 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText-to-Stage: Spatial Layouts from Long-form Narratives
Mar 18, 2026In this work, we probe the ability of a language model to demonstrate spatial reasoning from unstructured text, mimicking human capabilities and automating a process that benefits many downstream media applications. Concretely, we study the narrative-to-play task: inferring stage-play layouts (scenes, speaker positions, movements, and room types) from text that lacks explicit spatial, positional, or relational cues. We then introduce a dramaturgy-inspired deterministic evaluation suite and, finally, a training and inference recipe that combines rejection SFT using Best-of-N sampling with RL from verifiable rewards via GRPO. Experiments on a text-only corpus of classical English literature demonstrate improvements over vanilla models across multiple metrics (character attribution, spatial plausibility, and movement economy), as well as alignment with an LLM-as-a-judge and subjective human preferences.
Hearing Anywhere in Any Environment
Apr 14, 2025In mixed reality applications, a realistic acoustic experience in spatial environments is as crucial as the visual experience for achieving true immersion. Despite recent advances in neural approaches for Room Impulse Response (RIR) estimation, most existing methods are limited to the single environment on which they are trained, lacking the ability to generalize to new rooms with different geometries and surface materials. We aim to develop a unified model capable of reconstructing the spatial acoustic experience of any environment with minimum additional measurements. To this end, we present xRIR, a framework for cross-room RIR prediction. The core of our generalizable approach lies in combining a geometric feature extractor, which captures spatial context from panorama depth images, with a RIR encoder that extracts detailed acoustic features from only a few reference RIR samples. To evaluate our method, we introduce ACOUSTICROOMS, a new dataset featuring high-fidelity simulation of over 300,000 RIRs from 260 rooms. Experiments show that our method strongly outperforms a series of baselines. Furthermore, we successfully perform sim-to-real transfer by evaluating our model on four real-world environments, demonstrating the generalizability of our approach and the realism of our dataset.
Spherical World-Locking for Audio-Visual Localization in Egocentric Videos
Aug 09, 2024
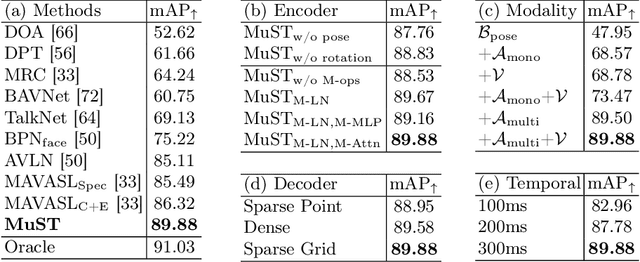


Egocentric videos provide comprehensive contexts for user and scene understanding, spanning multisensory perception to behavioral interaction. We propose Spherical World-Locking (SWL) as a general framework for egocentric scene representation, which implicitly transforms multisensory streams with respect to measurements of head orientation. Compared to conventional head-locked egocentric representations with a 2D planar field-of-view, SWL effectively offsets challenges posed by self-motion, allowing for improved spatial synchronization between input modalities. Using a set of multisensory embeddings on a worldlocked sphere, we design a unified encoder-decoder transformer architecture that preserves the spherical structure of the scene representation, without requiring expensive projections between image and world coordinate systems. We evaluate the effectiveness of the proposed framework on multiple benchmark tasks for egocentric video understanding, including audio-visual active speaker localization, auditory spherical source localization, and behavior anticipation in everyday activities.
