 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini Embedding: Generalizable Embeddings from Gemini
Mar 10, 2025In this report, we introduce Gemini Embedding, a state-of-the-art embedding model leveraging the power of Gemini, Google's most capable large language model. Capitalizing on Gemini's inherent multilingual and code understanding capabilities, Gemini Embedding produces highly generalizable embeddings for text spanning numerous languages and textual modalities. The representations generated by Gemini Embedding can be precomputed and applied to a variety of downstream tasks including classification, similarity, clustering, ranking, and retrieval. Evaluated on the Massive Multilingual Text Embedding Benchmark (MMTEB), which includes over one hundred tasks across 250+ languages, Gemini Embedding substantially outperforms prior state-of-the-art models, demonstrating considerable improvements in embedding quality. Achieving state-of-the-art performance across MMTEB's multilingual, English, and code benchmarks, our unified model demonstrates strong capabilities across a broad selection of tasks and surpasses specialized domain-specific models.
Modeling Collaborator: Enabling Subjective Vision Classification With Minimal Human Effort via LLM Tool-Use
Mar 05, 2024From content moderation to wildlife conservation, the number of applications that require models to recognize nuanced or subjective visual concepts is growing. Traditionally, developing classifiers for such concepts requires substantial manual effort measured in hours, days, or even months to identify and annotate data needed for training. Even with recently proposed Agile Modeling techniques, which enable rapid bootstrapping of image classifiers, users are still required to spend 30 minutes or more of monotonous, repetitive data labeling just to train a single classifier. Drawing on Fiske's Cognitive Miser theory, we propose a new framework that alleviates manual effort by replacing human labeling with natural language interactions, reducing the total effort required to define a concept by an order of magnitude: from labeling 2,000 images to only 100 plus some natural language interactions. Our framework leverages recent advances in foundation models, both large language models and vision-language models, to carve out the concept space through conversation and by automatically labeling training data points. Most importantly, our framework eliminates the need for crowd-sourced annotations. Moreover, our framework ultimately produces lightweight classification models that are deployable in cost-sensitive scenarios. Across 15 subjective concepts and across 2 public image classification datasets, our trained models outperform traditional Agile Modeling as well as state-of-the-art zero-shot classification models like ALIGN, CLIP, CuPL, and large visual question-answering models like PaLI-X.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
