RIR prediction. The core of our generalizable approach lies in combining a geometric feature extractor, which captures spatial context from panorama depth images, with a RIR encoder that extracts detailed acoustic features from only a few reference RIR samples. To evaluate our method, we introduce ACOUSTICROOMS, a new dataset featuring high-fidelity simulation of over 300,000 RIRs from 260 rooms. Experiments show that our method strongly outperforms a series of baselines. Furthermore, we successfully perform sim-to-real transfer by evaluating our model on four real-world environments, demonstrating the generalizability of our approach and the realism of our dataset.
Aurelia: Test-time Reasoning Distillation in Audio-Visual LLMs
Mar 29, 2025Recent advancements in reasoning optimization have greatly enhanced the performance of large language models (LLMs). However, existing work fails to address the complexities of audio-visual scenarios, underscoring the need for further research. In this paper, we introduce AURELIA, a novel actor-critic based audio-visual (AV) reasoning framework that distills structured, step-by-step reasoning into AVLLMs at test time, improving their ability to process complex multi-modal inputs without additional training or fine-tuning. To further advance AVLLM reasoning skills, we present AVReasonBench, a challenging benchmark comprising 4500 audio-visual questions, each paired with detailed step-by-step reasoning. Our benchmark spans six distinct tasks, including AV-GeoIQ, which evaluates AV reasoning combined with geographical and cultural knowledge. Evaluating 18 AVLLMs on AVReasonBench reveals significant limitations in their multi-modal reasoning capabilities. Using AURELIA, we achieve up to a 100% relative improvement, demonstrating its effectiveness. This performance gain highlights the potential of reasoning-enhanced data generation for advancing AVLLMs in real-world applications. Our code and data will be publicly released at: https: //github.com/schowdhury671/aurelia.
AVTrustBench: Assessing and Enhancing Reliability and Robustness in Audio-Visual LLMs
Jan 03, 2025



With the rapid advancement of Multi-modal Large Language Models (MLLMs), several diagnostic benchmarks have recently been developed to assess these models' multi-modal reasoning proficiency. However, these benchmarks are restricted to assessing primarily the visual aspect and do not examine the holistic audio-visual (AV) understanding. Moreover, currently, there are no benchmarks that investigate the capabilities of AVLLMs to calibrate their responses when presented with perturbed inputs. To this end, we introduce Audio-Visual Trustworthiness assessment Benchmark (AVTrustBench), comprising 600K samples spanning over 9 meticulously crafted tasks, evaluating the capabilities of AVLLMs across three distinct dimensions: Adversarial attack, Compositional reasoning, and Modality-specific dependency. Using our benchmark we extensively evaluate 13 state-of-the-art AVLLMs. The findings reveal that the majority of existing models fall significantly short of achieving human-like comprehension, offering valuable insights for future research directions. To alleviate the limitations in the existing approaches, we further propose a robust, model-agnostic calibrated audio-visual preference optimization based training strategy CAVPref, obtaining a gain up to 30.19% across all 9 tasks. We will publicly release our code and benchmark to facilitate future research in this direction.
Novel View Acoustic Parameter Estimation
Oct 31, 2024

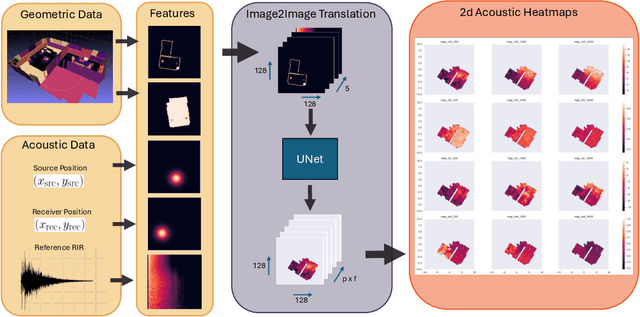
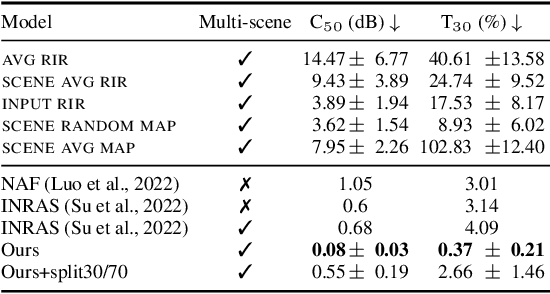
The task of Novel View Acoustic Synthesis (NVAS) - generating Room Impulse Responses (RIRs) for unseen source and receiver positions in a scene - has recently gained traction, especially given its relevance to Augmented Reality (AR) and Virtual Reality (VR) development. However, many of these efforts suffer from similar limitations: they infer RIRs in the time domain, which prove challenging to optimize; they focus on scenes with simple, single-room geometries; they infer only single-channel, directionally-independent acoustic characteristics; and they require inputs, such as 3D geometry meshes with material properties, that may be impractical to obtain for on-device applications. On the other hand, research suggests that sample-wise accuracy of RIRs is not required for perceptual plausibility in AR and VR. Standard acoustic parameters like Clarity Index (C50) or Reverberation Time (T60) have been shown to capably describe pertinent characteristics of the RIRs, especially late reverberation. To address these gaps, this paper introduces a new task centered on estimating spatially distributed acoustic parameters that can be then used to condition a simple reverberator for arbitrary source and receiver positions. The approach is modelled as an image-to-image translation task, which translates 2D floormaps of a scene into 2D heatmaps of acoustic parameters. We introduce a new, large-scale dataset of 1000 scenes consisting of complex, multi-room apartment conditions, and show that our method outperforms statistical baselines significantly. Moreover, we show that the method also works for directionally-dependent (i.e. beamformed) parameter prediction. Finally, the proposed method operates on very limited information, requiring only a broad outline of the scene and a single RIR at inference time.
Spherical World-Locking for Audio-Visual Localization in Egocentric Videos
Aug 09, 2024
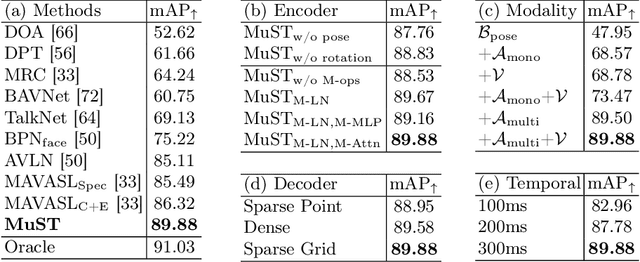


Egocentric videos provide comprehensive contexts for user and scene understanding, spanning multisensory perception to behavioral interaction. We propose Spherical World-Locking (SWL) as a general framework for egocentric scene representation, which implicitly transforms multisensory streams with respect to measurements of head orientation. Compared to conventional head-locked egocentric representations with a 2D planar field-of-view, SWL effectively offsets challenges posed by self-motion, allowing for improved spatial synchronization between input modalities. Using a set of multisensory embeddings on a worldlocked sphere, we design a unified encoder-decoder transformer architecture that preserves the spherical structure of the scene representation, without requiring expensive projections between image and world coordinate systems. We evaluate the effectiveness of the proposed framework on multiple benchmark tasks for egocentric video understanding, including audio-visual active speaker localization, auditory spherical source localization, and behavior anticipation in everyday activities.