 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVLM-UQBench: A Benchmark for Modality-Specific and Cross-Modality Uncertainties in Vision Language Models
Feb 09, 2026Uncertainty quantification (UQ) is vital for ensuring that vision-language models (VLMs) behave safely and reliably. A central challenge is to localize uncertainty to its source, determining whether it arises from the image, the text, or misalignment between the two. We introduce VLM-UQBench, a benchmark for modality-specific and cross-modal data uncertainty in VLMs, It consists of 600 real-world samples drawn from the VizWiz dataset, curated into clean, image-, text-, and cross-modal uncertainty subsets, and a scalable perturbation pipeline with 8 visual, 5 textual, and 3 cross-modal perturbations. We further propose two simple metrics that quantify the sensitivity of UQ scores to these perturbations and their correlation with hallucinations, and use them to evaluate a range of UQ methods across four VLMs and three datasets. Empirically, we find that: (i) existing UQ methods exhibit strong modality-specific specialization and substantial dependence on the underlying VLM, (ii) modality-specific uncertainty frequently co-occurs with hallucinations while current UQ scores provide only weak and inconsistent risk signals, and (iii) although UQ methods can rival reasoning-based chain-of-thought baselines on overt, group-level ambiguity, they largely fail to detect the subtle, instance-level ambiguity introduced by our perturbation pipeline. These results highlight a significant gap between current UQ practices and the fine-grained, modality-aware uncertainty required for reliable VLM deployment.
Names Don't Matter: Symbol-Invariant Transformer for Open-Vocabulary Learning
Jan 30, 2026Current neural architectures lack a principled way to handle interchangeable tokens, i.e., symbols that are semantically equivalent yet distinguishable, such as bound variables. As a result, models trained on fixed vocabularies often struggle to generalize to unseen symbols, even when the underlying semantics remain unchanged. We propose a novel Transformer-based mechanism that is provably invariant to the renaming of interchangeable tokens. Our approach employs parallel embedding streams to isolate the contribution of each interchangeable token in the input, combined with an aggregated attention mechanism that enables structured information sharing across streams. Experimental results confirm the theoretical guarantees of our method and demonstrate substantial performance gains on open-vocabulary tasks that require generalization to novel symbols.
Quantifying the advantage of vector over scalar magnetic sensor networks for undersea surveillance
Dec 30, 2025Magnetic monitoring of maritime environments is an important problem for monitoring and optimising shipping, as well as national security. New developments in compact, fibre-coupled quantum magnetometers have led to the opportunity to critically evaluate how best to create such a sensor network. Here we explore various magnetic sensor network architectures for target identification. Our modelling compares networks of scalar vs vector magnetometers. We implement an unscented Kalman filter approach to perform target tracking, and we find that vector networks provide a significant improvement in target tracking, specifically tracking accuracy and resilience compared with scalar networks.
