 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Consistency-Based Uncertainty Quantification for Factuality in Radiology Report Generation
Dec 05, 2024



Radiology report generation (RRG) has shown great potential in assisting radiologists by automating the labor-intensive task of report writing. While recent advancements have improved the quality and coherence of generated reports, ensuring their factual correctness remains a critical challenge. Although generative medical Vision Large Language Models (VLLMs) have been proposed to address this issue, these models are prone to hallucinations and can produce inaccurate diagnostic information. To address these concerns, we introduce a novel Semantic Consistency-Based Uncertainty Quantification framework that provides both report-level and sentence-level uncertainties. Unlike existing approaches, our method does not require modifications to the underlying model or access to its inner state, such as output token logits, thus serving as a plug-and-play module that can be seamlessly integrated with state-of-the-art models. Extensive experiments demonstrate the efficacy of our method in detecting hallucinations and enhancing the factual accuracy of automatically generated radiology reports. By abstaining from high-uncertainty reports, our approach improves factuality scores by $10$%, achieved by rejecting $20$% of reports using the Radialog model on the MIMIC-CXR dataset. Furthermore, sentence-level uncertainty flags the lowest-precision sentence in each report with an $82.9$% success rate.
Rethinking Inverse Reinforcement Learning: from Data Alignment to Task Alignment
Oct 31, 2024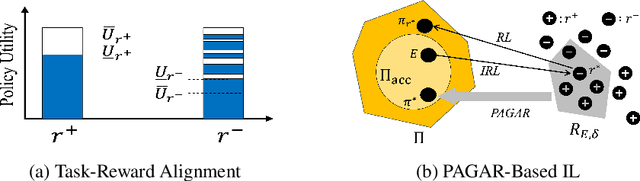



Many imitation learning (IL) algorithms use inverse reinforcement learning (IRL) to infer a reward function that aligns with the demonstration. However, the inferred reward functions often fail to capture the underlying task objectives. In this paper, we propose a novel framework for IRL-based IL that prioritizes task alignment over conventional data alignment. Our framework is a semi-supervised approach that leverages expert demonstrations as weak supervision to derive a set of candidate reward functions that align with the task rather than only with the data. It then adopts an adversarial mechanism to train a policy with this set of reward functions to gain a collective validation of the policy's ability to accomplish the task. We provide theoretical insights into this framework's ability to mitigate task-reward misalignment and present a practical implementation. Our experimental results show that our framework outperforms conventional IL baselines in complex and transfer learning scenarios.
HyQE: Ranking Contexts with Hypothetical Query Embeddings
Oct 20, 2024



In retrieval-augmented systems, context ranking techniques are commonly employed to reorder the retrieved contexts based on their relevance to a user query. A standard approach is to measure this relevance through the similarity between contexts and queries in the embedding space. However, such similarity often fails to capture the relevance. Alternatively, large language models (LLMs) have been used for ranking contexts. However, they can encounter scalability issues when the number of candidate contexts grows and the context window sizes of the LLMs remain