 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEAGULL: No-reference Image Quality Assessment for Regions of Interest via Vision-Language Instruction Tuning
Nov 15, 2024



Existing Image Quality Assessment (IQA) methods achieve remarkable success in analyzing quality for overall image, but few works explore quality analysis for Regions of Interest (ROIs). The quality analysis of ROIs can provide fine-grained guidance for image quality improvement and is crucial for scenarios focusing on region-level quality. This paper proposes a novel network, SEAGULL, which can SEe and Assess ROIs quality with GUidance from a Large vision-Language model. SEAGULL incorporates a vision-language model (VLM), masks generated by Segment Anything Model (SAM) to specify ROIs, and a meticulously designed Mask-based Feature Extractor (MFE) to extract global and local tokens for specified ROIs, enabling accurate fine-grained IQA for ROIs. Moreover, this paper constructs two ROI-based IQA datasets, SEAGULL-100w and SEAGULL-3k, for training and evaluating ROI-based IQA. SEAGULL-100w comprises about 100w synthetic distortion images with 33 million ROIs for pre-training to improve the model's ability of regional quality perception, and SEAGULL-3k contains about 3k authentic distortion ROIs to enhance the model's ability to perceive real world distortions. After pre-training on SEAGULL-100w and fine-tuning on SEAGULL-3k, SEAGULL shows remarkable performance on fine-grained ROI quality assessment. Code and datasets are publicly available at the https://github.com/chencn2020/Seagull.
MobileIQA: Exploiting Mobile-level Diverse Opinion Network For No-Reference Image Quality Assessment Using Knowledge Distillation
Sep 02, 2024With the rising demand for high-resolution (HR) images, No-Reference Image Quality Assessment (NR-IQA) gains more attention, as it can ecaluate image quality in real-time on mobile devices and enhance user experience. However, existing NR-IQA methods often resize or crop the HR images into small resolution, which leads to a loss of important details. And most of them are of high computational complexity, which hinders their application on mobile devices due to limited computational resources. To address these challenges, we propose MobileIQA, a novel approach that utilizes lightweight backbones to efficiently assess image quality while preserving image details through high-resolution input. MobileIQA employs the proposed multi-view attention learning (MAL) module to capture diverse opinions, simulating subjective opinions provided by different annotators during the dataset annotation process. The model uses a teacher model to guide the learning of a student model through knowledge distillation. This method significantly reduces computational complexity while maintaining high performance. Experiments demonstrate that MobileIQA outperforms novel IQA methods on evaluation metrics and computational efficiency. The code is available at https://github.com/chencn2020/MobileIQA.
CARLS: Cross-platform Asynchronous Representation Learning System
May 26, 2021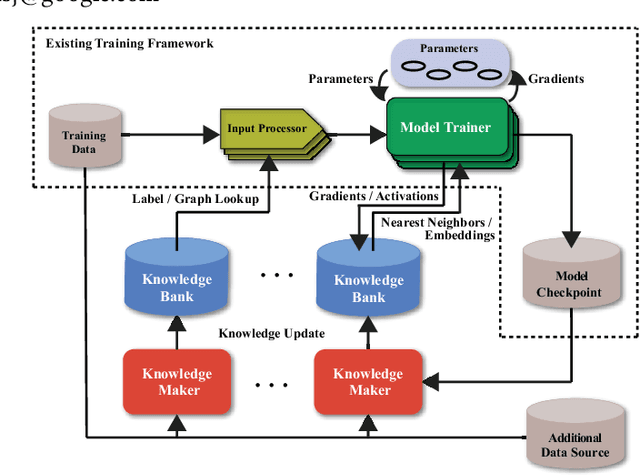
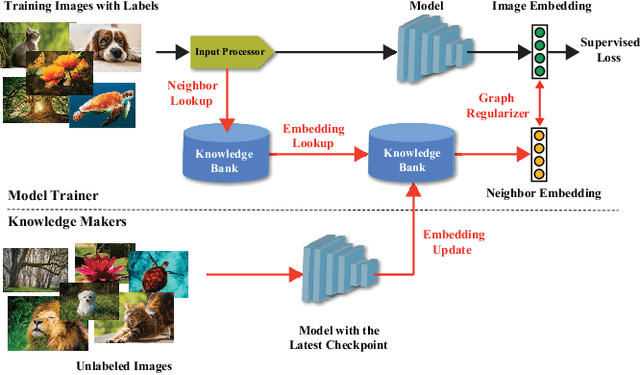
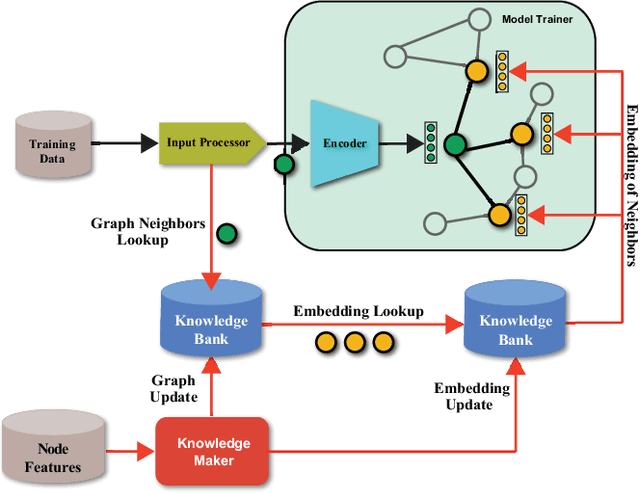
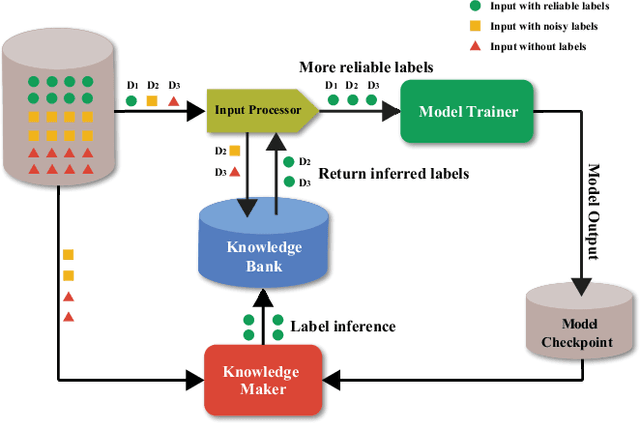
In this work, we propose CARLS, a novel framework for augmenting the capacity of existing deep learning frameworks by enabling multiple components -- model trainers, knowledge makers and knowledge banks -- to concertedly work together in an asynchronous fashion across hardware platforms. The proposed CARLS is particularly suitable for learning paradigms where model training benefits from additional knowledge inferred or discovered during training, such as node embeddings for graph neural networks or reliable pseudo labels from model predictions. We also describe three learning paradigms -- semi-supervised learning, curriculum learning and multimodal learning -- as examples that can be scaled up efficiently by CARLS. One version of CARLS has been open-sourced and available for download at: https://github.com/tensorflow/neural-structured-learning/tree/master/research/carls
DynamicEmbedding: Extending TensorFlow for Colossal-Scale Applications
Apr 17, 2020
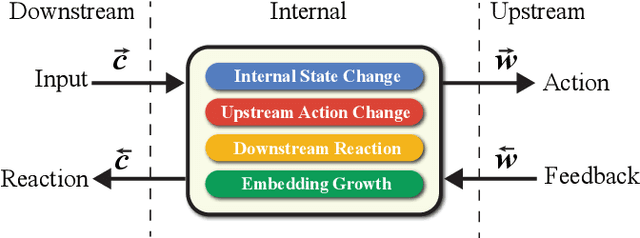