Anomaly Detection and Generation with Diffusion Models: A Survey
Jun 11, 2025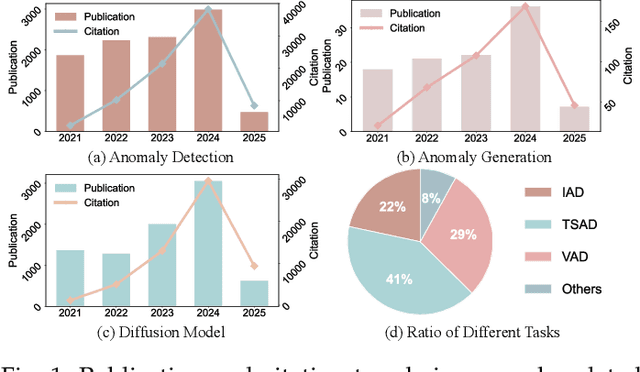

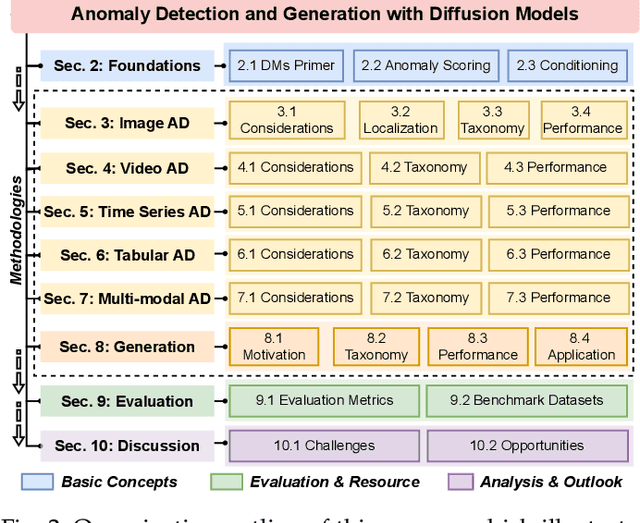

Anomaly detection (AD) plays a pivotal role across diverse domains, including cybersecurity, finance, healthcare, and industrial manufacturing, by identifying unexpected patterns that deviate from established norms in real-world data. Recent advancements in deep learning, specifically diffusion models (DMs), have sparked significant interest due to their ability to learn complex data distributions and generate high-fidelity samples, offering a robust framework for unsupervised AD. In this survey, we comprehensively review anomaly detection and generation with diffusion models (ADGDM), presenting a tutorial-style analysis of the theoretical foundations and practical implementations and spanning images, videos, time series, tabular, and multimodal data. Crucially, unlike existing surveys that often treat anomaly detection and generation as separate problems, we highlight their inherent synergistic relationship. We reveal how DMs enable a reinforcing cycle where generation techniques directly address the fundamental challenge of anomaly data scarcity, while detection methods provide critical feedback to improve generation fidelity and relevance, advancing both capabilities beyond their individual potential. A detailed taxonomy categorizes ADGDM methods based on anomaly scoring mechanisms, conditioning strategies, and architectural designs, analyzing their strengths and limitations. We final discuss key challenges including scalability and computational efficiency, and outline promising future directions such as efficient architectures, conditioning strategies, and integration with foundation models (e.g., visual-language models and large language models). By synthesizing recent advances and outlining open research questions, this survey aims to guide researchers and practitioners in leveraging DMs for innovative AD solutions across diverse applications.
ContextModule: Improving Code Completion via Repository-level Contextual Information
Dec 11, 2024Large Language Models (LLMs) have demonstrated impressive capabilities in code completion tasks, where they assist developers by predicting and generating new code in real-time. However, existing LLM-based code completion systems primarily rely on the immediate context of the file being edited, often missing valuable repository-level information, user behaviour and edit history that could improve suggestion accuracy. Additionally, challenges such as efficiently retrieving relevant code snippets from large repositories, incorporating user behavior, and balancing accuracy with low-latency requirements in production environments remain unresolved. In this paper, we propose ContextModule, a framework designed to enhance LLM-based code completion by retrieving and integrating three types of contextual information from the repository: user behavior-based code, similar code snippets, and critical symbol definitions. By capturing user interactions across files and leveraging repository-wide static analysis, ContextModule improves the relevance and precision of generated code. We implement performance optimizations, such as index caching, to ensure the system meets the latency constraints of real-world coding environments. Experimental results and industrial practise demonstrate that ContextModule significantly improves code completion accuracy and user acceptance rates.
