 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpInf-LLM: Parametric PDE Solving with LLMs via Operator Inference
Feb 02, 2026Solving diverse partial differential equations (PDEs) is fundamental in science and engineering. Large language models (LLMs) have demonstrated strong capabilities in code generation, symbolic reasoning, and tool use, but reliably solving PDEs across heterogeneous settings remains challenging. Prior work on LLM-based code generation and transformer-based foundation models for PDE learning has shown promising advances. However, a persistent trade-off between execution success rate and numerical accuracy arises, particularly when generalization to unseen parameters and boundary conditions is required. In this work, we propose OpInf-LLM, an LLM parametric PDE solving framework based on operator inference. The proposed framework leverages a small amount of solution data to enable accurate prediction of diverse PDE instances, including unseen parameters and configurations, and provides seamless integration with LLMs for natural language specification of PDE solving tasks. Its low computational demands and unified tool interface further enable a high execution success rate across heterogeneous settings. By combining operator inference with LLM capabilities, OpInf-LLM opens new possibilities for generalizable reduced-order modeling in LLM-based PDE solving.
The RoboSense Challenge: Sense Anything, Navigate Anywhere, Adapt Across Platforms
Jan 08, 2026Autonomous systems are increasingly deployed in open and dynamic environments -- from city streets to aerial and indoor spaces -- where perception models must remain reliable under sensor noise, environmental variation, and platform shifts. However, even state-of-the-art methods often degrade under unseen conditions, highlighting the need for robust and generalizable robot sensing. The RoboSense 2025 Challenge is designed to advance robustness and adaptability in robot perception across diverse sensing scenarios. It unifies five complementary research tracks spanning language-grounded decision making, socially compliant navigation, sensor configuration generalization, cross-view and cross-modal correspondence, and cross-platform 3D perception. Together, these tasks form a comprehensive benchmark for evaluating real-world sensing reliability under domain shifts, sensor failures, and platform discrepancies. RoboSense 2025 provides standardized datasets, baseline models, and unified evaluation protocols, enabling large-scale and reproducible comparison of robust perception methods. The challenge attracted 143 teams from 85 institutions across 16 countries, reflecting broad community engagement. By consolidating insights from 23 winning solutions, this report highlights emerging methodological trends, shared design principles, and open challenges across all tracks, marking a step toward building robots that can sense reliably, act robustly, and adapt across platforms in real-world environments.
On the Boundary Feasibility for PDE Control with Neural Operators
Nov 23, 2024



The physical world dynamics are generally governed by underlying partial differential equations (PDEs) with unknown analytical forms in science and engineering problems. Neural network based data-driven approaches have been heavily studied in simulating and solving PDE problems in recent years, but it is still challenging to move forward from understanding to controlling the unknown PDE dynamics. PDE boundary control instantiates a simplified but important problem by only focusing on PDE boundary conditions as the control input and output. However, current model-free PDE controllers cannot ensure the boundary output satisfies some given user-specified safety constraint. To this end, we propose a safety filtering framework to guarantee the boundary output stays within the safe set for current model-free controllers. Specifically, we first introduce a general neural boundary control barrier function (BCBF) to ensure the feasibility of the trajectorywise constraint satisfaction of boundary output. Based on a neural operator modeling the transfer function from boundary control input to output trajectories, we show that the change in the BCBF depends linearly on the change in input boundary, so quadratic programming-based safety filtering can be done for pre-trained model-free controllers. Extensive experiments under challenging hyperbolic, parabolic and Navier-Stokes PDE dynamics environments validate the effectiveness of the proposed method in achieving better general performance and boundary constraint satisfaction compared to the model-free controller baselines.
ModelVerification.jl: a Comprehensive Toolbox for Formally Verifying Deep Neural Networks
Jun 30, 2024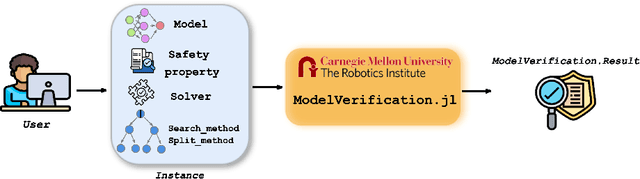

