 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics-informed Goal-Conditioned Reinforcement Learning under Hybrid Contact Dynamics
May 28, 2026Learning to reach arbitrary goals from sparse feedback requires agents to infer a rich notion of reachability across state--goal pairs. Goal-conditioned reinforcement learning (GCRL) tackles this challenge by learning policies that generalize across goals, but this generalization becomes increasingly difficult as the underlying dynamics become high-dimensional, hybrid, or contact-dependent. To address this issue, physics-informed GCRL (Pi-GCRL) introduces optimal-control-inspired inductive biases into goal-conditioned value learning. While Pi-GCRL methods have proven effective in navigation and object-free goal-reaching domains, their reliability in contact-rich tasks remains unclear, where contact interactions induce hybrid dynamics, mode-dependent controllability, and nonsmooth value landscapes. In this work, we show that these structural properties can cause existing Pi-GCRL methods to degrade when applied naively to contact-rich manipulation. Motivated by this analysis, we introduce contact-aware and hierarchical formulations that apply physics-informed inductive biases selectively across the manipulation problem. Our results provide a principled step toward extending Pi-GCRL to contact-rich manipulation.
Goal Reaching with Eikonal-Constrained Hierarchical Quasimetric Reinforcement Learning
Dec 12, 2025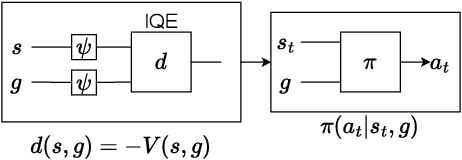
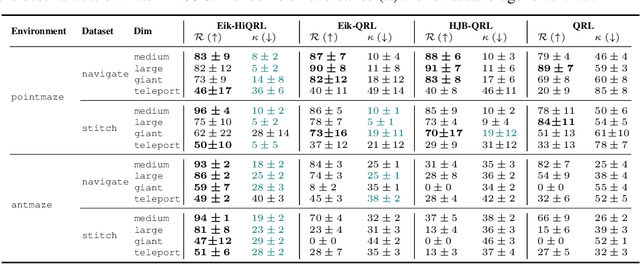

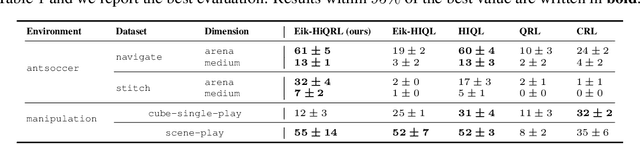
Goal-Conditioned Reinforcement Learning (GCRL) mitigates the difficulty of reward design by framing tasks as goal reaching rather than maximizing hand-crafted reward signals. In this setting, the optimal goal-conditioned value function naturally forms a quasimetric, motivating Quasimetric RL (QRL), which constrains value learning to quasimetric mappings and enforces local consistency through discrete, trajectory-based constraints. We propose Eikonal-Constrained Quasimetric RL (Eik-QRL), a continuous-time reformulation of QRL based on the Eikonal Partial Differential Equation (PDE). This PDE-based structure makes Eik-QRL trajectory-free, requiring only sampled states and goals, while improving out-of-distribution generalization. We provide theoretical guarantees for Eik-QRL and identify limitations that arise under complex dynamics. To address these challenges, we introduce Eik-Hierarchical QRL (Eik-HiQRL), which integrates Eik-QRL into a hierarchical decomposition. Empirically, Eik-HiQRL achieves state-of-the-art performance in offline goal-conditioned navigation and yields consistent gains over QRL in manipulation tasks, matching temporal-difference methods.
