 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructure-Centric Robust Monocular Depth Estimation via Knowledge Distillation
Oct 09, 2024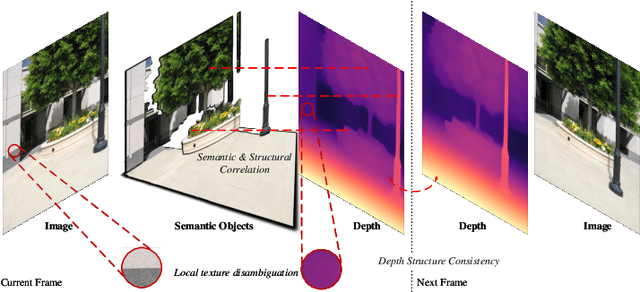
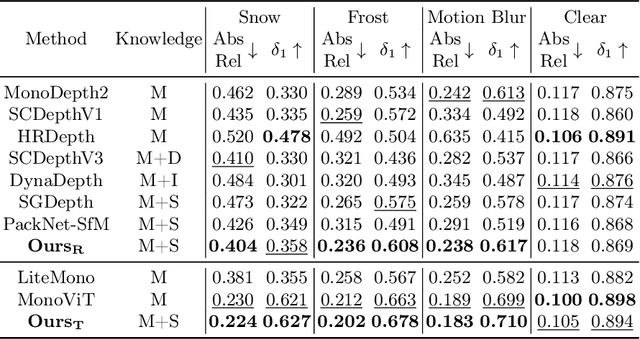
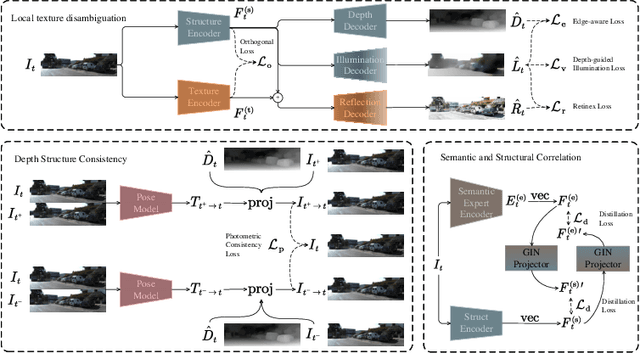
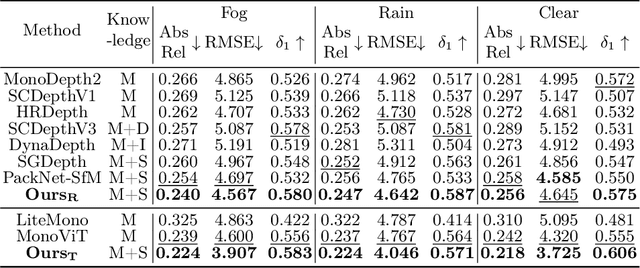
Monocular depth estimation, enabled by self-supervised learning, is a key technique for 3D perception in computer vision. However, it faces significant challenges in real-world scenarios, which encompass adverse weather variations, motion blur, as well as scenes with poor lighting conditions at night. Our research reveals that we can divide monocular depth estimation into three sub-problems: depth structure consistency, local texture disambiguation, and semantic-structural correlation. Our approach tackles the non-robustness of existing self-supervised monocular depth estimation models to interference textures by adopting a structure-centered perspective and utilizing the scene structure characteristics demonstrated by semantics and illumination. We devise a novel approach to reduce over-reliance on local textures, enhancing robustness against missing or interfering patterns. Additionally, we incorporate a semantic expert model as the teacher and construct inter-model feature dependencies via learnable isomorphic graphs to enable aggregation of semantic structural knowledge. Our approach achieves state-of-the-art out-of-distribution monocular depth estimation performance across a range of public adverse scenario datasets. It demonstrates notable scalability and compatibility, without necessitating extensive model engineering. This showcases the potential for customizing models for diverse industrial applications.
