 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Model-Based Approach for Improving Reinforcement Learning Efficiency Leveraging Expert Observations
Feb 29, 2024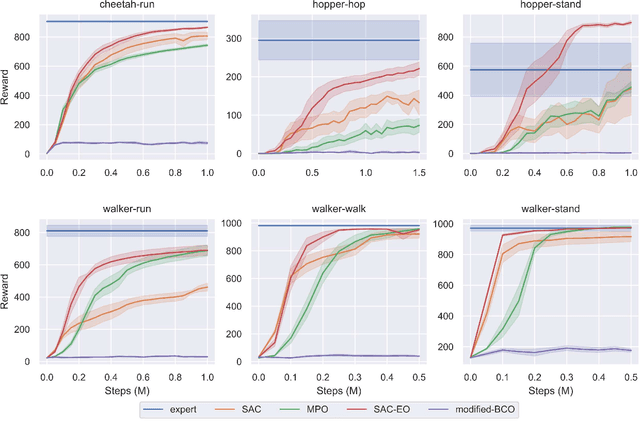
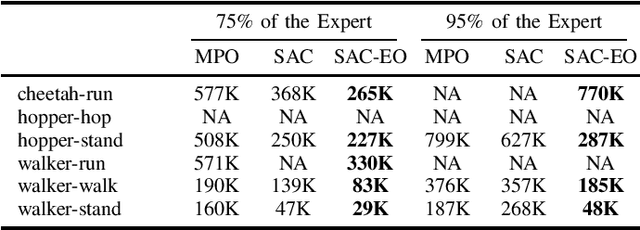


This paper investigates how to incorporate expert observations (without explicit information on expert actions) into a deep reinforcement learning setting to improve sample efficiency. First, we formulate an augmented policy loss combining a maximum entropy reinforcement learning objective with a behavioral cloning loss that leverages a forward dynamics model. Then, we propose an algorithm that automatically adjusts the weights of each component in the augmented loss function. Experiments on a variety of continuous control tasks demonstrate that the proposed algorithm outperforms various benchmarks by effectively utilizing available expert observations.
Smooth Ranking SVM via Cutting-Plane Method
Jan 25, 2024The most popular classification algorithms are designed to maximize classification accuracy during training. However, this strategy may fail in the presence of class imbalance since it is possible to train models with high accuracy by overfitting to the majority class. On the other hand, the Area Under the Curve (AUC) is a widely used metric to compare classification performance of different algorithms when there is a class imbalance, and various approaches focusing on the direct optimization of this metric during training have been proposed. Among them, SVM-based formulations are especially popular as this formulation allows incorporating different regularization strategies easily. In this work, we develop a prototype learning approach that relies on cutting-plane method, similar to Ranking SVM, to maximize AUC. Our algorithm learns simpler models by iteratively introducing cutting planes, thus overfitting is prevented in an unconventional way. Furthermore, it penalizes the changes in the weights at each iteration to avoid large jumps that might be observed in the test performance, thus facilitating a smooth learning process. Based on the experiments conducted on 73 binary classification datasets, our method yields the best test AUC in 25 datasets among its relevant competitors.
Optimal Transport Perturbations for Safe Reinforcement Learning with Robustness Guarantees
Jan 31, 2023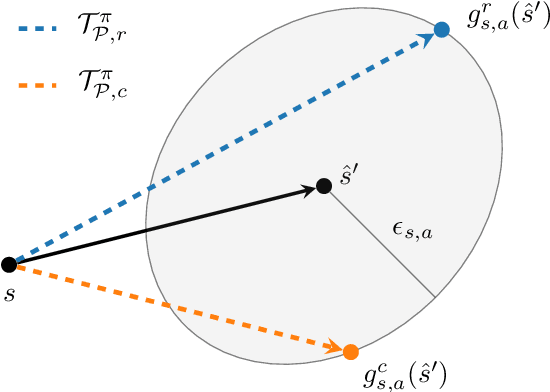
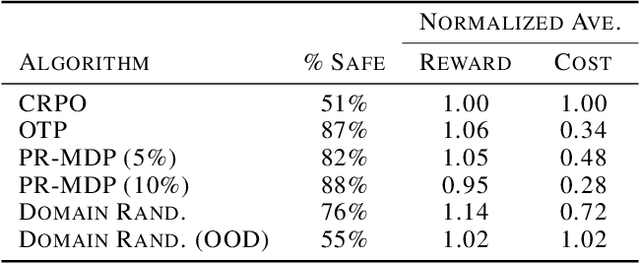
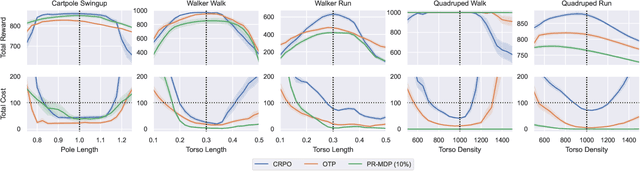
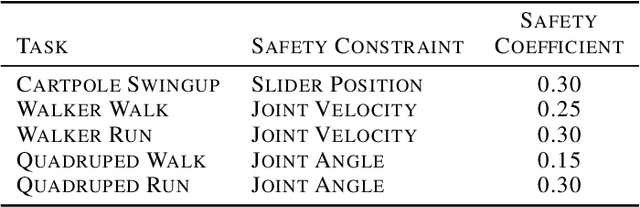
Robustness and safety are critical for the trustworthy deployment of deep reinforcement learning in real-world decision making applications. In particular, we require algorithms that can guarantee robust, safe performance in the presence of general environment disturbances, while making limited assumptions on the data collection process during training. In this work, we propose a safe reinforcement learning framework with robustness guarantees through the use of an optimal transport cost uncertainty set. We provide an efficient, theoretically supported implementation based on Optimal Transport Perturbations, which can be applied in a completely offline fashion using only data collected in a nominal training environment. We demonstrate the robust, safe performance of our approach on a variety of continuous control tasks with safety constraints in the Real-World Reinforcement Learning Suite.