 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLight-WAM: Efficient World Action Models with State-Fusion Action Decoding
Jun 06, 2026World Action Models (WAMs) extend robot policy learning by incorporating future prediction as an additional training objective, encouraging the policy to encode task-relevant temporal structure in its representations. Current WAMs often rely on large-scale generative architectures that incur high training costs and inference latency, making them difficult to deploy as efficient closed-loop policies. We propose Light-WAM, a lightweight World Action Model for efficient robot manipulation. Specifically, it is built with a compact video backbone and performs future-video supervision in a downsampled latent space, reducing the cost of video co-training while retaining its benefits for representation learning. For action prediction, Light-WAM introduces the StateFusionActionExpert, which reads adapted states from multiple backbone layers, fuses them through learned-query pooling, and directly predicts action chunks in a single forward pass. This design provides an efficient interface between video backbone representations and robot actions, avoiding the need for heavy generative action experts. Experiments demonstrate that Light-WAM maintains strong performance on LIBERO and achieves usable multi-task performance on RoboTwin 2.0, while using only 0.44B trainable parameters. It also achieves 72.03ms inference latency with 4.1GiB peak GPU memory and improved training throughput.
NTIRE 2026 The 3rd Restore Any Image Model (RAIM) Challenge: Professional Image Quality Assessment (Track 1)
Apr 14, 2026In this paper, we present an overview of the NTIRE 2026 challenge on the 3rd Restore Any Image Model in the Wild, specifically focusing on Track 1: Professional Image Quality Assessment. Conventional Image Quality Assessment (IQA) typically relies on scalar scores. By compressing complex visual characteristics into a single number, these methods fundamentally struggle to distinguish subtle differences among uniformly high-quality images. Furthermore, they fail to articulate why one image is superior, lacking the reasoning capabilities required to provide guidance for vision tasks. To bridge this gap, recent advancements in Multimodal Large Language Models (MLLMs) offer a promising paradigm. Inspired by this potential, our challenge establishes a novel benchmark exploring the ability of MLLMs to mimic human expert cognition in evaluating high-quality image pairs. Participants were tasked with overcoming critical bottlenecks in professional scenarios, centering on two primary objectives: (1) Comparative Quality Selection: reliably identifying the visually superior image within a high-quality pair; and (2) Interpretative Reasoning: generating grounded, expert-level explanations that detail the rationale behind the selection. In total, the challenge attracted nearly 200 registrations and over 2,500 submissions. The top-performing methods significantly advanced the state of the art in professional IQA. The challenge dataset is available at https://github.com/narthchin/RAIM-PIQA, and the official homepage is accessible at https://www.codabench.org/competitions/12789/.
AgentSentry: Mitigating Indirect Prompt Injection in LLM Agents via Temporal Causal Diagnostics and Context Purification
Feb 26, 2026Large language model (LLM) agents increasingly rely on external tools and retrieval systems to autonomously complete complex tasks. However, this design exposes agents to indirect prompt injection (IPI), where attacker-controlled context embedded in tool outputs or retrieved content silently steers agent actions away from user intent. Unlike prompt-based attacks, IPI unfolds over multi-turn trajectories, making malicious control difficult to disentangle from legitimate task execution. Existing inference-time defenses primarily rely on heuristic detection and conservative blocking of high-risk actions, which can prematurely terminate workflows or broadly suppress tool usage under ambiguous multi-turn scenarios. We propose AgentSentry, a novel inference-time detection and mitigation framework for tool-augmented LLM agents. To the best of our knowledge, AgentSentry is the first inference-time defense to model multi-turn IPI as a temporal causal takeover. It localizes takeover points via controlled counterfactual re-executions at tool-return boundaries and enables safe continuation through causally guided context purification that removes attack-induced deviations while preserving task-relevant evidence. We evaluate AgentSentry on the \textsc{AgentDojo} benchmark across four task suites, three IPI attack families, and multiple black-box LLMs. AgentSentry eliminates successful attacks and maintains strong utility under attack, achieving an average Utility Under Attack (UA) of 74.55 %, improving UA by 20.8 to 33.6 percentage points over the strongest baselines without degrading benign performance.
