 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpecRLBench: A Benchmark for Generalization in Specification-Guided Reinforcement Learning
Apr 27, 2026Specification-guided reinforcement learning (RL) provides a principled framework for encoding complex, temporally extended tasks using formal specifications such as linear temporal logic (LTL). While recent methods have shown promising results, their ability to generalize across unseen specifications and diverse environments remains insufficiently understood. In this work, we introduce SpecRLBench, a benchmark designed to evaluate the generalization capabilities of LTL-based specification-guided RL methods. The benchmark spans multiple difficulty levels across navigation and manipulation domains, incorporating both static and dynamic environments, diverse robot dynamics, and varied observation modalities. Through extensive empirical evaluation, we characterize the strengths and limitations of existing approaches and reveal the challenges that emerge as specification and environment complexity increase. SpecRLBench provides a structured platform for systematic comparison and supports the development of more generalizable specification-guided RL methods. Code is available at https://github.com/BU-DEPEND-Lab/SpecRLBench.
Robust Learning of Heterogeneous Dynamic Systems
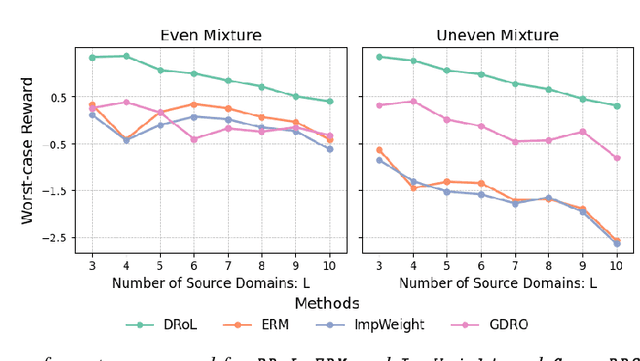
Apr 07, 2026Ordinary differential equations (ODEs) provide a powerful framework for modeling dynamic systems arising in a wide range of scientific domains. However, most existing ODE methods focus on a single system, and do not adequately address the problem of learning shared patterns from multiple heterogeneous dynamic systems. In this article, we propose a novel distributionally robust learning approach for modeling heterogeneous ODE systems. Specifically, we construct a robust dynamic system by maximizing a worst-case reward over an uncertainty class formed by convex combinations of the derivatives of trajectories. We show the resulting estimator admits an explicit weighted average representation, where the weights are obtained from a quadratic optimization that balances information across multiple data sources. We further develop a bi-level stabilization procedure to address potential instability in estimation. We establish rigorous theoretical guarantees for the proposed method, including consistency of the stabilized weights, error bound for robust trajectory estimation, and asymptotical validity of pointwise confidence interval. We demonstrate that the proposed method considerably improves the generalization performance compared to the alternative solutions through both extensive simulations and the analysis of an intracranial electroencephalogram data.
Adversarial Drift-Aware Predictive Transfer: Toward Durable Clinical AI
Jan 21, 2026Clinical AI systems frequently suffer performance decay post-deployment due to temporal data shifts, such as evolving populations, diagnostic coding updates (e.g., ICD-9 to ICD-10), and systemic shocks like the COVID-19 pandemic. Addressing this ``aging'' effect via frequent retraining is often impractical due to computational costs and privacy constraints. To overcome these hurdles, we introduce Adversarial Drift-Aware Predictive Transfer (ADAPT), a novel framework designed to confer durability against temporal drift with minimal retraining. ADAPT innovatively constructs an uncertainty set of plausible future models by combining historical source models and limited current data. By optimizing worst-case performance over this set, it balances current accuracy with robustness against degradation due to future drifts. Crucially, ADAPT requires only summary-level model estimators from historical periods, preserving data privacy and ensuring operational simplicity. Validated on longitudinal suicide risk prediction using electronic health records from Mass General Brigham (2005--2021) and Duke University Health Systems, ADAPT demonstrated superior stability across coding transitions and pandemic-induced shifts. By minimizing annual performance decay without labeling or retraining future data, ADAPT offers a scalable pathway for sustaining reliable AI in high-stakes healthcare environments.