Semantic Consistency-Based Uncertainty Quantification for Factuality in Radiology Report Generation
Dec 05, 2024



Radiology report generation (RRG) has shown great potential in assisting radiologists by automating the labor-intensive task of report writing. While recent advancements have improved the quality and coherence of generated reports, ensuring their factual correctness remains a critical challenge. Although generative medical Vision Large Language Models (VLLMs) have been proposed to address this issue, these models are prone to hallucinations and can produce inaccurate diagnostic information. To address these concerns, we introduce a novel Semantic Consistency-Based Uncertainty Quantification framework that provides both report-level and sentence-level uncertainties. Unlike existing approaches, our method does not require modifications to the underlying model or access to its inner state, such as output token logits, thus serving as a plug-and-play module that can be seamlessly integrated with state-of-the-art models. Extensive experiments demonstrate the efficacy of our method in detecting hallucinations and enhancing the factual accuracy of automatically generated radiology reports. By abstaining from high-uncertainty reports, our approach improves factuality scores by $10$%, achieved by rejecting $20$% of reports using the Radialog model on the MIMIC-CXR dataset. Furthermore, sentence-level uncertainty flags the lowest-precision sentence in each report with an $82.9$% success rate.
Rethinking Inverse Reinforcement Learning: from Data Alignment to Task Alignment
Oct 31, 2024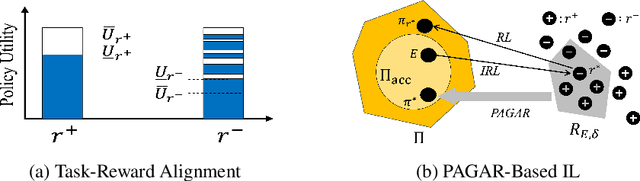



Many imitation learning (IL) algorithms use inverse reinforcement learning (IRL) to infer a reward function that aligns with the demonstration. However, the inferred reward functions often fail to capture the underlying task objectives. In this paper, we propose a novel framework for IRL-based IL that prioritizes task alignment over conventional data alignment. Our framework is a semi-supervised approach that leverages expert demonstrations as weak supervision to derive a set of candidate reward functions that align with the task rather than only with the data. It then adopts an adversarial mechanism to train a policy with this set of reward functions to gain a collective validation of the policy's ability to accomplish the task. We provide theoretical insights into this framework's ability to mitigate task-reward misalignment and present a practical implementation. Our experimental results show that our framework outperforms conventional IL baselines in complex and transfer learning scenarios.
HyQE: Ranking Contexts with Hypothetical Query Embeddings
Oct 20, 2024



In retrieval-augmented systems, context ranking techniques are commonly employed to reorder the retrieved contexts based on their relevance to a user query. A standard approach is to measure this relevance through the similarity between contexts and queries in the embedding space. However, such similarity often fails to capture the relevance. Alternatively, large language models (LLMs) have been used for ranking contexts. However, they can encounter scalability issues when the number of candidate contexts grows and the context window sizes of the LLMs remain constrained. Additionally, these approaches require fine-tuning LLMs with domain-specific data. In this work, we introduce a scalable ranking framework that combines embedding similarity and LLM capabilities without requiring LLM fine-tuning. Our framework uses a pre-trained LLM to hypothesize the user query based on the retrieved contexts and ranks the context based on the similarity between the hypothesized queries and the user query. Our framework is efficient at inference time and is compatible with many other retrieval and ranking techniques. Experimental results show that our method improves the ranking performance across multiple benchmarks. The complete code and data are available at https://github.com/zwc662/hyqe
Reinforcement Learning-based Receding Horizon Control using Adaptive Control Barrier Functions for Safety-Critical Systems
Mar 26, 2024



Optimal control methods provide solutions to safety-critical problems but easily become intractable. Control Barrier Functions (CBFs) have emerged as a popular technique that facilitates their solution by provably guaranteeing safety, through their forward invariance property, at the expense of some performance loss. This approach involves defining a performance objective alongside CBF-based safety constraints that must always be enforced. Unfortunately, both performance and solution feasibility can be significantly impacted by two key factors: (i) the selection of the cost function and associated parameters, and (ii) the calibration of parameters within the CBF-based constraints, which capture the trade-off between performance and conservativeness. %as well as infeasibility. To address these challenges, we propose a Reinforcement Learning (RL)-based Receding Horizon Control (RHC) approach leveraging Model Predictive Control (MPC) with CBFs (MPC-CBF). In particular, we parameterize our controller and use bilevel optimization, where RL is used to learn the optimal parameters while MPC computes the optimal control input. We validate our method by applying it to the challenging automated merging control problem for Connected and Automated Vehicles (CAVs) at conflicting roadways. Results demonstrate improved performance and a significant reduction in the number of infeasible cases compared to traditional heuristic approaches used for tuning CBF-based controllers, showcasing the effectiveness of the proposed method.