LLM-as-a-Supervisor: Mistaken Therapeutic Behaviors Trigger Targeted Supervisory Feedback
Aug 12, 2025



Although large language models (LLMs) hold significant promise in psychotherapy, their direct application in patient-facing scenarios raises ethical and safety concerns. Therefore, this work shifts towards developing an LLM as a supervisor to train real therapists. In addition to the privacy of clinical therapist training data, a fundamental contradiction complicates the training of therapeutic behaviors: clear feedback standards are necessary to ensure a controlled training system, yet there is no absolute "gold standard" for appropriate therapeutic behaviors in practice. In contrast, many common therapeutic mistakes are universal and identifiable, making them effective triggers for targeted feedback that can serve as clearer evidence. Motivated by this, we create a novel therapist-training paradigm: (1) guidelines for mistaken behaviors and targeted correction strategies are first established as standards; (2) a human-in-the-loop dialogue-feedback dataset is then constructed, where a mistake-prone agent intentionally makes standard mistakes during interviews naturally, and a supervisor agent locates and identifies mistakes and provides targeted feedback; (3) after fine-tuning on this dataset, the final supervisor model is provided for real therapist training. The detailed experimental results of automated, human and downstream assessments demonstrate that models fine-tuned on our dataset MATE, can provide high-quality feedback according to the clinical guideline, showing significant potential for the therapist training scenario.
NTIRE 2025 challenge on Text to Image Generation Model Quality Assessment
May 22, 2025This paper reports on the NTIRE 2025 challenge on Text to Image (T2I) generation model quality assessment, which will be held in conjunction with the New Trends in Image Restoration and Enhancement Workshop (NTIRE) at CVPR 2025. The aim of this challenge is to address the fine-grained quality assessment of text-to-image generation models. This challenge evaluates text-to-image models from two aspects: image-text alignment and image structural distortion detection, and is divided into the alignment track and the structural track. The alignment track uses the EvalMuse-40K, which contains around 40K AI-Generated Images (AIGIs) generated by 20 popular generative models. The alignment track has a total of 371 registered participants. A total of 1,883 submissions are received in the development phase, and 507 submissions are received in the test phase. Finally, 12 participating teams submitted their models and fact sheets. The structure track uses the EvalMuse-Structure, which contains 10,000 AI-Generated Images (AIGIs) with corresponding structural distortion mask. A total of 211 participants have registered in the structure track. A total of 1155 submissions are received in the development phase, and 487 submissions are received in the test phase. Finally, 8 participating teams submitted their models and fact sheets. Almost all methods have achieved better results than baseline methods, and the winning methods in both tracks have demonstrated superior prediction performance on T2I model quality assessment.
SoftHGNN: Soft Hypergraph Neural Networks for General Visual Recognition
May 21, 2025Visual recognition relies on understanding both the semantics of image tokens and the complex interactions among them. Mainstream self-attention methods, while effective at modeling global pair-wise relations, fail to capture high-order associations inherent in real-world scenes and often suffer from redundant computation. Hypergraphs extend conventional graphs by modeling high-order interactions and offer a promising framework for addressing these limitations. However, existing hypergraph neural networks typically rely on static and hard hyperedge assignments, leading to excessive and redundant hyperedges with hard binary vertex memberships that overlook the continuity of visual semantics. To overcome these issues, we present Soft Hypergraph Neural Networks (SoftHGNNs), which extend the methodology of hypergraph computation, to make it truly efficient and versatile in visual recognition tasks. Our framework introduces the concept of soft hyperedges, where each vertex is associated with hyperedges via continuous participation weights rather than hard binary assignments. This dynamic and differentiable association is achieved by using the learnable hyperedge prototype. Through similarity measurements between token features and the prototype, the model generates semantically rich soft hyperedges. SoftHGNN then aggregates messages over soft hyperedges to capture high-order semantics. To further enhance efficiency when scaling up the number of soft hyperedges, we incorporate a sparse hyperedge selection mechanism that activates only the top-k important hyperedges, along with a load-balancing regularizer to ensure balanced hyperedge utilization. Experimental results across three tasks on five datasets demonstrate that SoftHGNN efficiently captures high-order associations in visual scenes, achieving significant performance improvements.