StablePCA: Learning Shared Representations across Multiple Sources via Minimax Optimization
May 02, 2025When synthesizing multisource high-dimensional data, a key objective is to extract low-dimensional feature representations that effectively approximate the original features across different sources. Such general feature extraction facilitates the discovery of transferable knowledge, mitigates systematic biases such as batch effects, and promotes fairness. In this paper, we propose Stable Principal Component Analysis (StablePCA), a novel method for group distributionally robust learning of latent representations from high-dimensional multi-source data. A primary challenge in generalizing PCA to the multi-source regime lies in the nonconvexity of the fixed rank constraint, rendering the minimax optimization nonconvex. To address this challenge, we employ the Fantope relaxation, reformulating the problem as a convex minimax optimization, with the objective defined as the maximum loss across sources. To solve the relaxed formulation, we devise an optimistic-gradient Mirror Prox algorithm with explicit closed-form updates. Theoretically, we establish the global convergence of the Mirror Prox algorithm, with the convergence rate provided from the optimization perspective. Furthermore, we offer practical criteria to assess how closely the solution approximates the original nonconvex formulation. Through extensive numerical experiments, we demonstrate StablePCA's high accuracy and efficiency in extracting robust low-dimensional representations across various finite-sample scenarios.
Fundamental Computational Limits in Pursuing Invariant Causal Prediction and Invariance-Guided Regularization
Jan 29, 2025



Pursuing invariant prediction from heterogeneous environments opens the door to learning causality in a purely data-driven way and has several applications in causal discovery and robust transfer learning. However, existing methods such as ICP [Peters et al., 2016] and EILLS [Fan et al., 2024] that can attain sample-efficient estimation are based on exponential time algorithms. In this paper, we show that such a problem is intrinsically hard in computation: the decision problem, testing whether a non-trivial prediction-invariant solution exists across two environments, is NP-hard even for the linear causal relationship. In the world where P$\neq$NP, our results imply that the estimation error rate can be arbitrarily slow using any computationally efficient algorithm. This suggests that pursuing causality is fundamentally harder than detecting associations when no prior assumption is pre-offered. Given there is almost no hope of computational improvement under the worst case, this paper proposes a method capable of attaining both computationally and statistically efficient estimation under additional conditions. Furthermore, our estimator is a distributionally robust estimator with an ellipse-shaped uncertain set where more uncertainty is placed on spurious directions than invariant directions, resulting in a smooth interpolation between the most predictive solution and the causal solution by varying the invariance hyper-parameter. Non-asymptotic results and empirical applications support the claim.
Causal Invariance Learning via Efficient Optimization of a Nonconvex Objective
Dec 17, 2024



Data from multiple environments offer valuable opportunities to uncover causal relationships among variables. Leveraging the assumption that the causal outcome model remains invariant across heterogeneous environments, state-of-the-art methods attempt to identify causal outcome models by learning invariant prediction models and rely on exhaustive searches over all (exponentially many) covariate subsets. These approaches present two major challenges: 1) determining the conditions under which the invariant prediction model aligns with the causal outcome model, and 2) devising computationally efficient causal discovery algorithms that scale polynomially, instead of exponentially, with the number of covariates. To address both challenges, we focus on the additive intervention regime and propose nearly necessary and sufficient conditions for ensuring that the invariant prediction model matches the causal outcome model. Exploiting the essentially necessary identifiability conditions, we introduce Negative Weight Distributionally Robust Optimization (NegDRO), a nonconvex continuous minimax optimization whose global optimizer recovers the causal outcome model. Unlike standard group DRO problems that maximize over the simplex, NegDRO allows negative weights on environment losses, which break the convexity. Despite its nonconvexity, we demonstrate that a standard gradient method converges to the causal outcome model, and we establish the convergence rate with respect to the sample size and the number of iterations. Our algorithm avoids exhaustive search, making it scalable especially when the number of covariates is large. The numerical results further validate the efficiency of the proposed method.
STT: Stateful Tracking with Transformers for Autonomous Driving
Apr 30, 2024Tracking objects in three-dimensional space is critical for autonomous driving. To ensure safety while driving, the tracker must be able to reliably track objects across frames and accurately estimate their states such as velocity and acceleration in the present. Existing works frequently focus on the association task while either neglecting the model performance on state estimation or deploying complex heuristics to predict the states. In this paper, we propose STT, a Stateful Tracking model built with Transformers, that can consistently track objects in the scenes while also predicting their states accurately. STT consumes rich appearance, geometry, and motion signals through long term history of detections and is jointly optimized for both data association and state estimation tasks. Since the standard tracking metrics like MOTA and MOTP do not capture the combined performance of the two tasks in the wider spectrum of object states, we extend them with new metrics called S-MOTA and MOTPS that address this limitation. STT achieves competitive real-time performance on the Waymo Open Dataset.