Egocentric Deep Multi-Channel Audio-Visual Active Speaker Localization
Jan 06, 2022
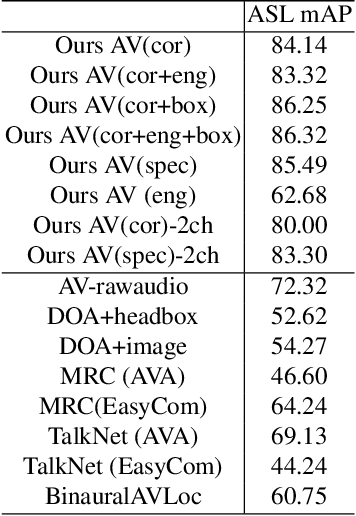
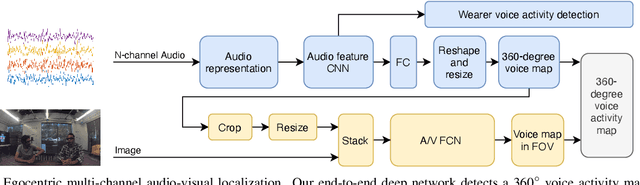
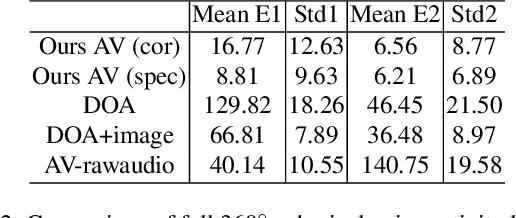
Augmented reality devices have the potential to enhance human perception and enable other assistive functionalities in complex conversational environments. Effectively capturing the audio-visual context necessary for understanding these social interactions first requires detecting and localizing the voice activities of the device wearer and the surrounding people. These tasks are challenging due to their egocentric nature: the wearer's head motion may cause motion blur, surrounding people may appear in difficult viewing angles, and there may be occlusions, visual clutter, audio noise, and bad lighting. Under these conditions, previous state-of-the-art active speaker detection methods do not give satisfactory results. Instead, we tackle the problem from a new setting using both video and multi-channel microphone array audio. We propose a novel end-to-end deep learning approach that is able to give robust voice activity detection and localization results. In contrast to previous methods, our method localizes active speakers from all possible directions on the sphere, even outside the camera's field of view, while simultaneously detecting the device wearer's own voice activity. Our experiments show that the proposed method gives superior results, can run in real time, and is robust against noise and clutter.
Reframing Neural Networks: Deep Structure in Overcomplete Representations
Mar 10, 2021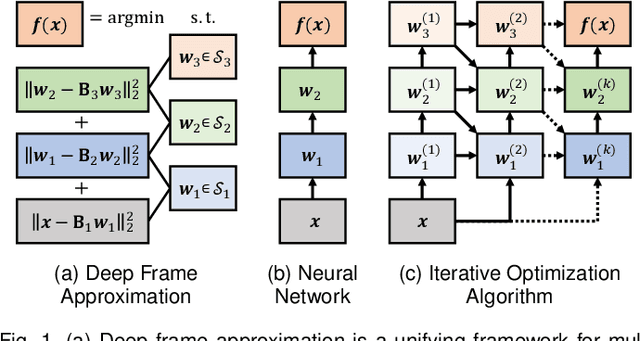

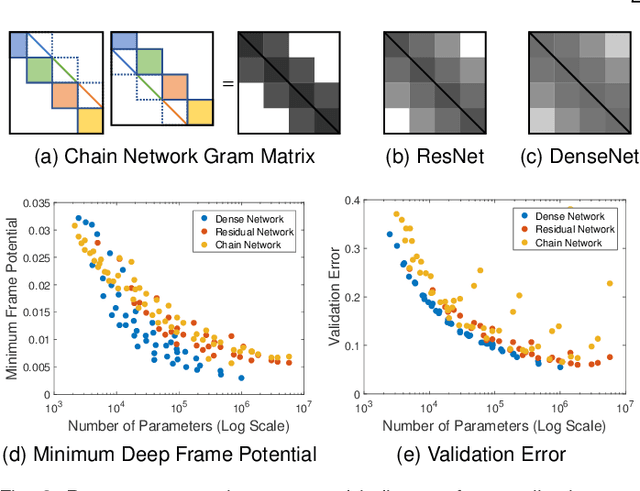
In comparison to classical shallow representation learning techniques, deep neural networks have achieved superior performance in nearly every application benchmark. But despite their clear empirical advantages, it is still not well understood what makes them so effective. To approach this question, we introduce deep frame approximation, a unifying framework for representation learning with structured overcomplete frames. While exact inference requires iterative optimization, it may be approximated by the operations of a feed-forward deep neural network. We then indirectly analyze how model capacity relates to the frame structure induced by architectural hyperparameters such as depth, width, and skip connections. We quantify these structural differences with the deep frame potential, a data-independent measure of coherence linked to representation uniqueness and stability. As a criterion for model selection, we show correlation with generalization error on a variety of common deep network architectures such as ResNets and DenseNets. We also demonstrate how recurrent networks implementing iterative optimization algorithms achieve performance comparable to their feed-forward approximations. This connection to the established theory of overcomplete representations suggests promising new directions for principled deep network architecture design with less reliance on ad-hoc engineering.