CSS: Overcoming Pose and Scene Challenges in Crowd-Sourced 3D Gaussian Splatting
Sep 13, 2024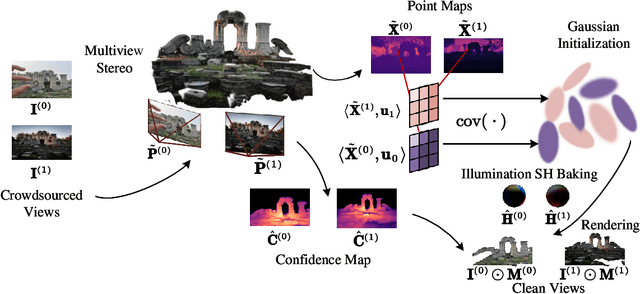

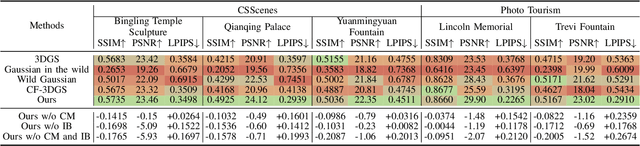
We introduce Crowd-Sourced Splatting (CSS), a novel 3D Gaussian Splatting (3DGS) pipeline designed to overcome the challenges of pose-free scene reconstruction using crowd-sourced imagery. The dream of reconstructing historically significant but inaccessible scenes from collections of photographs has long captivated researchers. However, traditional 3D techniques struggle with missing camera poses, limited viewpoints, and inconsistent lighting. CSS addresses these challenges through robust geometric priors and advanced illumination modeling, enabling high-quality novel view synthesis under complex, real-world conditions. Our method demonstrates clear improvements over existing approaches, paving the way for more accurate and flexible applications in AR, VR, and large-scale 3D reconstruction.
Map-Free Visual Relocalization Enhanced by Instance Knowledge and Depth Knowledge
Aug 23, 2024
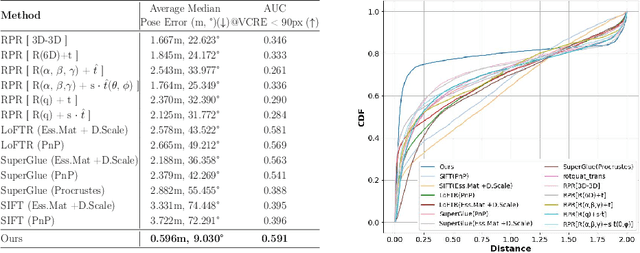
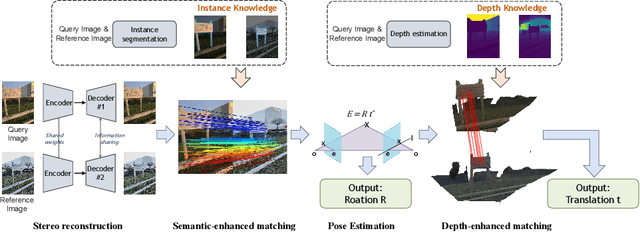

Map-free relocalization technology is crucial for applications in autonomous navigation and augmented reality, but relying on pre-built maps is often impractical. It faces significant challenges due to limitations in matching methods and the inherent lack of scale in monocular images. These issues lead to substantial rotational and metric errors and even localization failures in real-world scenarios. Large matching errors significantly impact the overall relocalization process, affecting both rotational and translational accuracy. Due to the inherent limitations of the camera itself, recovering the metric scale from a single image is crucial, as this significantly impacts the translation error. To address these challenges, we propose a map-free relocalization method enhanced by instance knowledge and depth knowledge. By leveraging instance-based matching information to improve global matching results, our method significantly reduces the possibility of mismatching across different objects. The robustness of instance knowledge across the scene helps the feature point matching model focus on relevant regions and enhance matching accuracy. Additionally, we use estimated metric depth from a single image to reduce metric errors and improve scale recovery accuracy. By integrating methods dedicated to mitigating large translational and rotational errors, our approach demonstrates superior performance in map-free relocalization techniques.