Temporal Logic Specification-Conditioned Decision Transformer for Offline Safe Reinforcement Learning
Feb 27, 2024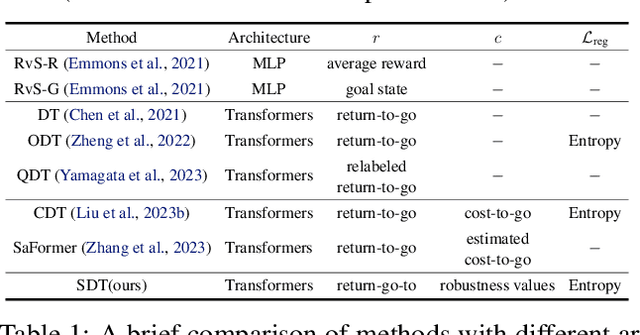
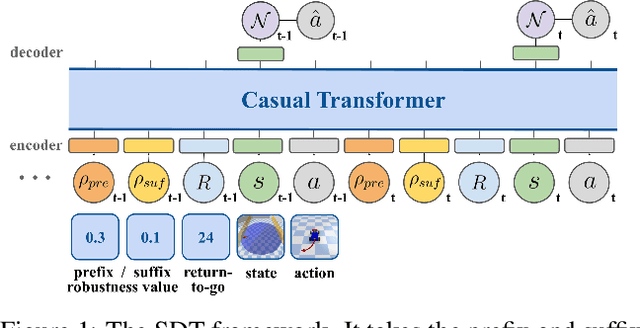
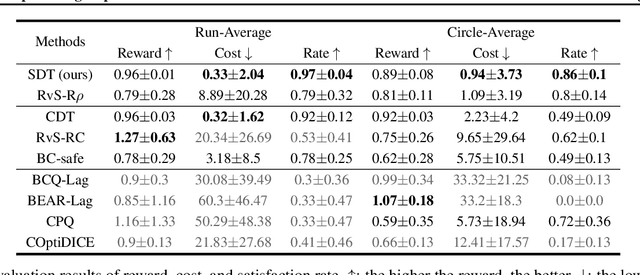
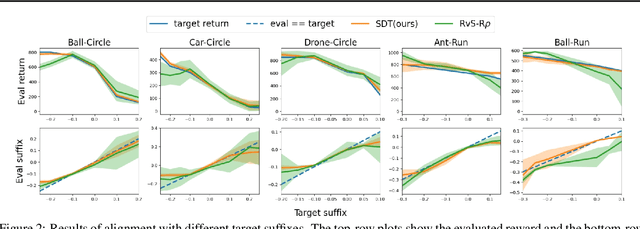
Offline safe reinforcement learning (RL) aims to train a constraint satisfaction policy from a fixed dataset. Current state-of-the-art approaches are based on supervised learning with a conditioned policy. However, these approaches fall short in real-world applications that involve complex tasks with rich temporal and logical structures. In this paper, we propose temporal logic Specification-conditioned Decision Transformer (SDT), a novel framework that harnesses the expressive power of signal temporal logic (STL) to specify complex temporal rules that an agent should follow and the sequential modeling capability of Decision Transformer (DT). Empirical evaluations on the DSRL benchmarks demonstrate the better capacity of SDT in learning safe and high-reward policies compared with existing approaches. In addition, SDT shows good alignment with respect to different desired degrees of satisfaction of the STL specification that it is conditioned on.