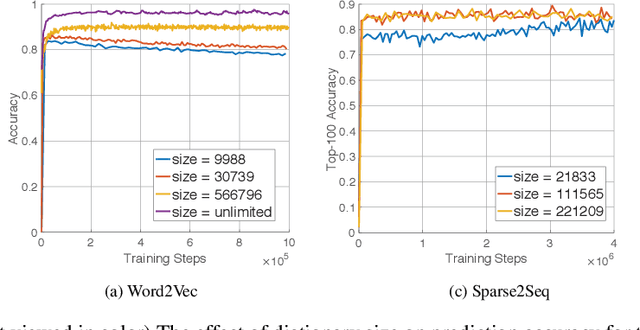
One of the limitations of deep learning models with sparse features today stems from the predefined nature of their input, which requires a dictionary be defined prior to the training. With this paper we propose both a theory and a working system design which remove this limitation, and show that the resulting models are able to perform better and efficiently run at a much larger scale. Specifically, we achieve this by decoupling a model's content from its form to tackle architecture evolution and memory growth separately. To efficiently handle model growth, we propose a new neuron model, called DynamicCell, drawing inspiration from from the free energy principle [15] to introduce the concept of reaction to discharge non-digestive energy, which also subsumes gradient descent based approaches as its special cases. We implement DynamicCell by introducing a new server into TensorFlow to take over most of the work involving model growth. Consequently, it enables any existing deep learning models to efficiently handle arbitrary number of distinct sparse features (e.g., search queries), and grow incessantly without redefining the model. Most notably, one of our models, which has been reliably running in production for over a year, is capable of suggesting high quality keywords for advertisers of Google Smart Campaigns and achieved significant accuracy gains based on a challenging metric -- evidence that data-driven, self-evolving systems can potentially exceed the performance of traditional rule-based approaches.
Context Aware Machine Learning
Jan 19, 2019



We propose a principle for exploring context in machine learning models. Starting with a simple assumption that each observation may or may not depend on its context, a conditional probability distribution is decomposed into two parts: context-free and context-sensitive. Then by employing the log-linear word production model for relating random variables to their embedding space representation and making use of the convexity of natural exponential function, we show that the embedding of an observation can also be decomposed into a weighted sum of two vectors, representing its context-free and context-sensitive parts, respectively. This simple treatment of context provides a unified view of many existing deep learning models, leading to revisions of these models able to achieve significant performance boost. Specifically, our upgraded version of a recent sentence embedding model not only outperforms the original one by a large margin, but also leads to a new, principled approach for compositing the embeddings of bag-of-words features, as well as a new architecture for modeling attention in deep neural networks. More surprisingly, our new principle provides a novel understanding of the gates and equations defined by the long short term memory model, which also leads to a new model that is able to converge significantly faster and achieve much lower prediction errors. Furthermore, our principle also inspires a new type of generic neural network layer that better resembles real biological neurons than the traditional linear mapping plus nonlinear activation based architecture. Its multi-layer extension provides a new principle for deep neural networks which subsumes residual network (ResNet) as its special case, and its extension to convolutional neutral network model accounts for irrelevant input (e.g., background in an image) in addition to filtering.