 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning-based Receding Horizon Control using Adaptive Control Barrier Functions for Safety-Critical Systems
Mar 26, 2024Optimal control methods provide solutions to safety-critical problems but easily become intractable. Control Barrier Functions (CBFs) have emerged as a popular technique that facilitates their solution by provably guaranteeing safety, through their forward invariance property, at the expense of some performance loss. This approach involves defining a performance objective alongside CBF-based safety constraints that must always be enforced. Unfortunately, both performance and solution feasibility can be significantly impacted by two key factors: (i) the selection of the cost function and associated parameters, and (ii) the calibration of parameters within the CBF-based constraints, which capture the trade-off between performance and conservativeness. %as well as infeasibility. To address these challenges, we propose a Reinforcement Learning (RL)-based Receding Horizon Control (RHC) approach leveraging Model Predictive Control (MPC) with CBFs (MPC-CBF). In particular, we parameterize our controller and use bilevel optimization, where RL is used to learn the optimal parameters while MPC computes the optimal control input. We validate our method by applying it to the challenging automated merging control problem for Connected and Automated Vehicles (CAVs) at conflicting roadways. Results demonstrate improved performance and a significant reduction in the number of infeasible cases compared to traditional heuristic approaches used for tuning CBF-based controllers, showcasing the effectiveness of the proposed method.
Trust-Aware Resilient Control and Coordination of Connected and Automated Vehicles
Jun 03, 2023


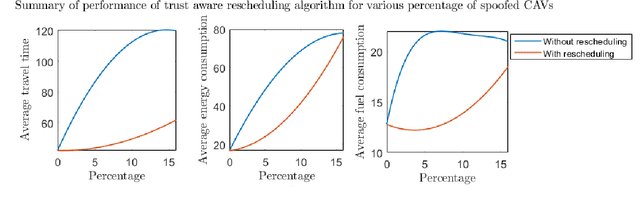
We address the security of a network of Connected and Automated Vehicles (CAVs) cooperating to navigate through a conflict area. Adversarial attacks such as Sybil attacks can cause safety violations resulting in collisions and traffic jams. In addition, uncooperative (but not necessarily adversarial) CAVs can also induce similar adversarial effects on the traffic network. We propose a decentralized resilient control and coordination scheme that mitigates the effects of adversarial attacks and uncooperative CAVs by utilizing a trust framework. Our trust-aware scheme can guarantee safe collision free coordination and mitigate traffic jams. Simulation results validate the theoretical guarantee of our proposed scheme, and demonstrate that it can effectively mitigate adversarial effects across different traffic scenarios.
Optimal Control of Connected Automated Vehicles with Event-Triggered Control Barrier Functions: a Test Bed for Safe Optimal Merging
Jun 02, 2023



We address the problem of controlling Connected and Automated Vehicles (CAVs) in conflict areas of a traffic network subject to hard safety constraints. It has been shown that such problems can be solved through a combination of tractable optimal control problems and Control Barrier Functions (CBFs) that guarantee the satisfaction of all constraints. These solutions can be reduced to a sequence of Quadratic Programs (QPs) which are efficiently solved on line over discrete time steps. However, guaranteeing the feasibility of the CBF-based QP method within each discretized time interval requires the careful selection of time steps which need to be sufficiently small. This creates computational requirements and communication rates between agents which may hinder the controller's application to real CAVs. In this paper, we overcome this limitation by adopting an event-triggered approach for CAVs in a conflict area such that the next QP is triggered by properly defined events with a safety guarantee. We present a laboratory-scale test bed we have developed to emulate merging roadways using mobile robots as CAVs which can be used to demonstrate how the event-triggered scheme is computationally efficient and can handle measurement uncertainties and noise compared to time-driven control while guaranteeing safety.