Automaton Constrained Q-Learning
Oct 06, 2025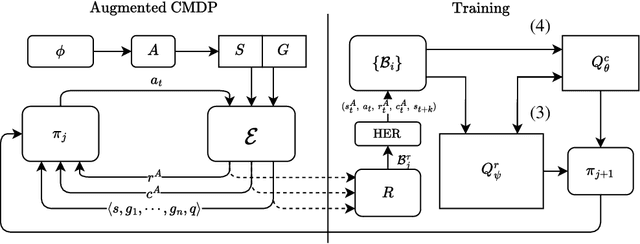
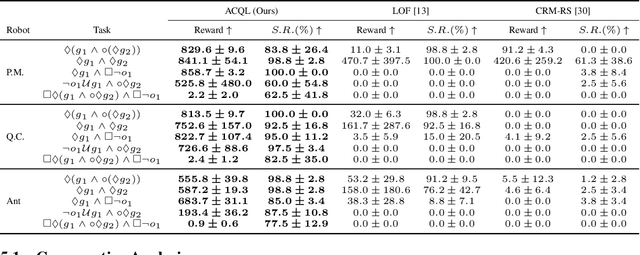

Real-world robotic tasks often require agents to achieve sequences of goals while respecting time-varying safety constraints. However, standard Reinforcement Learning (RL) paradigms are fundamentally limited in these settings. A natural approach to these problems is to combine RL with Linear-time Temporal Logic (LTL), a formal language for specifying complex, temporally extended tasks and safety constraints. Yet, existing RL methods for LTL objectives exhibit poor empirical performance in complex and continuous environments. As a result, no scalable methods support both temporally ordered goals and safety simultaneously, making them ill-suited for realistic robotics scenarios. We propose Automaton Constrained Q-Learning (ACQL), an algorithm that addresses this gap by combining goal-conditioned value learning with automaton-guided reinforcement. ACQL supports most LTL task specifications and leverages their automaton representation to explicitly encode stage-wise goal progression and both stationary and non-stationary safety constraints. We show that ACQL outperforms existing methods across a range of continuous control tasks, including cases where prior methods fail to satisfy either goal-reaching or safety constraints. We further validate its real-world applicability by deploying ACQL on a 6-DOF robotic arm performing a goal-reaching task in a cluttered, cabinet-like space with safety constraints. Our results demonstrate that ACQL is a robust and scalable solution for learning robotic behaviors according to rich temporal specifications.
Beyond Domain Randomization: Event-Inspired Perception for Visually Robust Adversarial Imitation from Videos
May 24, 2025Imitation from videos often fails when expert demonstrations and learner environments exhibit domain shifts, such as discrepancies in lighting, color, or texture. While visual randomization partially addresses this problem by augmenting training data, it remains computationally intensive and inherently reactive, struggling with unseen scenarios. We propose a different approach: instead of randomizing appearances, we eliminate their influence entirely by rethinking the sensory representation itself. Inspired by biological vision systems that prioritize temporal transients (e.g., retinal ganglion cells) and by recent sensor advancements, we introduce event-inspired perception for visually robust imitation. Our method converts standard RGB videos into a sparse, event-based representation that encodes temporal intensity gradients, discarding static appearance features. This biologically grounded approach disentangles motion dynamics from visual style, enabling robust visual imitation from observations even in the presence of visual mismatches between expert and agent environments. By training policies on event streams, we achieve invariance to appearance-based distractors without requiring computationally expensive and environment-specific data augmentation techniques. Experiments across the DeepMind Control Suite and the Adroit platform for dynamic dexterous manipulation show the efficacy of our method. Our code is publicly available at Eb-LAIfO.
Provably Efficient Off-Policy Adversarial Imitation Learning with Convergence Guarantees
May 26, 2024

Adversarial Imitation Learning (AIL) faces challenges with sample inefficiency because of its reliance on sufficient on-policy data to evaluate the performance of the current policy during reward function updates. In this work, we study the convergence properties and sample complexity of off-policy AIL algorithms. We show that, even in the absence of importance sampling correction, reusing samples generated by the $o(\sqrt{K})$ most recent policies, where $K$ is the number of iterations of policy updates and reward updates, does not undermine the convergence guarantees of this class of algorithms. Furthermore, our results indicate that the distribution shift error induced by off-policy updates is dominated by the benefits of having more data available. This result provides theoretical support for the sample efficiency of off-policy AIL algorithms. To the best of our knowledge, this is the first work that provides theoretical guarantees for off-policy AIL algorithms.
Reinforcement Learning-based Receding Horizon Control using Adaptive Control Barrier Functions for Safety-Critical Systems
Mar 26, 2024



Optimal control methods provide solutions to safety-critical problems but easily become intractable. Control Barrier Functions (CBFs) have emerged as a popular technique that facilitates their solution by provably guaranteeing safety, through their forward invariance property, at the expense of some performance loss. This approach involves defining a performance objective alongside CBF-based safety constraints that must always be enforced. Unfortunately, both performance and solution feasibility can be significantly impacted by two key factors: (i) the selection of the cost function and associated parameters, and (ii) the calibration of parameters within the CBF-based constraints, which capture the trade-off between performance and conservativeness. %as well as infeasibility. To address these challenges, we propose a Reinforcement Learning (RL)-based Receding Horizon Control (RHC) approach leveraging Model Predictive Control (MPC) with CBFs (MPC-CBF). In particular, we parameterize our controller and use bilevel optimization, where RL is used to learn the optimal parameters while MPC computes the optimal control input. We validate our method by applying it to the challenging automated merging control problem for Connected and Automated Vehicles (CAVs) at conflicting roadways. Results demonstrate improved performance and a significant reduction in the number of infeasible cases compared to traditional heuristic approaches used for tuning CBF-based controllers, showcasing the effectiveness of the proposed method.