SEAGULL: No-reference Image Quality Assessment for Regions of Interest via Vision-Language Instruction Tuning
Nov 15, 2024



Existing Image Quality Assessment (IQA) methods achieve remarkable success in analyzing quality for overall image, but few works explore quality analysis for Regions of Interest (ROIs). The quality analysis of ROIs can provide fine-grained guidance for image quality improvement and is crucial for scenarios focusing on region-level quality. This paper proposes a novel network, SEAGULL, which can SEe and Assess ROIs quality with GUidance from a Large vision-Language model. SEAGULL incorporates a vision-language model (VLM), masks generated by Segment Anything Model (SAM) to specify ROIs, and a meticulously designed Mask-based Feature Extractor (MFE) to extract global and local tokens for specified ROIs, enabling accurate fine-grained IQA for ROIs. Moreover, this paper constructs two ROI-based IQA datasets, SEAGULL-100w and SEAGULL-3k, for training and evaluating ROI-based IQA. SEAGULL-100w comprises about 100w synthetic distortion images with 33 million ROIs for pre-training to improve the model's ability of regional quality perception, and SEAGULL-3k contains about 3k authentic distortion ROIs to enhance the model's ability to perceive real world distortions. After pre-training on SEAGULL-100w and fine-tuning on SEAGULL-3k, SEAGULL shows remarkable performance on fine-grained ROI quality assessment. Code and datasets are publicly available at the https://github.com/chencn2020/Seagull.
Autonomous Driving in Unstructured Environments: How Far Have We Come?
Oct 10, 2024

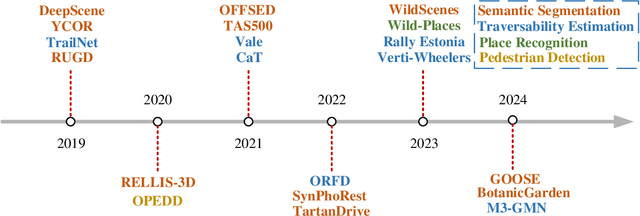

Research on autonomous driving in unstructured outdoor environments is less advanced than in structured urban settings due to challenges like environmental diversities and scene complexity. These environments-such as rural areas and rugged terrains-pose unique obstacles that are not common in structured urban areas. Despite these difficulties, autonomous driving in unstructured outdoor environments is crucial for applications in agriculture, mining, and military operations. Our survey reviews over 250 papers for autonomous driving in unstructured outdoor environments, covering offline mapping, pose estimation, environmental perception, path planning, end-to-end autonomous driving, datasets, and relevant challenges. We also discuss emerging trends and future research directions. This review aims to consolidate knowledge and encourage further research for autonomous driving in unstructured environments. To support ongoing work, we maintain an active repository with up-to-date literature and open-source projects at: https://github.com/chaytonmin/Survey-Autonomous-Driving-in-Unstructured-Environments.