Temporal Logic Specification-Conditioned Decision Transformer for Offline Safe Reinforcement Learning
Feb 27, 2024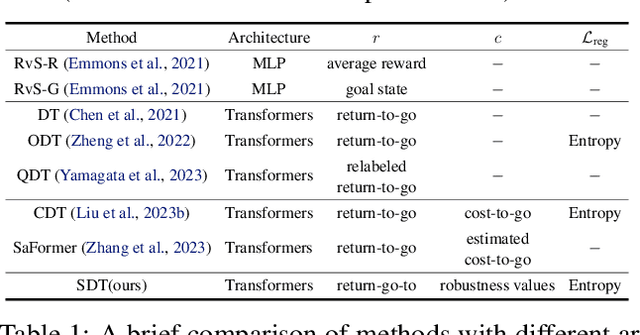
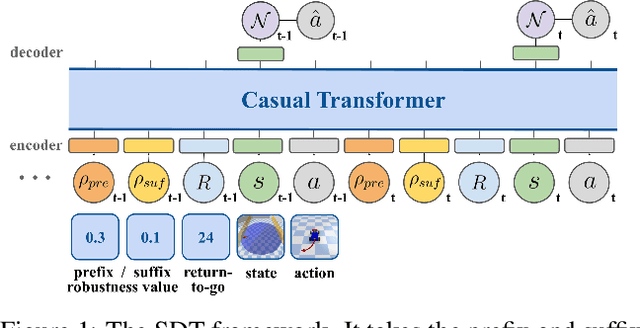
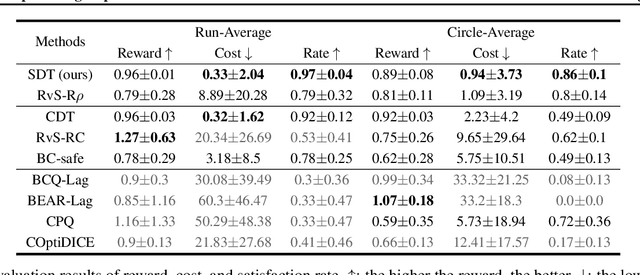
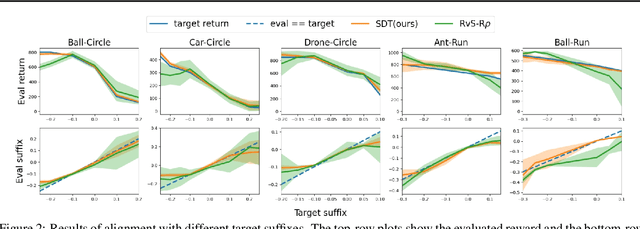
Offline safe reinforcement learning (RL) aims to train a constraint satisfaction policy from a fixed dataset. Current state-of-the-art approaches are based on supervised learning with a conditioned policy. However, these approaches fall short in real-world applications that involve complex tasks with rich temporal and logical structures. In this paper, we propose temporal logic Specification-conditioned Decision Transformer (SDT), a novel framework that harnesses the expressive power of signal temporal logic (STL) to specify complex temporal rules that an agent should follow and the sequential modeling capability of Decision Transformer (DT). Empirical evaluations on the DSRL benchmarks demonstrate the better capacity of SDT in learning safe and high-reward policies compared with existing approaches. In addition, SDT shows good alignment with respect to different desired degrees of satisfaction of the STL specification that it is conditioned on.