A Model-Based Approach for Improving Reinforcement Learning Efficiency Leveraging Expert Observations
Feb 29, 2024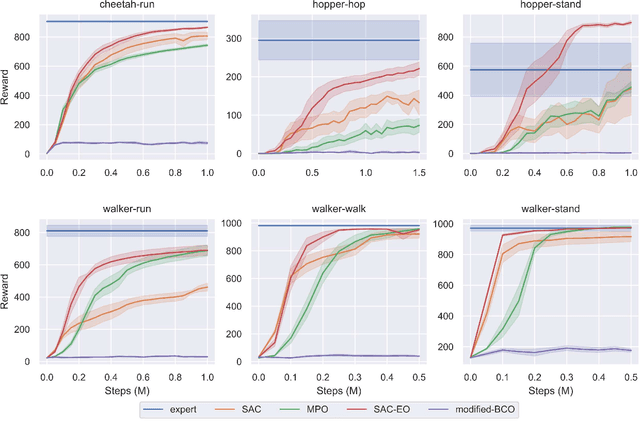
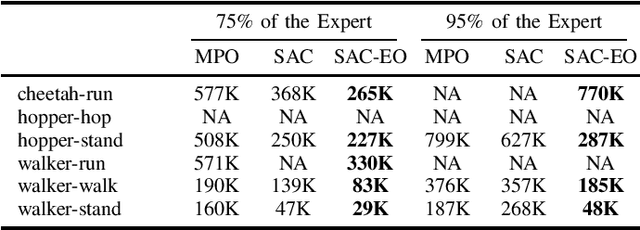


This paper investigates how to incorporate expert observations (without explicit information on expert actions) into a deep reinforcement learning setting to improve sample efficiency. First, we formulate an augmented policy loss combining a maximum entropy reinforcement learning objective with a behavioral cloning loss that leverages a forward dynamics model. Then, we propose an algorithm that automatically adjusts the weights of each component in the augmented loss function. Experiments on a variety of continuous control tasks demonstrate that the proposed algorithm outperforms various benchmarks by effectively utilizing available expert observations.
Adversarial Imitation Learning from Visual Observations using Latent Information
Sep 29, 2023
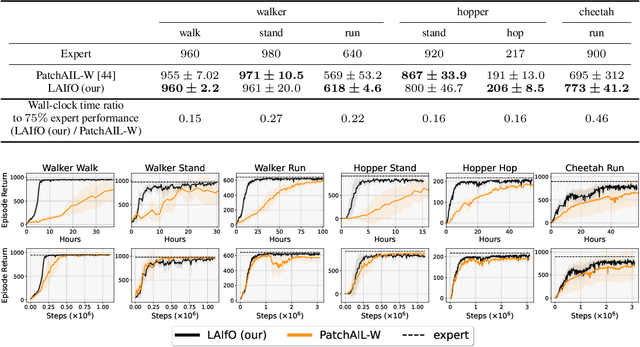
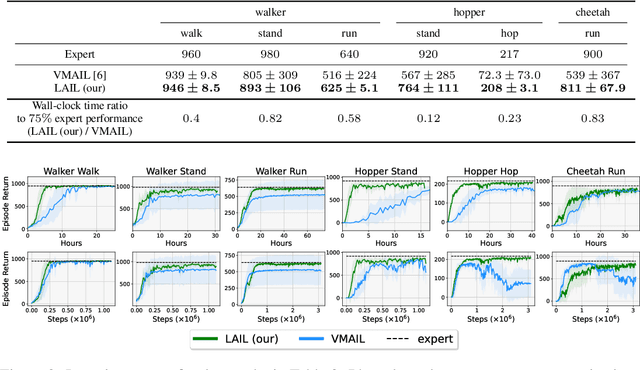
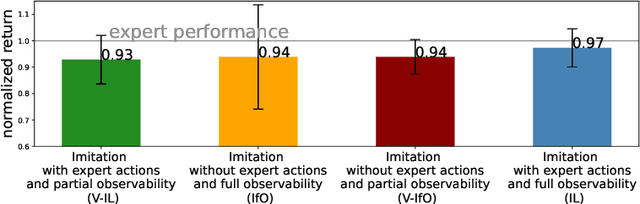
We focus on the problem of imitation learning from visual observations, where the learning agent has access to videos of experts as its sole learning source. The challenges of this framework include the absence of expert actions and the partial observability of the environment, as the ground-truth states can only be inferred from pixels. To tackle this problem, we first conduct a theoretical analysis of imitation learning in partially observable environments. We establish upper bounds on the suboptimality of the learning agent with respect to the divergence between the expert and the agent latent state-transition distributions. Motivated by this analysis, we introduce an algorithm called Latent Adversarial Imitation from Observations, which combines off-policy adversarial imitation techniques with a learned latent representation of the agent's state from sequences of observations. In experiments on high-dimensional continuous robotic tasks, we show that our algorithm matches state-of-the-art performance while providing significant computational advantages. Additionally, we show how our method can be used to improve the efficiency of reinforcement learning from pixels by leveraging expert videos. To ensure reproducibility, we provide free access to our code.