Learning Feasibility Constraints for Control Barrier Functions
Mar 10, 2023
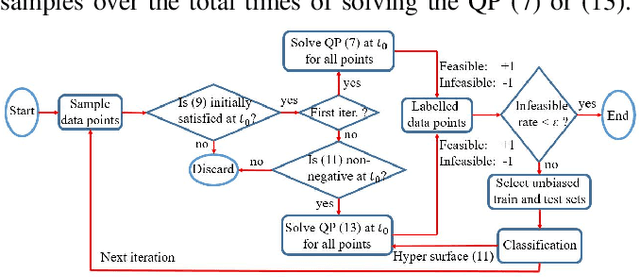
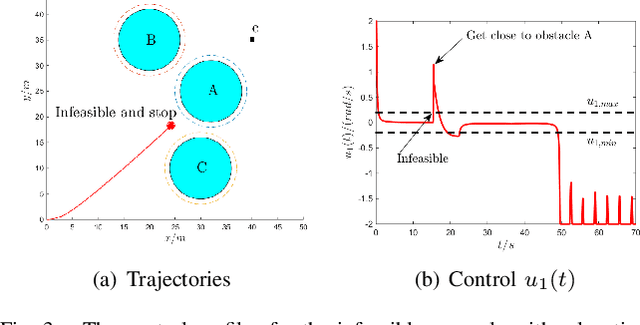
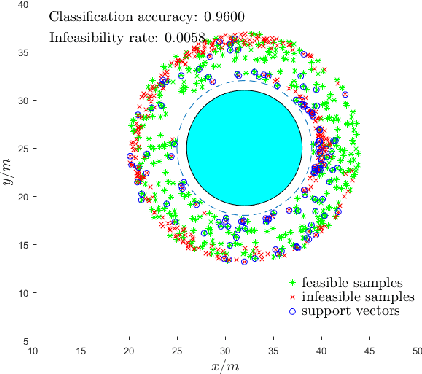
It has been shown that optimizing quadratic costs while stabilizing affine control systems to desired (sets of) states subject to state and control constraints can be reduced to a sequence of Quadratic Programs (QPs) by using Control Barrier Functions (CBFs) and Control Lyapunov Functions (CLFs). In this paper, we employ machine learning techniques to ensure the feasibility of these QPs, which is a challenging problem, especially for high relative degree constraints where High Order CBFs (HOCBFs) are required. To this end, we propose a sampling-based learning approach to learn a new feasibility constraint for CBFs; this constraint is then enforced by another HOCBF added to the QPs. The accuracy of the learned feasibility constraint is recursively improved by a recurrent training algorithm. We demonstrate the advantages of the proposed learning approach to constrained optimal control problems with specific focus on a robot control problem and on autonomous driving in an unknown environment.
Optimal Transport Perturbations for Safe Reinforcement Learning with Robustness Guarantees
Jan 31, 2023Robustness and safety are critical for the trustworthy deployment of deep reinforcement learning in real-world decision making applications. In particular, we require algorithms that can guarantee robust, safe performance in the presence of general environment disturbances, while making limited assumptions on the data collection process during training. In this work, we propose a safe reinforcement learning framework with robustness guarantees through the use of an optimal transport cost uncertainty set. We provide an efficient, theoretically supported implementation based on Optimal Transport Perturbations, which can be applied in a completely offline fashion using only data collected in a nominal training environment. We demonstrate the robust, safe performance of our approach on a variety of continuous control tasks with safety constraints in the Real-World Reinforcement Learning Suite.
Cooperative Energy and Time-Optimal Lane Change Maneuvers with Minimal Highway Traffic Disruption
Nov 16, 2022



We derive optimal control policies for a Connected Automated Vehicle (CAV) and cooperating neighboring CAVs to carry out a lane change maneuver consisting of a longitudinal phase where the CAV properly positions itself relative to the cooperating neighbors and a lateral phase where it safely changes lanes. In contrast to prior work on this problem, where the CAV "selfishly" only seeks to minimize its maneuver time, we seek to ensure that the fast-lane traffic flow is minimally disrupted (through a properly defined metric). Additionally, when performing lane-changing maneuvers, we optimally select the cooperating vehicles from a set of feasible neighboring vehicles and experimentally show that the highway throughput is improved compared to the baseline case of human-driven vehicles changing lanes with no cooperation. When feasible solutions do not exist for a given maximal allowable disruption, we include a time relaxation method trading off a longer maneuver time with reduced disruption. Our analysis is also extended to multiple sequential maneuvers. Simulation results show the effectiveness of our controllers in terms of safety guarantees and up to 16% and 90% average throughput and maneuver time improvement respectively when compared to maneuvers with no cooperation.