OccupancyDETR: Making Semantic Scene Completion as Straightforward as Object Detection
Sep 22, 2023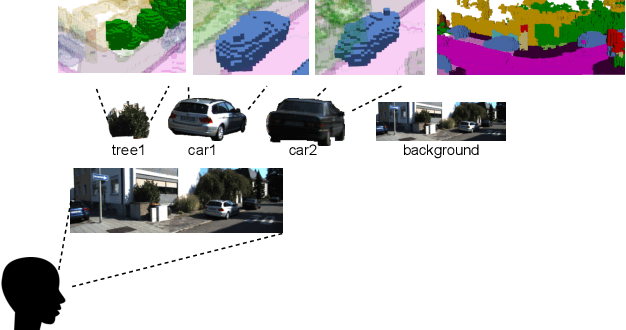
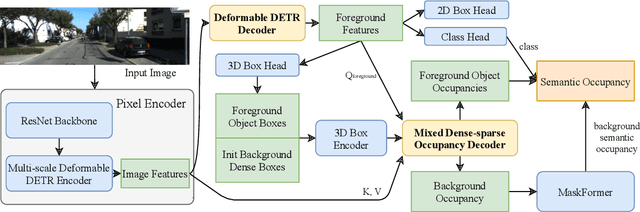
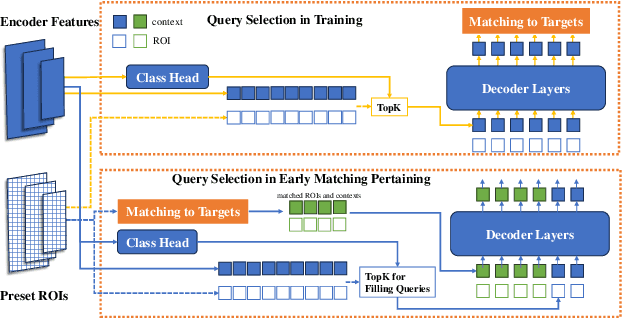
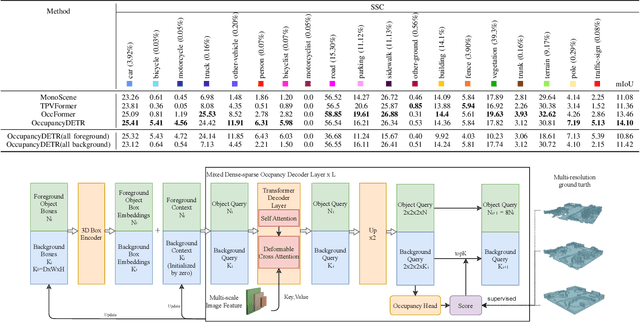
Visual-based 3D semantic occupancy perception (also known as 3D semantic scene completion) is a new perception paradigm for robotic applications like autonomous driving. Compared with Bird's Eye View (BEV) perception, it extends the vertical dimension, significantly enhancing the ability of robots to understand their surroundings. However, due to this very reason, the computational demand for current 3D semantic occupancy perception methods generally surpasses that of BEV perception methods and 2D perception methods. We propose a novel 3D semantic occupancy perception method, OccupancyDETR, which consists of a DETR-like object detection module and a 3D occupancy decoder module. The integration of object detection simplifies our method structurally - instead of predicting the semantics of each voxels, it identifies objects in the scene and their respective 3D occupancy grids. This speeds up our method, reduces required resources, and leverages object detection algorithm, giving our approach notable performance on small objects. We demonstrate the effectiveness of our proposed method on the SemanticKITTI dataset, showcasing an mIoU of 23 and a processing speed of 6 frames per second, thereby presenting a promising solution for real-time 3D semantic scene completion.