CARLS: Cross-platform Asynchronous Representation Learning System
May 26, 2021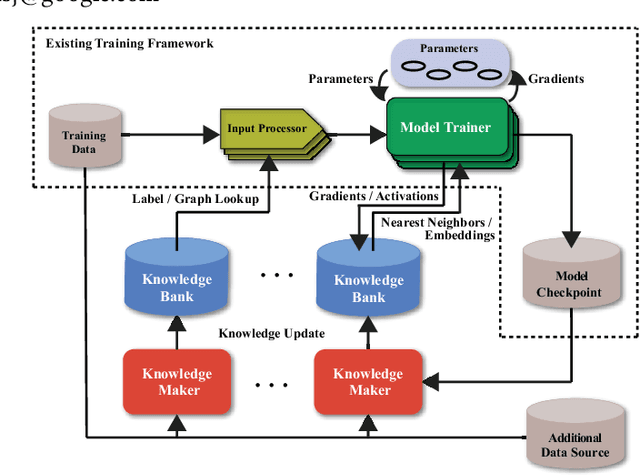
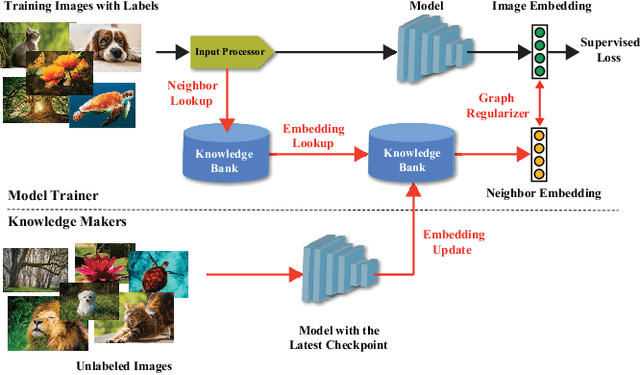
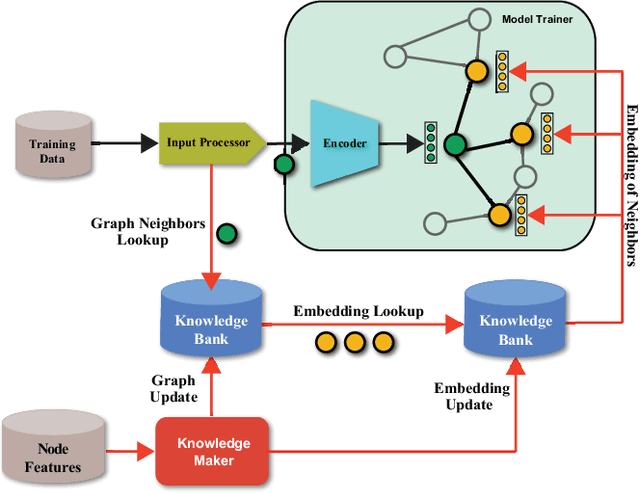
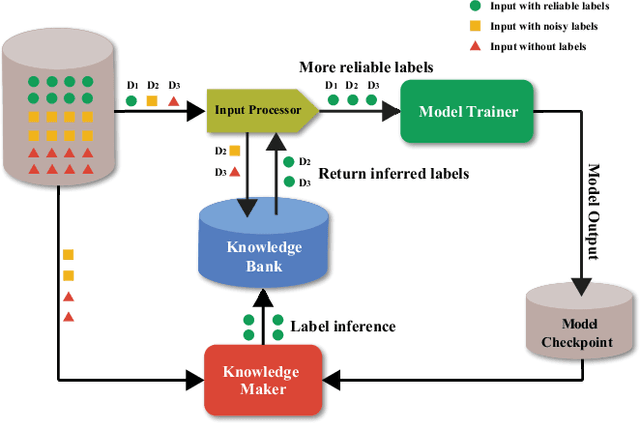
In this work, we propose CARLS, a novel framework for augmenting the capacity of existing deep learning frameworks by enabling multiple components -- model trainers, knowledge makers and knowledge banks -- to concertedly work together in an asynchronous fashion across hardware platforms. The proposed CARLS is particularly suitable for learning paradigms where model training benefits from additional knowledge inferred or discovered during training, such as node embeddings for graph neural networks or reliable pseudo labels from model predictions. We also describe three learning paradigms -- semi-supervised learning, curriculum learning and multimodal learning -- as examples that can be scaled up efficiently by CARLS. One version of CARLS has been open-sourced and available for download at: https://github.com/tensorflow/neural-structured-learning/tree/master/research/carls
Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision
Feb 11, 2021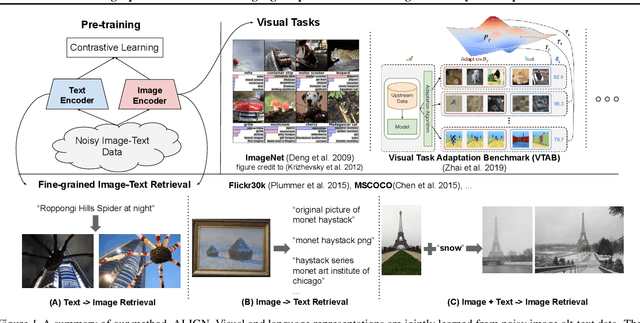
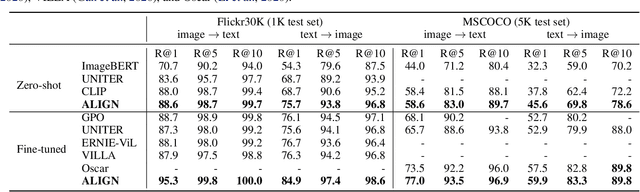


Pre-trained representations are becoming crucial for many NLP and perception tasks. While representation learning in NLP has transitioned to training on raw text without human annotations, visual and vision-language representations still rely heavily on curated training datasets that are expensive or require expert knowledge. For vision applications, representations are mostly learned using datasets with explicit class labels such as ImageNet or OpenImages. For vision-language, popular datasets like Conceptual Captions, MSCOCO, or CLIP all involve a non-trivial data collection (and cleaning) process. This costly curation process limits the size of datasets and hence hinders the scaling of trained models. In this paper, we leverage a noisy dataset of over one billion image alt-text pairs, obtained without expensive filtering or post-processing steps in the Conceptual Captions dataset. A simple dual-encoder architecture learns to align visual and language representations of the image and text pairs using a contrastive loss. We show that the scale of our corpus can make up for its noise and leads to state-of-the-art representations even with such a simple learning scheme. Our visual representation achieves strong performance when transferred to classification tasks such as ImageNet and VTAB. The aligned visual and language representations also set new state-of-the-art results on Flickr30K and MSCOCO benchmarks, even when compared with more sophisticated cross-attention models. The representations also enable cross-modality search with complex text and text + image queries.