A Reinforcement Learning Approach for Robotic Unloading from Visual Observations
Sep 12, 2023In this work, we focus on a robotic unloading problem from visual observations, where robots are required to autonomously unload stacks of parcels using RGB-D images as their primary input source. While supervised and imitation learning have accomplished good results in these types of tasks, they heavily rely on labeled data, which are challenging to obtain in realistic scenarios. Our study aims to develop a sample efficient controller framework that can learn unloading tasks without the need for labeled data during the learning process. To tackle this challenge, we propose a hierarchical controller structure that combines a high-level decision-making module with classical motion control. The high-level module is trained using Deep Reinforcement Learning (DRL), wherein we incorporate a safety bias mechanism and design a reward function tailored to this task. Our experiments demonstrate that both these elements play a crucial role in achieving improved learning performance. Furthermore, to ensure reproducibility and establish a benchmark for future research, we provide free access to our code and simulation.
On the Opportunities and Challenges of using Animals Videos in Reinforcement Learning
Sep 27, 2022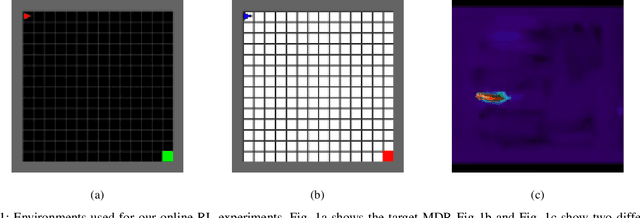
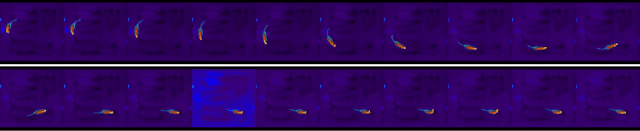
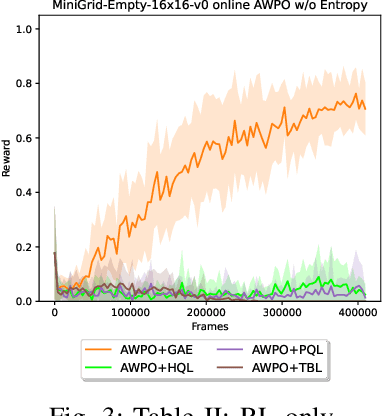
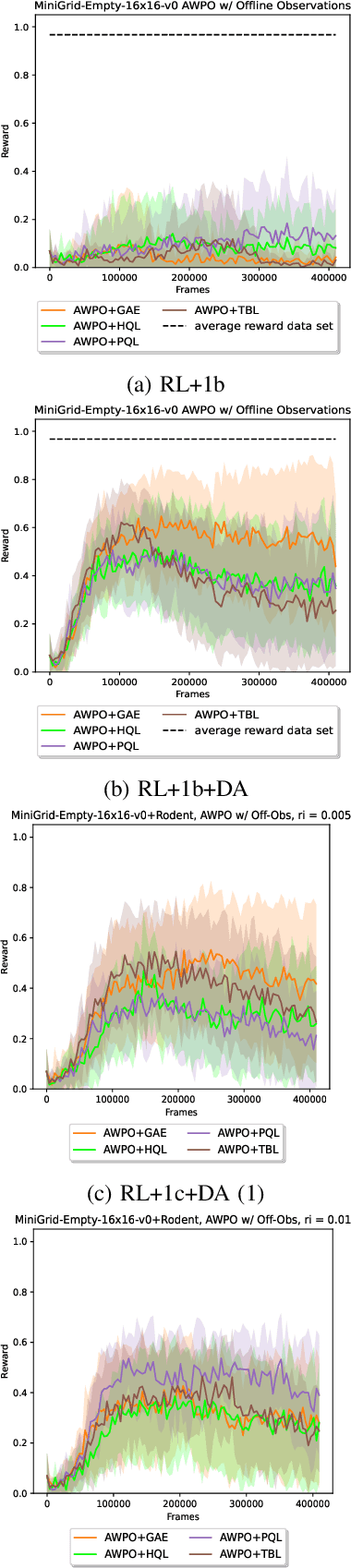
We investigate the use of animals videos to improve efficiency and performance in Reinforcement Learning (RL). Under a theoretical perspective, we motivate the use of weighted policy optimization for off-policy RL, describe the main challenges when learning from videos and propose solutions. We test our ideas in offline and online RL and show encouraging results on a series of 2D navigation tasks.