The RoboDepth Challenge: Methods and Advancements Towards Robust Depth Estimation
Jul 27, 2023



Accurate depth estimation under out-of-distribution (OoD) scenarios, such as adverse weather conditions, sensor failure, and noise contamination, is desirable for safety-critical applications. Existing depth estimation systems, however, suffer inevitably from real-world corruptions and perturbations and are struggled to provide reliable depth predictions under such cases. In this paper, we summarize the winning solutions from the RoboDepth Challenge -- an academic competition designed to facilitate and advance robust OoD depth estimation. This challenge was developed based on the newly established KITTI-C and NYUDepth2-C benchmarks. We hosted two stand-alone tracks, with an emphasis on robust self-supervised and robust fully-supervised depth estimation, respectively. Out of more than two hundred participants, nine unique and top-performing solutions have appeared, with novel designs ranging from the following aspects: spatial- and frequency-domain augmentations, masked image modeling, image restoration and super-resolution, adversarial training, diffusion-based noise suppression, vision-language pre-training, learned model ensembling, and hierarchical feature enhancement. Extensive experimental analyses along with insightful observations are drawn to better understand the rationale behind each design. We hope this challenge could lay a solid foundation for future research on robust and reliable depth estimation and beyond. The datasets, competition toolkit, workshop recordings, and source code from the winning teams are publicly available on the challenge website.
Modeling Accurate Human Activity Recognition for Embedded Devices Using Multi-level Distillation
Jul 06, 2021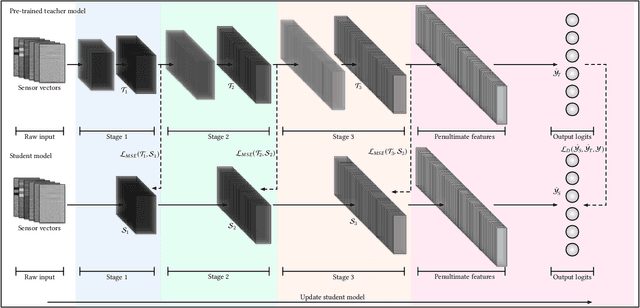
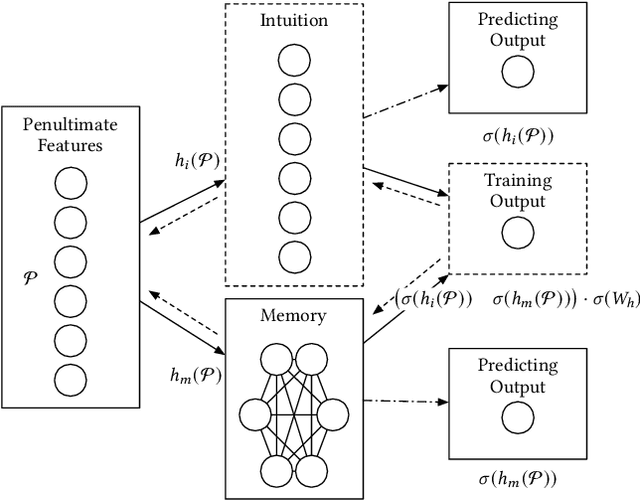

Human activity recognition (HAR) based on IMU sensors is an essential domain in ubiquitous computing. Because of the improving trend to deploy artificial intelligence into IoT devices or smartphones, more researchers design the HAR models for embedded devices. We propose a plug-and-play HAR modeling pipeline with multi-level distillation to build deep convolutional HAR models with native support of embedded devices. SMLDist consists of stage distillation, memory distillation, and logits distillation, which covers all the information flow of the deep models. Stage distillation constrains the learning direction of the intermediate features. Memory distillation teaches the student models how to explain and store the inner relationship between high-dimensional features based on Hopfield networks. Logits distillation constructs distilled logits by a smoothed conditional rule to keep the probable distribution and improve the correctness of the soft target. We compare the performance of accuracy, F1 macro score, and energy cost on the embedded platform of various state-of-the-art HAR frameworks with a MobileNet V3 model built by SMLDist. The produced model has well balance with robustness, efficiency, and accuracy. SMLDist can also compress the models with minor performance loss in an equal compression rate than other state-of-the-art knowledge distillation methods on seven public datasets.