Unifying Specialist Image Embedding into Universal Image Embedding
Mar 08, 2020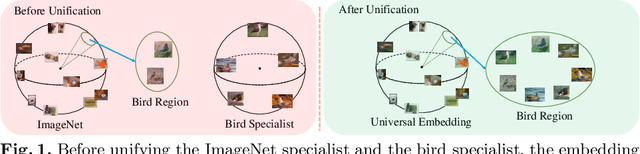
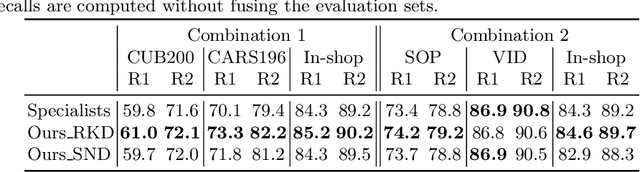

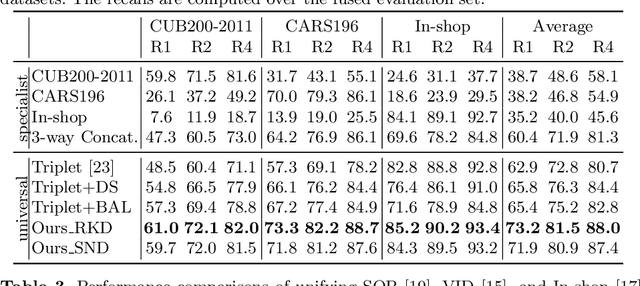
Deep image embedding provides a way to measure the semantic similarity of two images. It plays a central role in many applications such as image search, face verification, and zero-shot learning. It is desirable to have a universal deep embedding model applicable to various domains of images. However, existing methods mainly rely on training specialist embedding models each of which is applicable to images from a single domain. In this paper, we study an important but unexplored task: how to train a single universal image embedding model to match the performance of several specialists on each specialist's domain. Simply fusing the training data from multiple domains cannot solve this problem because some domains become overfitted sooner when trained together using existing methods. Therefore, we propose to distill the knowledge in multiple specialists into a universal embedding to solve this problem. In contrast to existing embedding distillation methods that distill the absolute distances between images, we transform the absolute distances between images into a probabilistic distribution and minimize the KL-divergence between the distributions of the specialists and the universal embedding. Using several public datasets, we validate that our proposed method accomplishes the goal of universal image embedding.
Graph-RISE: Graph-Regularized Image Semantic Embedding
Feb 14, 2019

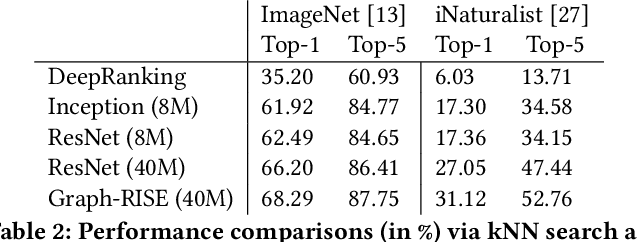
Learning image representations to capture fine-grained semantics has been a challenging and important task enabling many applications such as image search and clustering. In this paper, we present Graph-Regularized Image Semantic Embedding (Graph-RISE), a large-scale neural graph learning framework that allows us to train embeddings to discriminate an unprecedented O(40M) ultra-fine-grained semantic labels. Graph-RISE outperforms state-of-the-art image embedding algorithms on several evaluation tasks, including image classification and triplet ranking. We provide case studies to demonstrate that, qualitatively, image retrieval based on Graph-RISE effectively captures semantics and, compared to the state-of-the-art, differentiates nuances at levels that are closer to human-perception.
The Open Images Dataset V4: Unified image classification, object detection, and visual relationship detection at scale
Nov 02, 2018


We present Open Images V4, a dataset of 9.2M images with unified annotations for image classification, object detection and visual relationship detection. The images have a Creative Commons Attribution license that allows to share and adapt the material, and they have been collected from Flickr without a predefined list of class names or tags, leading to natural class statistics and avoiding an initial design bias. Open Images V4 offers large scale across several dimensions: 30.1M image-level labels for 19.8k concepts, 15.4M bounding boxes for 600 object classes, and 375k visual relationship annotations involving 57 classes. For object detection in particular, we provide 15x more bounding boxes than the next largest datasets (15.4M boxes on 1.9M images). The images often show complex scenes with several objects (8 annotated objects per image on average). We annotated visual relationships between them, which support visual relationship detection, an emerging task that requires structured reasoning. We provide in-depth comprehensive statistics about the dataset, we validate the quality of the annotations, and we study how the performance of many modern models evolves with increasing amounts of training data. We hope that the scale, quality, and variety of Open Images V4 will foster further research and innovation even beyond the areas of image classification, object detection, and visual relationship detection.