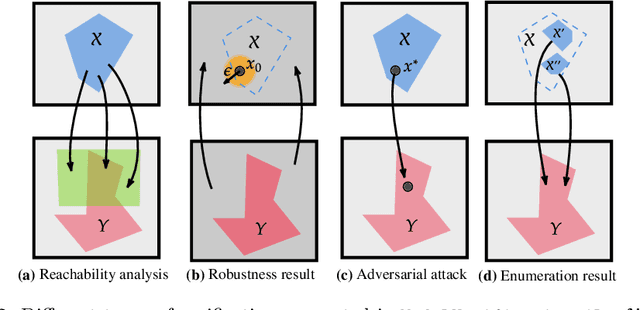
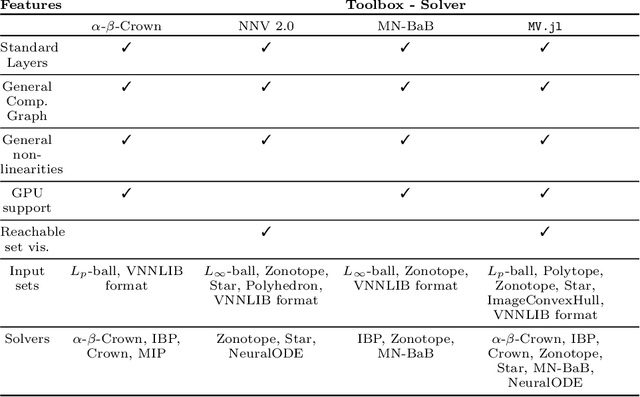
Deep Neural Networks (DNN) are crucial in approximating nonlinear functions across diverse applications, ranging from image classification to control. Verifying specific input-output properties can be a highly challenging task due to the lack of a single, self-contained framework that allows a complete range of verification types. To this end, we present \texttt{ModelVerification.jl (MV)}, the first comprehensive, cutting-edge toolbox that contains a suite of state-of-the-art methods for verifying different types of DNNs and safety specifications. This versatile toolbox is designed to empower developers and machine learning practitioners with robust tools for verifying and ensuring the trustworthiness of their DNN models.
The RoboDrive Challenge: Drive Anytime Anywhere in Any Condition
May 14, 2024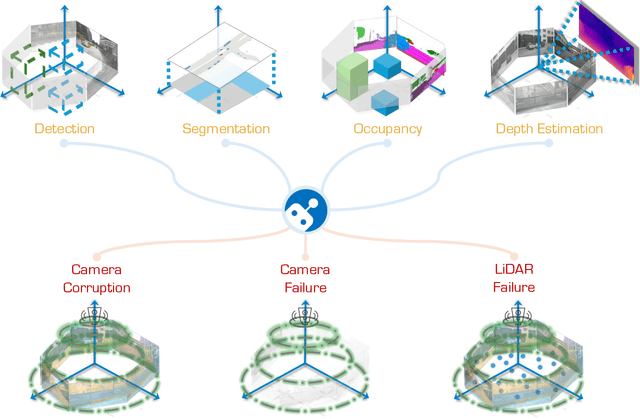


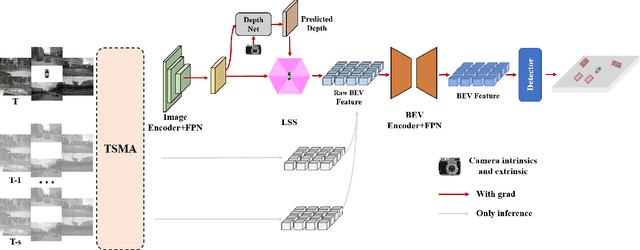
In the realm of autonomous driving, robust perception under out-of-distribution conditions is paramount for the safe deployment of vehicles. Challenges such as adverse weather, sensor malfunctions, and environmental unpredictability can severely impact the performance of autonomous systems. The 2024 RoboDrive Challenge was crafted to propel the development of driving perception technologies that can withstand and adapt to these real-world variabilities. Focusing on four pivotal tasks -- BEV detection, map segmentation, semantic occupancy prediction, and multi-view depth estimation -- the competition laid down a gauntlet to innovate and enhance system resilience against typical and atypical disturbances. This year's challenge consisted of five distinct tracks and attracted 140 registered teams from 93 institutes across 11 countries, resulting in nearly one thousand submissions evaluated through our servers. The competition culminated in 15 top-performing solutions, which introduced a range of innovative approaches including advanced data augmentation, multi-sensor fusion, self-supervised learning for error correction, and new algorithmic strategies to enhance sensor robustness. These contributions significantly advanced the state of the art, particularly in handling sensor inconsistencies and environmental variability. Participants, through collaborative efforts, pushed the boundaries of current technologies, showcasing their potential in real-world scenarios. Extensive evaluations and analyses provided insights into the effectiveness of these solutions, highlighting key trends and successful strategies for improving the resilience of driving perception systems. This challenge has set a new benchmark in the field, providing a rich repository of techniques expected to guide future research in this field.
Real-Time Safe Control of Neural Network Dynamic Models with Sound Approximation
Apr 20, 2024



Safe control of neural network dynamic models (NNDMs) is important to robotics and many applications. However, it remains challenging to compute an optimal safe control in real time for NNDM. To enable real-time computation, we propose to use a sound approximation of the NNDM in the control synthesis. In particular, we propose Bernstein over-approximated neural dynamics (BOND) based on the Bernstein polynomial over-approximation (BPO) of ReLU activation functions in NNDM. To mitigate the errors introduced by the approximation and to ensure persistent feasibility of the safe control problems, we synthesize a worst-case safety index using the most unsafe approximated state within the BPO relaxation of NNDM offline. For the online real-time optimization, we formulate the first-order Taylor approximation of the nonlinear worst-case safety constraint as an additional linear layer of NNDM with the l2 bounded bias term for the higher-order remainder. Comprehensive experiments with different neural dynamics and safety constraints show that with safety guaranteed, our NNDMs with sound approximation are 10-100 times faster than the safe control baseline that uses mixed integer programming (MIP), validating the effectiveness of the worst-case safety index and scalability of the proposed BOND in real-time large-scale settings.
Optimizing LiDAR Placements for Robust Driving Perception in Adverse Conditions
Mar 25, 2024