Architectural Adversarial Robustness: The Case for Deep Pursuit
Nov 29, 2020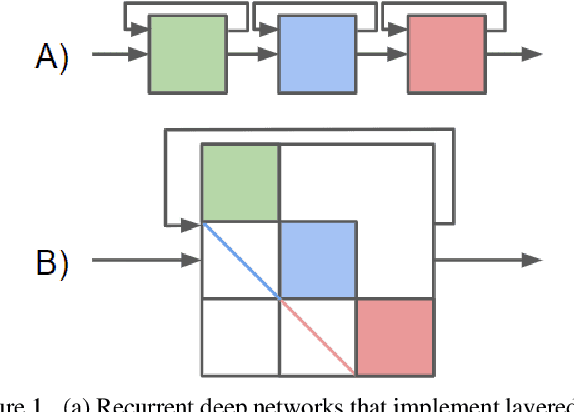

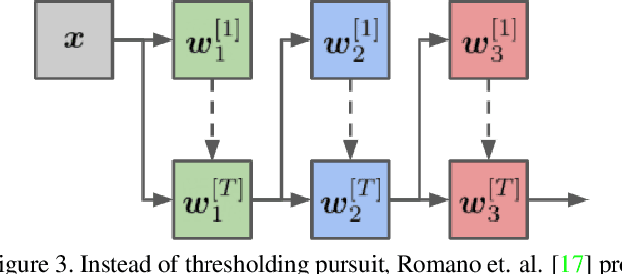
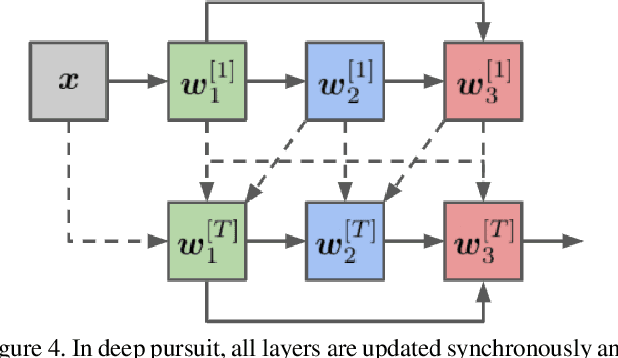
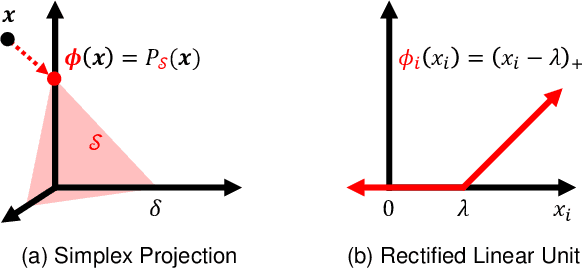
Despite their unmatched performance, deep neural networks remain susceptible to targeted attacks by nearly imperceptible levels of adversarial noise. While the underlying cause of this sensitivity is not well understood, theoretical analyses can be simplified by reframing each layer of a feed-forward network as an approximate solution to a sparse coding problem. Iterative solutions using basis pursuit are theoretically more stable and have improved adversarial robustness. However, cascading layer-wise pursuit implementations suffer from error accumulation in deeper networks. In contrast, our new method of deep pursuit approximates the activations of all layers as a single global optimization problem, allowing us to consider deeper, real-world architectures with skip connections such as residual networks. Experimentally, our approach demonstrates improved robustness to adversarial noise.