constrained. Additionally, these approaches require fine-tuning LLMs with domain-specific data. In this work, we introduce a scalable ranking framework that combines embedding similarity and LLM capabilities without requiring LLM fine-tuning. Our framework uses a pre-trained LLM to hypothesize the user query based on the retrieved contexts and ranks the context based on the similarity between the hypothesized queries and the user query. Our framework is efficient at inference time and is compatible with many other retrieval and ranking techniques. Experimental results show that our method improves the ranking performance across multiple benchmarks. The complete code and data are available at https://github.com/zwc662/hyqe
Temporal Logic Specification-Conditioned Decision Transformer for Offline Safe Reinforcement Learning
Feb 27, 2024
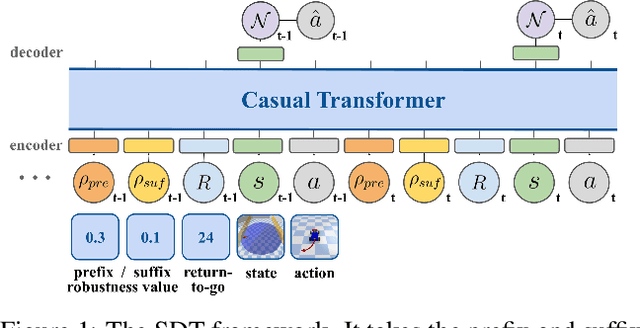
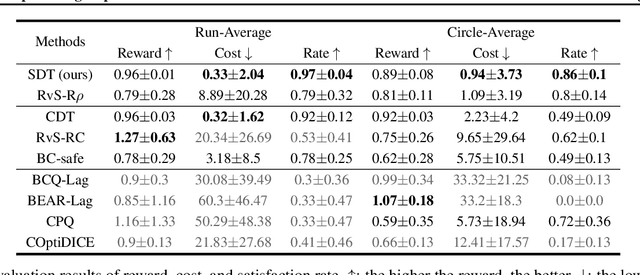
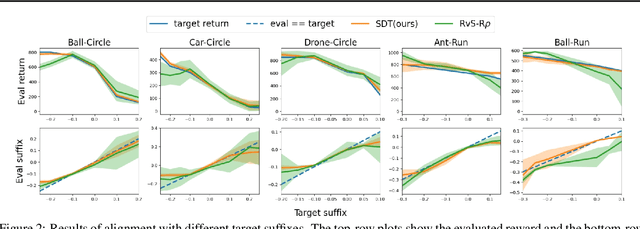
Offline safe reinforcement learning (RL) aims to train a constraint satisfaction policy from a fixed dataset. Current state-of-the-art approaches are based on supervised learning with a conditioned policy. However, these approaches fall short in real-world applications that involve complex tasks with rich temporal and logical structures. In this paper, we propose temporal logic Specification-conditioned Decision Transformer (SDT), a novel framework that harnesses the expressive power of signal temporal logic (STL) to specify complex temporal rules that an agent should follow and the sequential modeling capability of Decision Transformer (DT). Empirical evaluations on the DSRL benchmarks demonstrate the better capacity of SDT in learning safe and high-reward policies compared with existing approaches. In addition, SDT shows good alignment with respect to different desired degrees of satisfaction of the STL specification that it is conditioned on.
PAGAR: Imitation Learning with Protagonist Antagonist Guided Adversarial Reward
Jun 02, 2023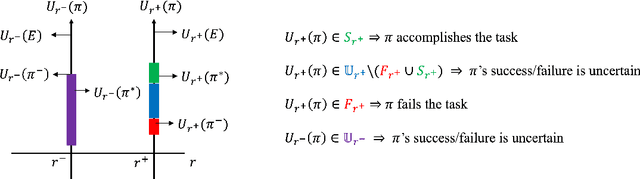



Imitation learning (IL) algorithms often rely on inverse reinforcement learning (IRL) to first learn a reward function from expert demonstrations. However, IRL can suffer from identifiability issues and there is no performance or efficiency guarantee when training with the learned reward function. In this paper, we propose Protagonist Antagonist Guided Adversarial Reward (PAGAR), a semi-supervised learning paradigm for designing rewards for policy training. PAGAR employs an iterative adversarially search for reward functions to maximize the performance gap between a protagonist policy and an antagonist policy. This allows the protagonist policy to perform well across a set of possible reward functions despite the identifiability issue. When integrated with IRL-based IL, PAGAR guarantees that the trained policy succeeds in the underlying task. Furthermore, we introduce a practical on-and-off policy approach to IL with PAGAR. This approach maximally utilizes samples from both the protagonist and antagonist policies for the optimization of policy and reward functions. Experimental results demonstrate that our algorithm achieves higher training efficiency compared to state-of-the-art IL/IRL baselines in standard settings, as well as zero-shot learning from demonstrations in transfer environments.