Adaptive Locality Preserving Regression
Jan 03, 2019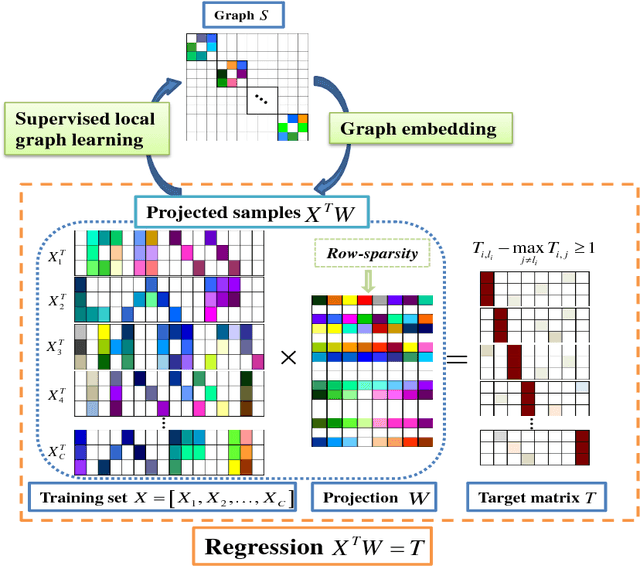
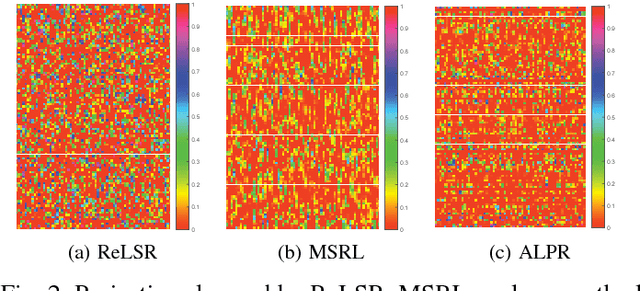

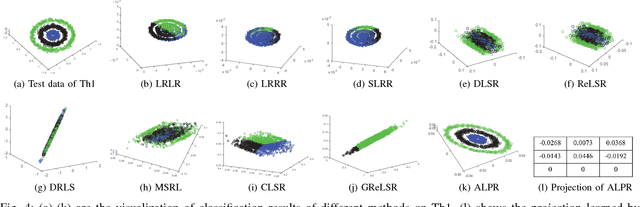
This paper proposes a novel discriminative regression method, called adaptive locality preserving regression (ALPR) for classification. In particular, ALPR aims to learn a more flexible and discriminative projection that not only preserves the intrinsic structure of data, but also possesses the properties of feature selection and interpretability. To this end, we introduce a target learning technique to adaptively learn a more discriminative and flexible target matrix rather than the pre-defined strict zero-one label matrix for regression. Then a locality preserving constraint regularized by the adaptive learned weights is further introduced to guide the projection learning, which is beneficial to learn a more discriminative projection and avoid overfitting. Moreover, we replace the conventional `Frobenius norm' with the special l21 norm to constrain the projection, which enables the method to adaptively select the most important features from the original high-dimensional data for feature extraction. In this way, the negative influence of the redundant features and noises residing in the original data can be greatly eliminated. Besides, the proposed method has good interpretability for features owing to the row-sparsity property of the l21 norm. Extensive experiments conducted on the synthetic database with manifold structure and many real-world databases prove the effectiveness of the proposed method.
* The paper has been accepted by IEEE Transactions on Circuits and Systems for Video Technology (TCSVT), and the code can be available at https://drive.google.com/file/d/1iNzONkRByIaUhXwdEhOkkh_0d2AAXNE8/view