Dataless Model Selection with the Deep Frame Potential
Mar 30, 2020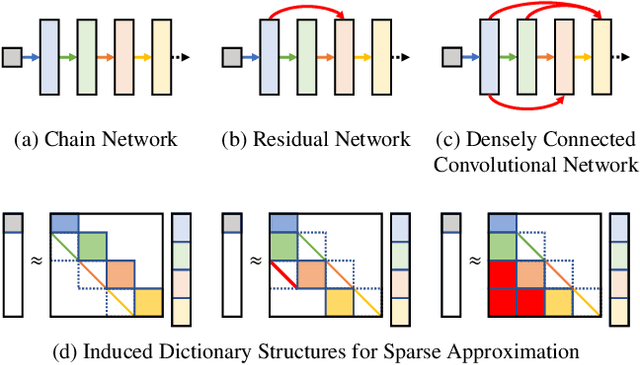
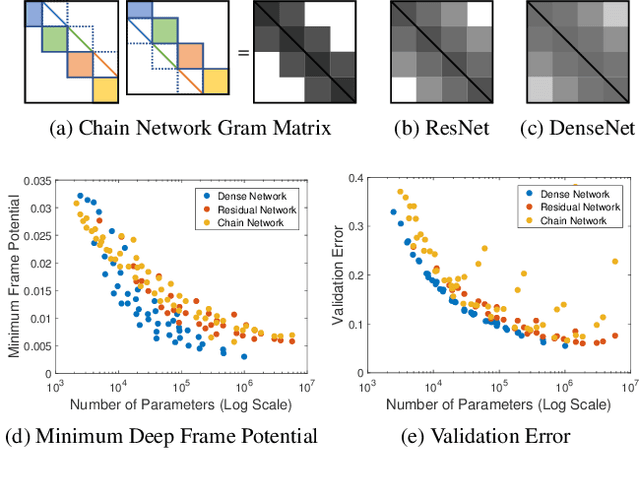

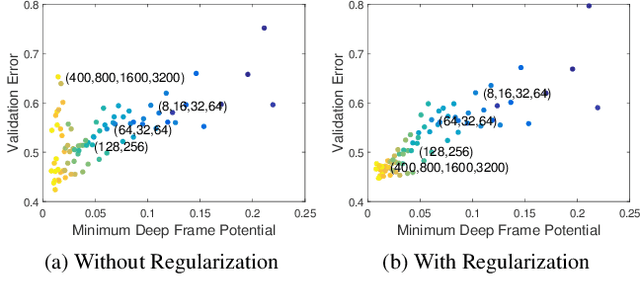
Choosing a deep neural network architecture is a fundamental problem in applications that require balancing performance and parameter efficiency. Standard approaches rely on ad-hoc engineering or computationally expensive validation on a specific dataset. We instead attempt to quantify networks by their intrinsic capacity for unique and robust representations, enabling efficient architecture comparisons without requiring any data. Building upon theoretical connections between deep learning and sparse approximation, we propose the deep frame potential: a measure of coherence that is approximately related to representation stability but has minimizers that depend only on network structure. This provides a framework for jointly quantifying the contributions of architectural hyper-parameters such as depth, width, and skip connections. We validate its use as a criterion for model selection and demonstrate correlation with generalization error on a variety of common residual and densely connected network architectures.