A Graph-Based Approach to Generate Energy-Optimal Robot Trajectories in Polygonal Environments
Nov 11, 2022



As robotic systems continue to address emerging issues in areas such as logistics, mobility, manufacturing, and disaster response, it is increasingly important to rapidly generate safe and energy-efficient trajectories. In this article, we present a new approach to plan energy-optimal trajectories through cluttered environments containing polygonal obstacles. In particular, we develop a method to quickly generate optimal trajectories for a double-integrator system, and we show that optimal path planning reduces to an integer program. To find an efficient solution, we present a distance-informed prefix search to efficiently generate optimal trajectories for a large class of environments. We demonstrate that our approach, while matching the performance of RRT* and Probabilistic Road Maps in terms of path length, outperforms both in terms of energy cost and computational time by up to an order of magnitude. We also demonstrate that our approach yields implementable trajectories in an experiment with a Crazyflie quadrotor.
Generalized Policy Improvement Algorithms with Theoretically Supported Sample Reuse
Jun 28, 2022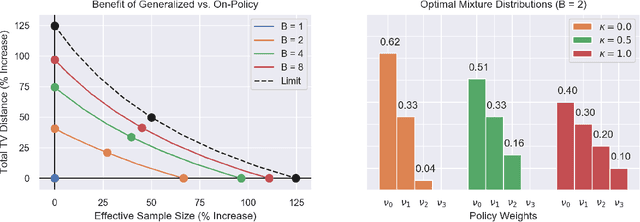

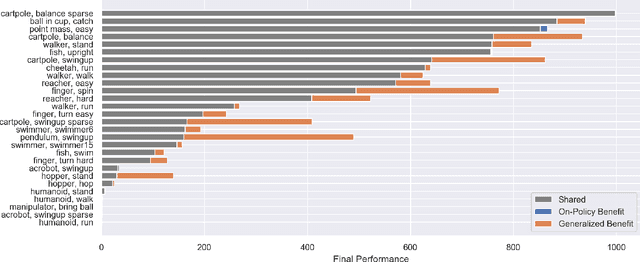
Real-world sequential decision making requires data-driven algorithms that provide practical guarantees on performance throughout training while also making efficient use of data. Model-free deep reinforcement learning represents a framework for such data-driven decision making, but existing algorithms typically only focus on one of these goals while sacrificing performance with respect to the other. On-policy algorithms guarantee policy improvement throughout training but suffer from high sample complexity, while off-policy algorithms make efficient use of data through sample reuse but lack theoretical guarantees. In order to balance these competing goals, we develop a class of Generalized Policy Improvement algorithms that combines the policy improvement guarantees of on-policy methods with the efficiency of theoretically supported sample reuse. We demonstrate the benefits of this new class of algorithms through extensive experimental analysis on a variety of continuous control tasks from the DeepMind Control Suite.