Structure-Centric Robust Monocular Depth Estimation via Knowledge Distillation
Oct 09, 2024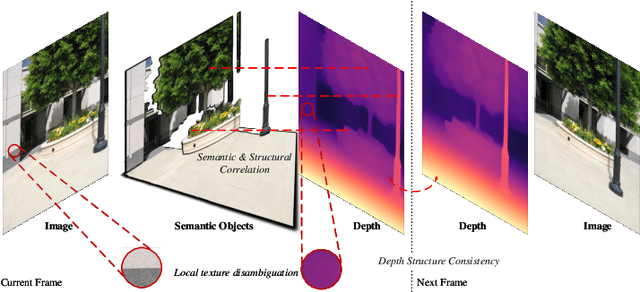
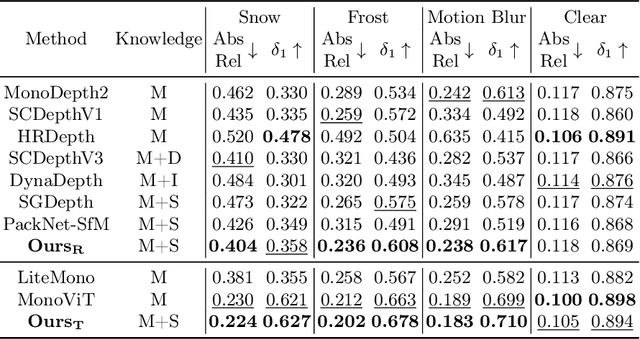
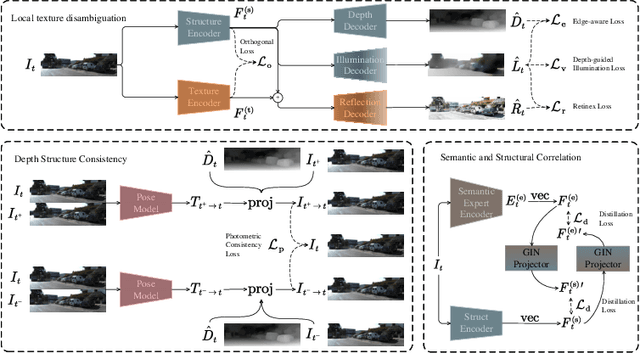
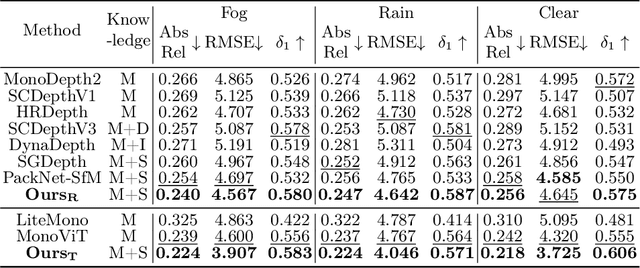
Monocular depth estimation, enabled by self-supervised learning, is a key technique for 3D perception in computer vision. However, it faces significant challenges in real-world scenarios, which encompass adverse weather variations, motion blur, as well as scenes with poor lighting conditions at night. Our research reveals that we can divide monocular depth estimation into three sub-problems: depth structure consistency, local texture disambiguation, and semantic-structural correlation. Our approach tackles the non-robustness of existing self-supervised monocular depth estimation models to interference textures by adopting a structure-centered perspective and utilizing the scene structure characteristics demonstrated by semantics and illumination. We devise a novel approach to reduce over-reliance on local textures, enhancing robustness against missing or interfering patterns. Additionally, we incorporate a semantic expert model as the teacher and construct inter-model feature dependencies via learnable isomorphic graphs to enable aggregation of semantic structural knowledge. Our approach achieves state-of-the-art out-of-distribution monocular depth estimation performance across a range of public adverse scenario datasets. It demonstrates notable scalability and compatibility, without necessitating extensive model engineering. This showcases the potential for customizing models for diverse industrial applications.
MobileIQA: Exploiting Mobile-level Diverse Opinion Network For No-Reference Image Quality Assessment Using Knowledge Distillation
Sep 02, 2024With the rising demand for high-resolution (HR) images, No-Reference Image Quality Assessment (NR-IQA) gains more attention, as it can ecaluate image quality in real-time on mobile devices and enhance user experience. However, existing NR-IQA methods often resize or crop the HR images into small resolution, which leads to a loss of important details. And most of them are of high computational complexity, which hinders their application on mobile devices due to limited computational resources. To address these challenges, we propose MobileIQA, a novel approach that utilizes lightweight backbones to efficiently assess image quality while preserving image details through high-resolution input. MobileIQA employs the proposed multi-view attention learning (MAL) module to capture diverse opinions, simulating subjective opinions provided by different annotators during the dataset annotation process. The model uses a teacher model to guide the learning of a student model through knowledge distillation. This method significantly reduces computational complexity while maintaining high performance. Experiments demonstrate that MobileIQA outperforms novel IQA methods on evaluation metrics and computational efficiency. The code is available at https://github.com/chencn2020/MobileIQA.