POLAR-Express: Efficient and Precise Formal Reachability Analysis of Neural-Network Controlled Systems
Apr 06, 2023



Neural networks (NNs) playing the role of controllers have demonstrated impressive empirical performances on challenging control problems. However, the potential adoption of NN controllers in real-life applications also gives rise to a growing concern over the safety of these neural-network controlled systems (NNCSs), especially when used in safety-critical applications. In this work, we present POLAR-Express, an efficient and precise formal reachability analysis tool for verifying the safety of NNCSs. POLAR-Express uses Taylor model arithmetic to propagate Taylor models (TMs) across a neural network layer-by-layer to compute an overapproximation of the neural-network function. It can be applied to analyze any feed-forward neural network with continuous activation functions. We also present a novel approach to propagate TMs more efficiently and precisely across ReLU activation functions. In addition, POLAR-Express provides parallel computation support for the layer-by-layer propagation of TMs, thus significantly improving the efficiency and scalability over its earlier prototype POLAR. Across the comparison with six other state-of-the-art tools on a diverse set of benchmarks, POLAR-Express achieves the best verification efficiency and tightness in the reachable set analysis.
A Hierarchical Bayesian Approach to Inverse Reinforcement Learning with Symbolic Reward Machines
Apr 20, 2022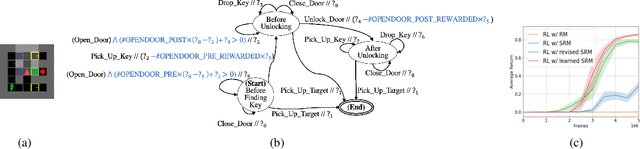

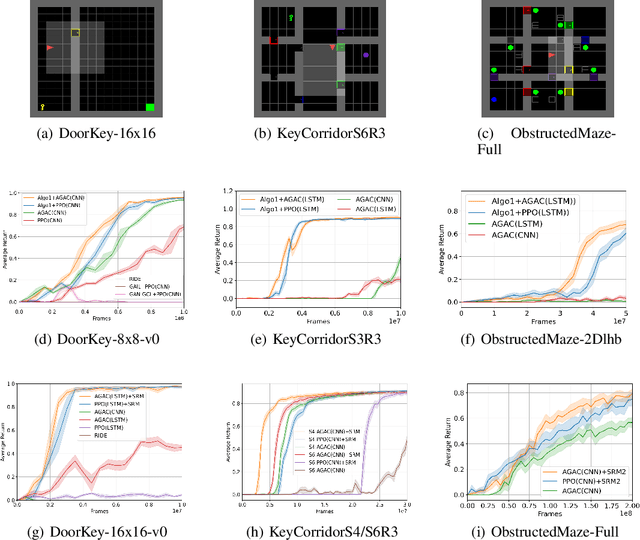
A misspecified reward can degrade sample efficiency and induce undesired behaviors in reinforcement learning (RL) problems. We propose symbolic reward machines for incorporating high-level task knowledge when specifying the reward signals. Symbolic reward machines augment existing reward machine formalism by allowing transitions to carry predicates and symbolic reward outputs. This formalism lends itself well to inverse reinforcement learning, whereby the key challenge is determining appropriate assignments to the symbolic values from a few expert demonstrations. We propose a hierarchical Bayesian approach for inferring the most likely assignments such that the concretized reward machine can discriminate expert demonstrated trajectories from other trajectories with high accuracy. Experimental results show that learned reward machines can significantly improve training efficiency for complex RL tasks and generalize well across different task environment configurations.