Distributionally Robust Transfer Learning
Sep 12, 2023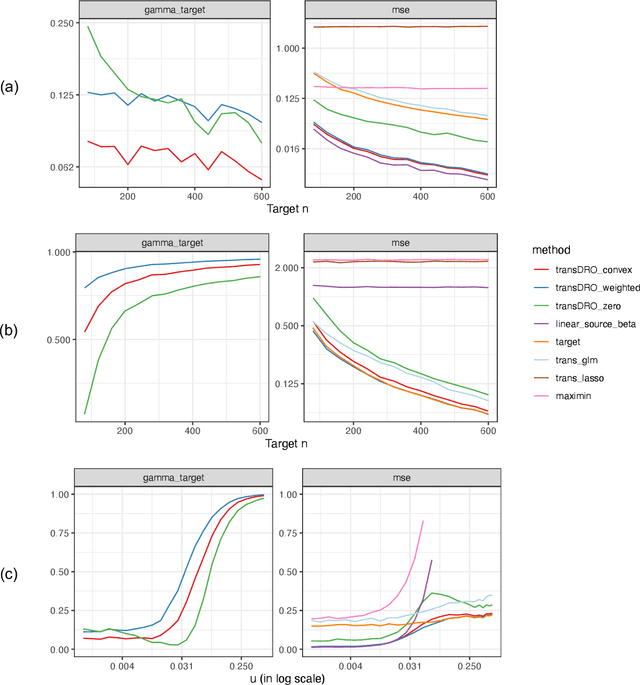
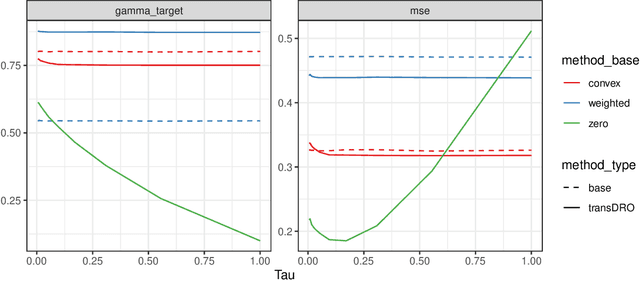
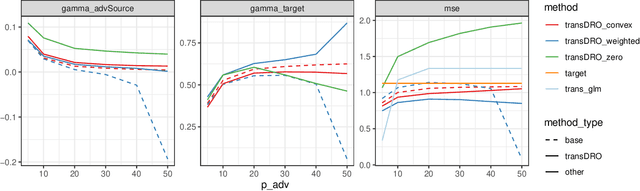
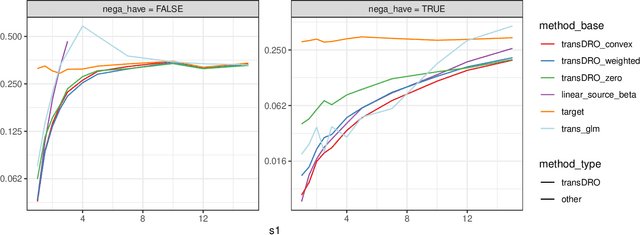
Many existing transfer learning methods rely on leveraging information from source data that closely resembles the target data. However, this approach often overlooks valuable knowledge that may be present in different yet potentially related auxiliary samples. When dealing with a limited amount of target data and a diverse range of source models, our paper introduces a novel approach, Distributionally Robust Optimization for Transfer Learning (TransDRO), that breaks free from strict similarity constraints. TransDRO is designed to optimize the most adversarial loss within an uncertainty set, defined as a collection of target populations generated as a convex combination of source distributions that guarantee excellent prediction performances for the target data. TransDRO effectively bridges the realms of transfer learning and distributional robustness prediction models. We establish the identifiability of TransDRO and its interpretation as a weighted average of source models closest to the baseline model. We also show that TransDRO achieves a faster convergence rate than the model fitted with the target data. Our comprehensive numerical studies and analysis of multi-institutional electronic health records data using TransDRO further substantiate the robustness and accuracy of TransDRO, highlighting its potential as a powerful tool in transfer learning applications.
Distributionally Robust Machine Learning with Multi-source Data
Sep 05, 2023

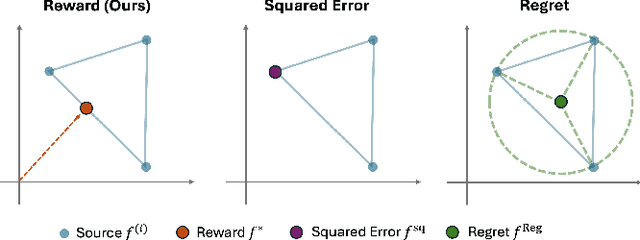
Classical machine learning methods may lead to poor prediction performance when the target distribution differs from the source populations. This paper utilizes data from multiple sources and introduces a group distributionally robust prediction model defined to optimize an adversarial reward about explained variance with respect to a class of target distributions. Compared to classical empirical risk minimization, the proposed robust prediction model improves the prediction accuracy for target populations with distribution shifts. We show that our group distributionally robust prediction model is a weighted average of the source populations' conditional outcome models. We leverage this key identification result to robustify arbitrary machine learning algorithms, including, for example, random forests and neural networks. We devise a novel bias-corrected estimator to estimate the optimal aggregation weight for general machine-learning algorithms and demonstrate its improvement in the convergence rate. Our proposal can be seen as a distributionally robust federated learning approach that is computationally efficient and easy to implement using arbitrary machine learning base algorithms, satisfies some privacy constraints, and has a nice interpretation of different sources' importance for predicting a given target covariate distribution. We demonstrate the performance of our proposed group distributionally robust method on simulated and real data with random forests and neural networks as base-learning algorithms.