Deep Component Analysis via Alternating Direction Neural Networks
Mar 16, 2018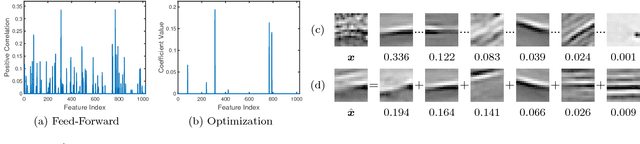
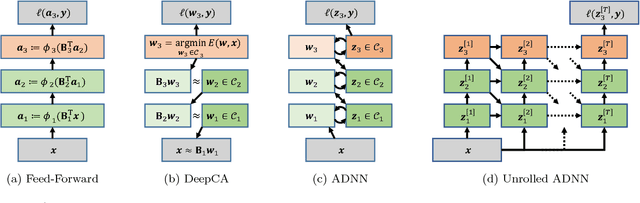
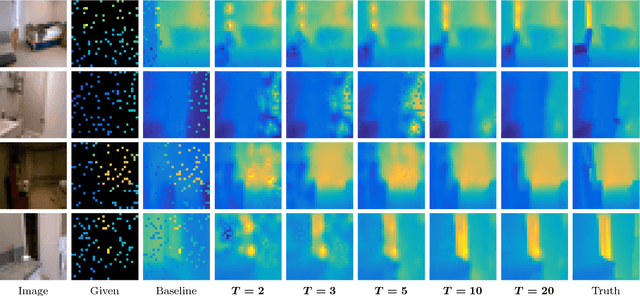
Despite a lack of theoretical understanding, deep neural networks have achieved unparalleled performance in a wide range of applications. On the other hand, shallow representation learning with component analysis is associated with rich intuition and theory, but smaller capacity often limits its usefulness. To bridge this gap, we introduce Deep Component Analysis (DeepCA), an expressive multilayer model formulation that enforces hierarchical structure through constraints on latent variables in each layer. For inference, we propose a differentiable optimization algorithm implemented using recurrent Alternating Direction Neural Networks (ADNNs) that enable parameter learning using standard backpropagation. By interpreting feed-forward networks as single-iteration approximations of inference in our model, we provide both a novel theoretical perspective for understanding them and a practical technique for constraining predictions with prior knowledge. Experimentally, we demonstrate performance improvements on a variety of tasks, including single-image depth prediction with sparse output constraints.