Programmatic Reward Design by Example
Jan 07, 2022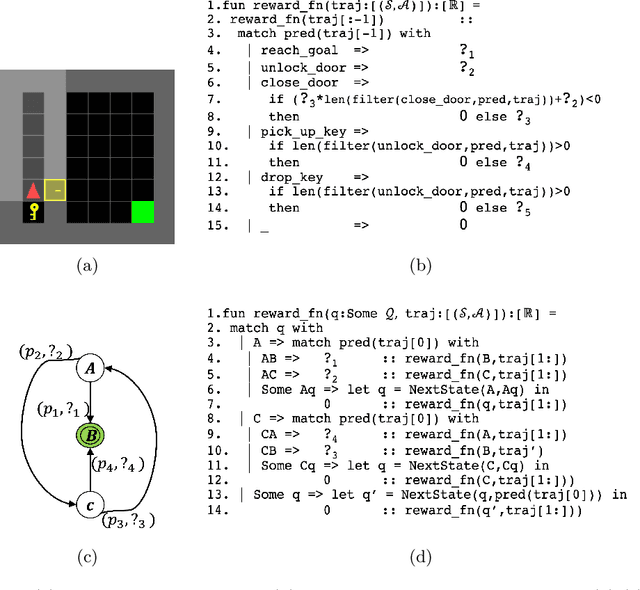
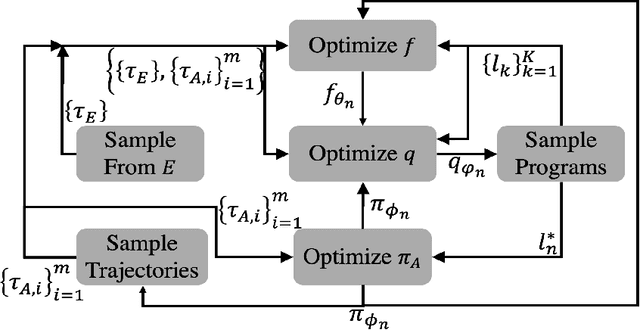
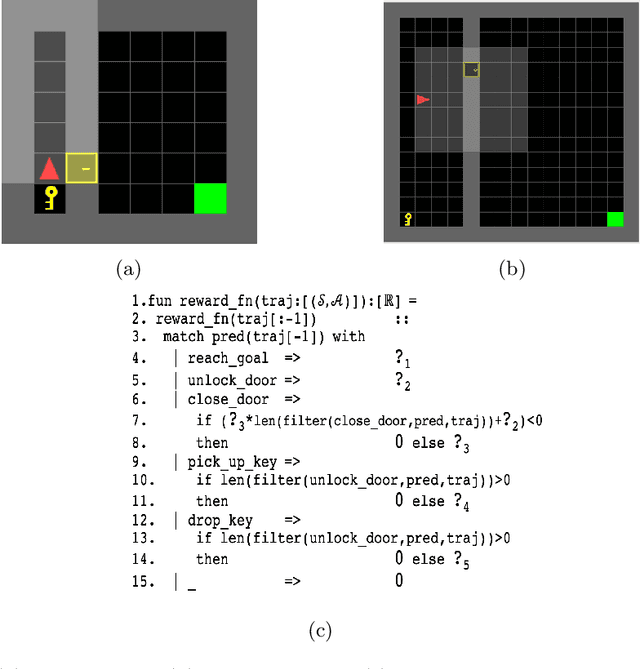
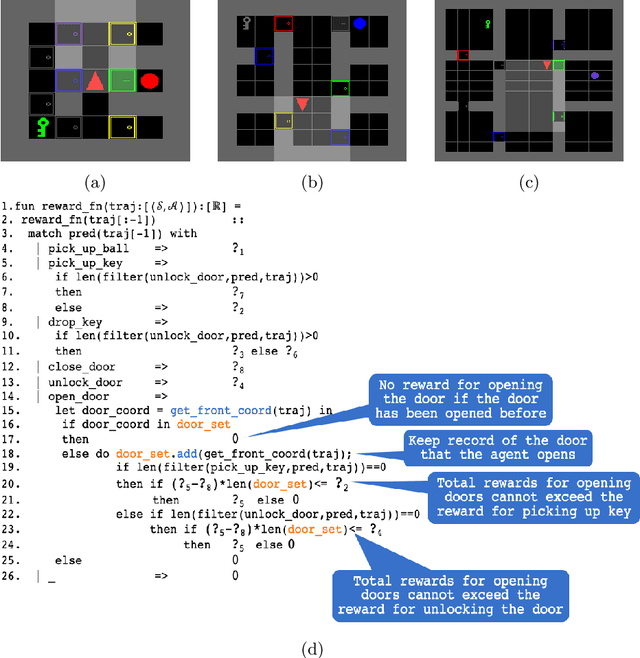
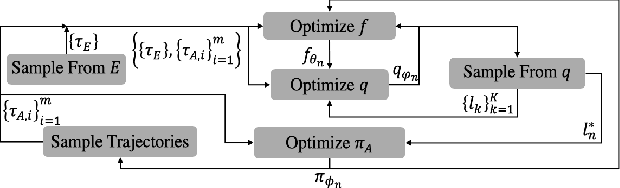
Reward design is a fundamental problem in reinforcement learning (RL). A misspecified or poorly designed reward can result in low sample efficiency and undesired behaviors. In this paper, we propose the idea of programmatic reward design, i.e. using programs to specify the reward functions in RL environments. Programs allow human engineers to express sub-goals and complex task scenarios in a structured and interpretable way. The challenge of programmatic reward design, however, is that while humans can provide the high-level structures, properly setting the low-level details, such as the right amount of reward for a specific sub-task, remains difficult. A major contribution of this paper is a probabilistic framework that can infer the best candidate programmatic reward function from expert demonstrations. Inspired by recent generative-adversarial approaches, our framework searches for the most likely programmatic reward function under which the optimally generated trajectories cannot be differentiated from the demonstrated trajectories. Experimental results show that programmatic reward functionslearned using this framework can significantly outperform those learned using existing reward learning algo-rithms, and enable RL agents to achieve state-of-the-artperformance on highly complex tasks.