The Unreasonable Effectiveness of Noisy Data for Fine-Grained Recognition
Oct 18, 2016
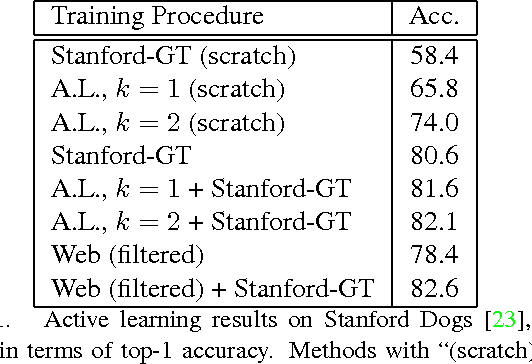

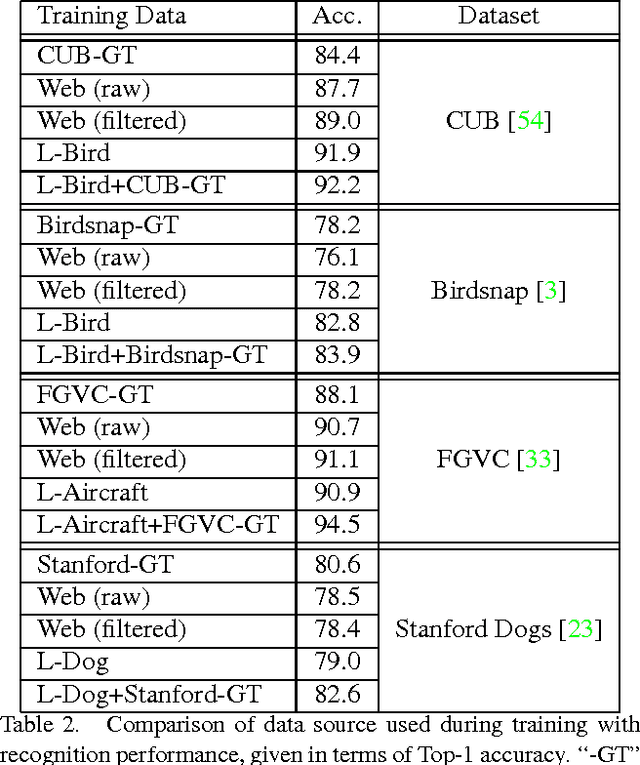
Current approaches for fine-grained recognition do the following: First, recruit experts to annotate a dataset of images, optionally also collecting more structured data in the form of part annotations and bounding boxes. Second, train a model utilizing this data. Toward the goal of solving fine-grained recognition, we introduce an alternative approach, leveraging free, noisy data from the web and simple, generic methods of recognition. This approach has benefits in both performance and scalability. We demonstrate its efficacy on four fine-grained datasets, greatly exceeding existing state of the art without the manual collection of even a single label, and furthermore show first results at scaling to more than 10,000 fine-grained categories. Quantitatively, we achieve top-1 accuracies of 92.3% on CUB-200-2011, 85.4% on Birdsnap, 93.4% on FGVC-Aircraft, and 80.8% on Stanford Dogs without using their annotated training sets. We compare our approach to an active learning approach for expanding fine-grained datasets.