The robustness of driving perception systems under unprecedented conditions is crucial for safety-critical usages. Latest advancements have prompted increasing interests towards multi-LiDAR perception. However, prevailing driving datasets predominantly utilize single-LiDAR systems and collect data devoid of adverse conditions, failing to capture the complexities of real-world environments accurately. Addressing these gaps, we proposed Place3D, a full-cycle pipeline that encompasses LiDAR placement optimization, data generation, and downstream evaluations. Our framework makes three appealing contributions. 1) To identify the most effective configurations for multi-LiDAR systems, we introduce a Surrogate Metric of the Semantic Occupancy Grids (M-SOG) to evaluate LiDAR placement quality. 2) Leveraging the M-SOG metric, we propose a novel optimization strategy to refine multi-LiDAR placements. 3) Centered around the theme of multi-condition multi-LiDAR perception, we collect a 364,000-frame dataset from both clean and adverse conditions. Extensive experiments demonstrate that LiDAR placements optimized using our approach outperform various baselines. We showcase exceptional robustness in both 3D object detection and LiDAR semantic segmentation tasks, under diverse adverse weather and sensor failure conditions. Code and benchmark toolkit are publicly available.
RoboDepth: Robust Out-of-Distribution Depth Estimation under Corruptions
Oct 23, 2023Depth estimation from monocular images is pivotal for real-world visual perception systems. While current learning-based depth estimation models train and test on meticulously curated data, they often overlook out-of-distribution (OoD) situations. Yet, in practical settings -- especially safety-critical ones like autonomous driving -- common corruptions can arise. Addressing this oversight, we introduce a comprehensive robustness test suite, RoboDepth, encompassing 18 corruptions spanning three categories: i) weather and lighting conditions; ii) sensor failures and movement; and iii) data processing anomalies. We subsequently benchmark 42 depth estimation models across indoor and outdoor scenes to assess their resilience to these corruptions. Our findings underscore that, in the absence of a dedicated robustness evaluation framework, many leading depth estimation models may be susceptible to typical corruptions. We delve into design considerations for crafting more robust depth estimation models, touching upon pre-training, augmentation, modality, model capacity, and learning paradigms. We anticipate our benchmark will establish a foundational platform for advancing robust OoD depth estimation.
Influence of Camera-LiDAR Configuration on 3D Object Detection for Autonomous Driving
Oct 08, 2023Cameras and LiDARs are both important sensors for autonomous driving, playing critical roles for 3D object detection. Camera-LiDAR Fusion has been a prevalent solution for robust and accurate autonomous driving perception. In contrast to the vast majority of existing arts that focus on how to improve the performance of 3D target detection through cross-modal schemes, deep learning algorithms, and training tricks, we devote attention to the impact of sensor configurations on the performance of learning-based methods. To achieve this, we propose a unified information-theoretic surrogate metric for camera and LiDAR evaluation based on the proposed sensor perception model. We also design an accelerated high-quality framework for data acquisition, model training, and performance evaluation that functions with the CARLA simulator. To show the correlation between detection performance and our surrogate metrics, We conduct experiments using several camera-LiDAR placements and parameters inspired by self-driving companies and research institutions. Extensive experimental results of representative algorithms on NuScenes dataset validate the effectiveness of our surrogate metric, demonstrating that sensor configurations significantly impact point-cloud-image fusion based detection models, which contribute up to 30% discrepancy in terms of average precision.
Pixel-wise Smoothing for Certified Robustness against Camera Motion Perturbations
Sep 22, 2023



In recent years, computer vision has made remarkable advancements in autonomous driving and robotics. However, it has been observed that deep learning-based visual perception models lack robustness when faced with camera motion perturbations. The current certification process for assessing robustness is costly and time-consuming due to the extensive number of image projections required for Monte Carlo sampling in the 3D camera motion space. To address these challenges, we present a novel, efficient, and practical framework for certifying the robustness of 3D-2D projective transformations against camera motion perturbations. Our approach leverages a smoothing distribution over the 2D pixel space instead of in the 3D physical space, eliminating the need for costly camera motion sampling and significantly enhancing the efficiency of robustness certifications. With the pixel-wise smoothed classifier, we are able to fully upper bound the projection errors using a technique of uniform partitioning in camera motion space. Additionally, we extend our certification framework to a more general scenario where only a single-frame point cloud is required in the projection oracle. This is achieved by deriving Lipschitz-based approximated partition intervals. Through extensive experimentation, we validate the trade-off between effectiveness and efficiency enabled by our proposed method. Remarkably, our approach achieves approximately 80% certified accuracy while utilizing only 30% of the projected image frames.