Runtime-Safety-Guided Policy Repair
Aug 17, 2020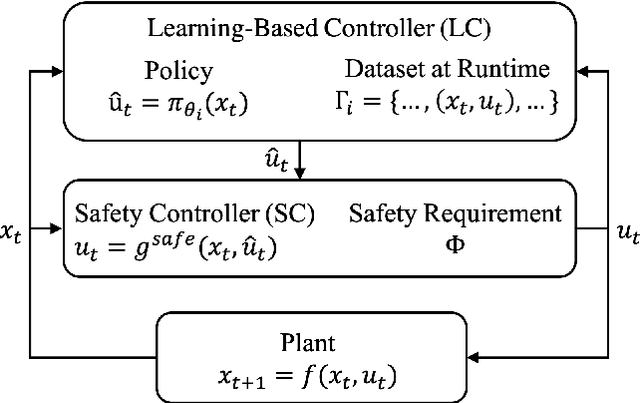
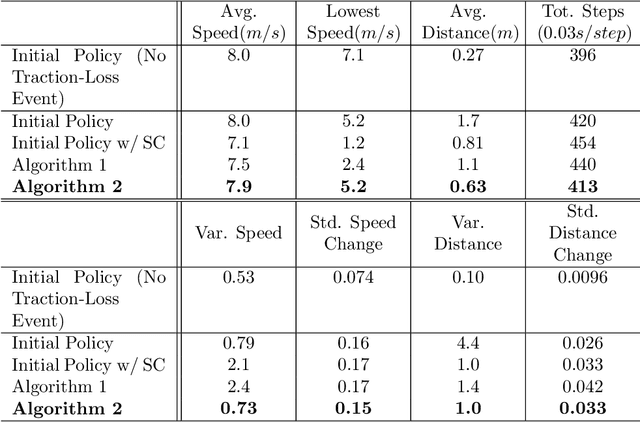
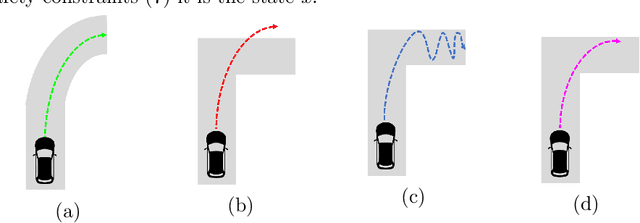
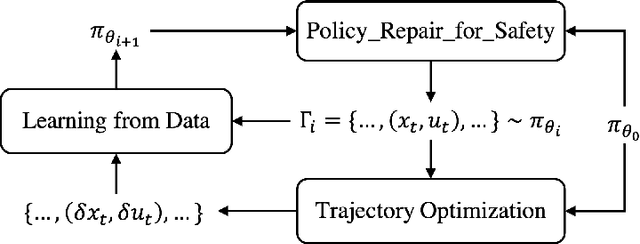
We study the problem of policy repair for learning-based control policies in safety-critical settings. We consider an architecture where a high-performance learning-based control policy (e.g. one trained as a neural network) is paired with a model-based safety controller. The safety controller is endowed with the abilities to predict whether the trained policy will lead the system to an unsafe state, and take over control when necessary. While this architecture can provide added safety assurances, intermittent and frequent switching between the trained policy and the safety controller can result in undesirable behaviors and reduced performance. We propose to reduce or even eliminate control switching by `repairing' the trained policy based on runtime data produced by the safety controller in a way that deviates minimally from the original policy. The key idea behind our approach is the formulation of a trajectory optimization problem that allows the joint reasoning of policy update and safety constraints. Experimental results demonstrate that our approach is effective even when the system model in the safety controller is unknown and only approximated.