Blockout: Dynamic Model Selection for Hierarchical Deep Networks
Dec 16, 2015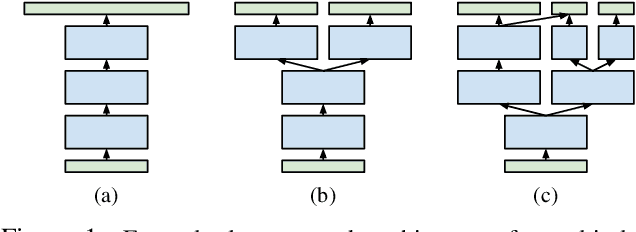
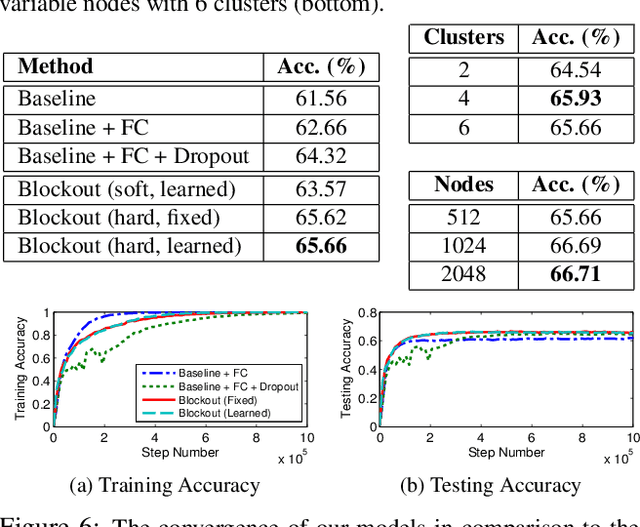
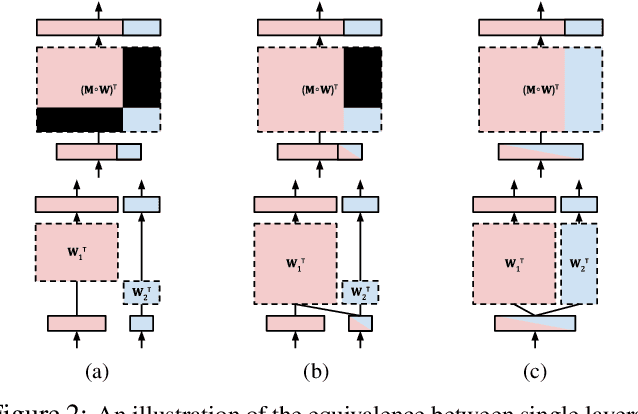
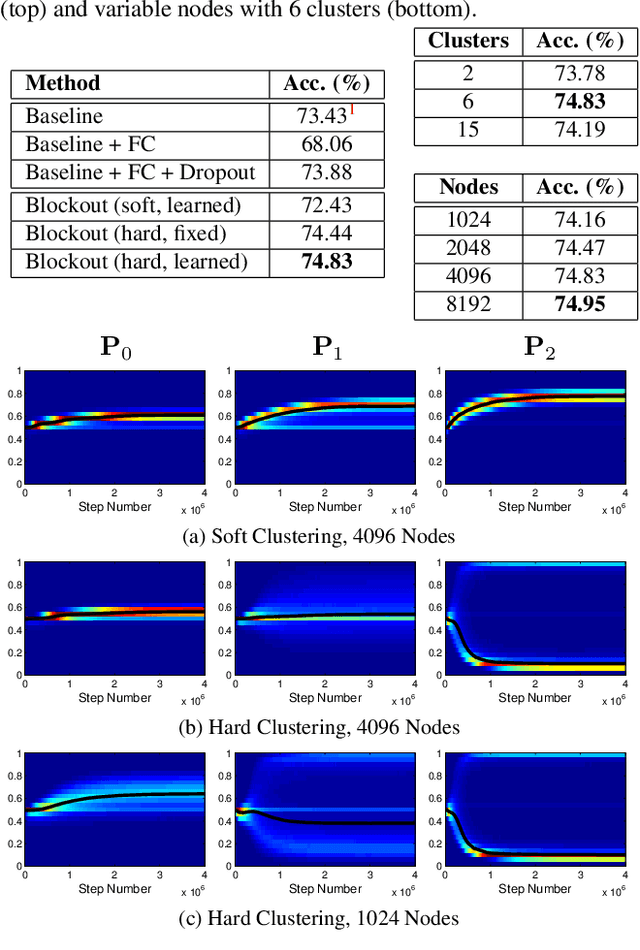
Most deep architectures for image classification--even those that are trained to classify a large number of diverse categories--learn shared image representations with a single model. Intuitively, however, categories that are more similar should share more information than those that are very different. While hierarchical deep networks address this problem by learning separate features for subsets of related categories, current implementations require simplified models using fixed architectures specified via heuristic clustering methods. Instead, we propose Blockout, a method for regularization and model selection that simultaneously learns both the model architecture and parameters. A generalization of Dropout, our approach gives a novel parametrization of hierarchical architectures that allows for structure learning via back-propagation. To demonstrate its utility, we evaluate Blockout on the CIFAR and ImageNet datasets, demonstrating improved classification accuracy, better regularization performance, faster training, and the clear emergence of hierarchical network structures.