Blockout: Dynamic Model Selection for Hierarchical Deep Networks
Dec 16, 2015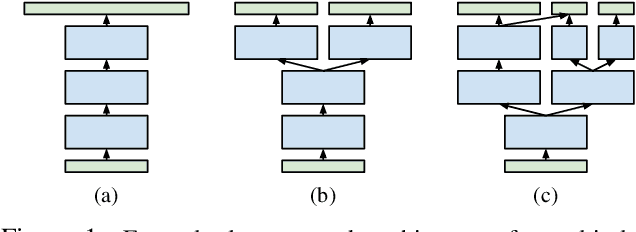
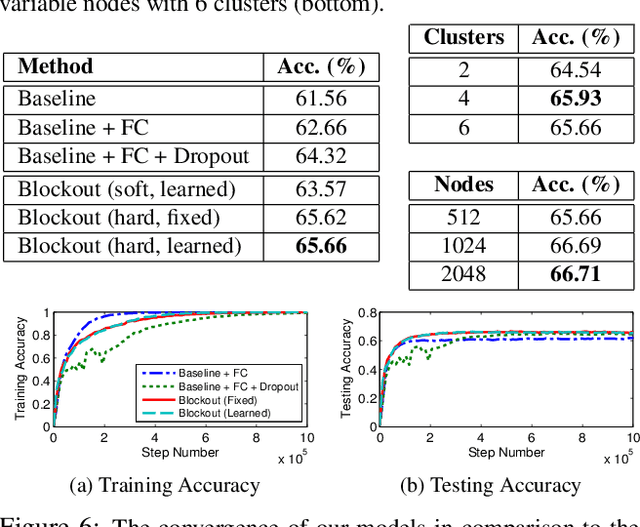
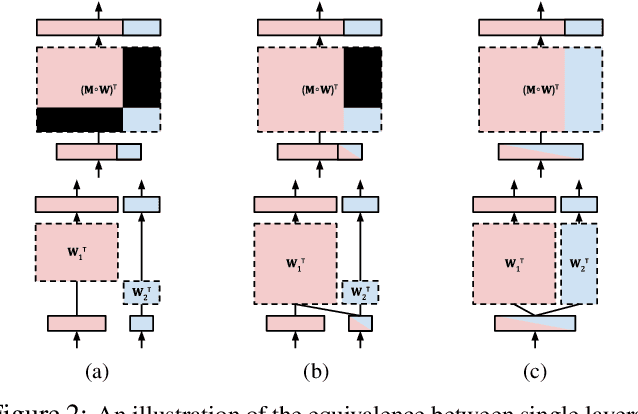
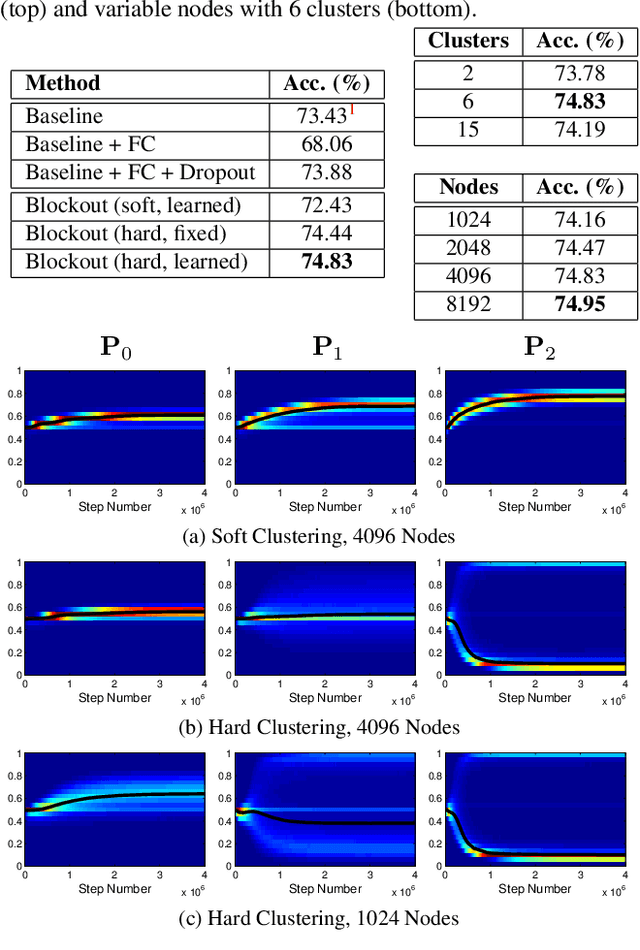
Most deep architectures for image classification--even those that are trained to classify a large number of diverse categories--learn shared image representations with a single model. Intuitively, however, categories that are more similar should share more information than those that are very different. While hierarchical deep networks address this problem by learning separate features for subsets of related categories, current implementations require simplified models using fixed architectures specified via heuristic clustering methods. Instead, we propose Blockout, a method for regularization and model selection that simultaneously learns both the model architecture and parameters. A generalization of Dropout, our approach gives a novel parametrization of hierarchical architectures that allows for structure learning via back-propagation. To demonstrate its utility, we evaluate Blockout on the CIFAR and ImageNet datasets, demonstrating improved classification accuracy, better regularization performance, faster training, and the clear emergence of hierarchical network structures.