Safety-Aware Apprenticeship Learning
Apr 28, 2018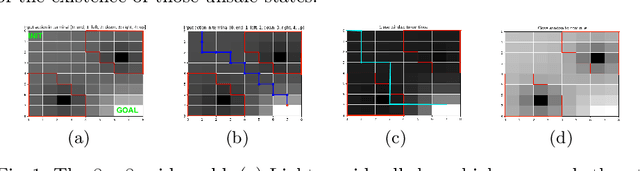
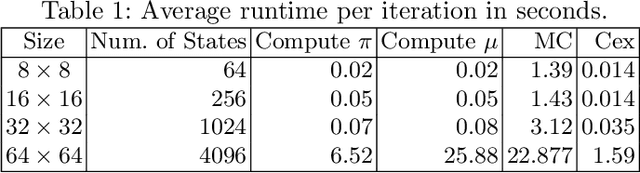
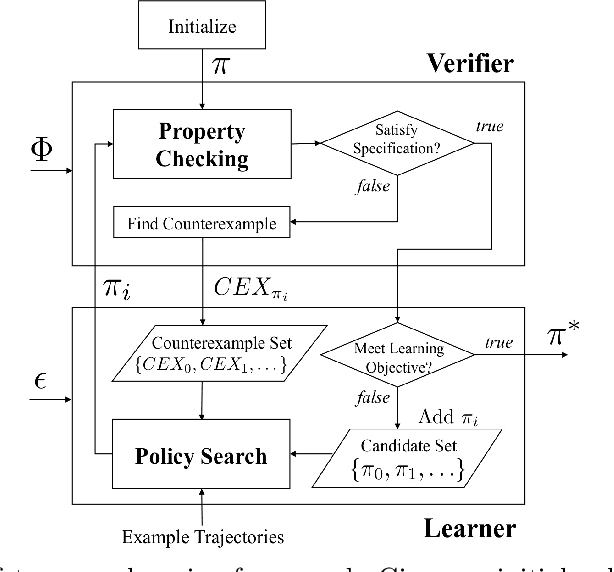
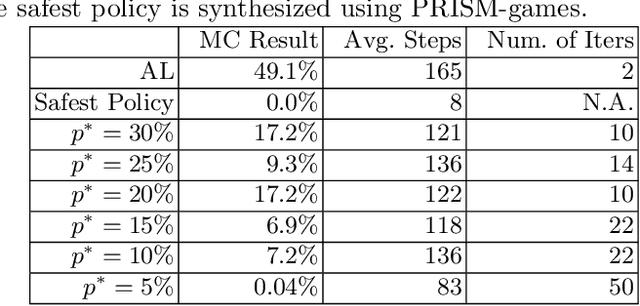
Apprenticeship learning (AL) is a kind of Learning from Demonstration techniques where the reward function of a Markov Decision Process (MDP) is unknown to the learning agent and the agent has to derive a good policy by observing an expert's demonstrations. In this paper, we study the problem of how to make AL algorithms inherently safe while still meeting its learning objective. We consider a setting where the unknown reward function is assumed to be a linear combination of a set of state features, and the safety property is specified in Probabilistic Computation Tree Logic (PCTL). By embedding probabilistic model checking inside AL, we propose a novel counterexample-guided approach that can ensure safety while retaining performance of the learnt policy. We demonstrate the effectiveness of our approach on several challenging AL scenarios where safety is essential.