Control Barrier Functions for Systems with Multiple Control Inputs
Mar 15, 2022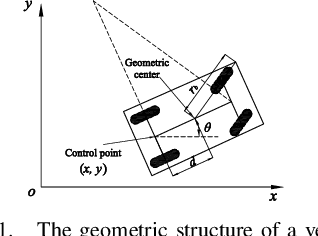
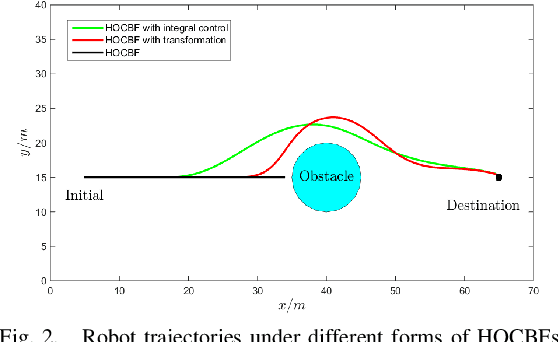
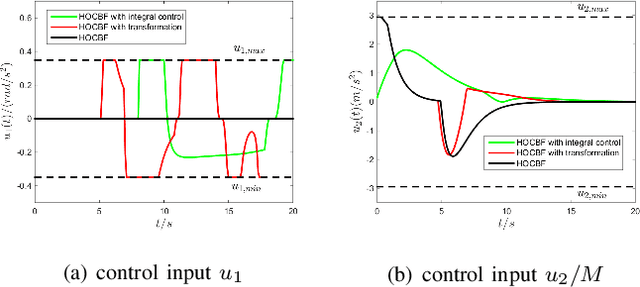
Control Barrier Functions (CBFs) are becoming popular tools in guaranteeing safety for nonlinear systems and constraints, and they can reduce a constrained optimal control problem into a sequence of Quadratic Programs (QPs) for affine control systems. The recently proposed High Order Control Barrier Functions (HOCBFs) work for arbitrary relative degree constraints. One of the challenges in a HOCBF is to address the relative degree problem when a system has multiple control inputs, i.e., the relative degree could be defined with respect to different components of the control vector. This paper proposes two methods for HOCBFs to deal with systems with multiple control inputs: a general integral control method and a method which is simpler but limited to specific classes of physical systems. When control bounds are involved, the feasibility of the above mentioned QPs can also be significantly improved with the proposed methods. We illustrate our approaches on a unicyle model with two control inputs, and compare the two proposed methods to demonstrate their effectiveness and performance.
Generalized Proximal Policy Optimization with Sample Reuse
Oct 29, 2021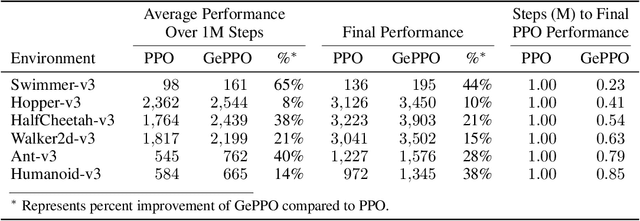
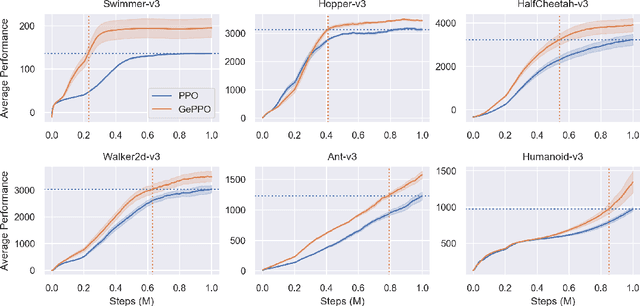

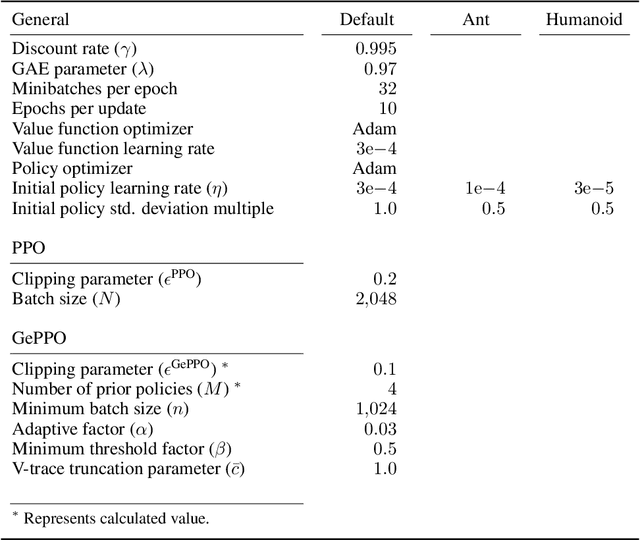
In real-world decision making tasks, it is critical for data-driven reinforcement learning methods to be both stable and sample efficient. On-policy methods typically generate reliable policy improvement throughout training, while off-policy methods make more efficient use of data through sample reuse. In this work, we combine the theoretically supported stability benefits of on-policy algorithms with the sample efficiency of off-policy algorithms. We develop policy improvement guarantees that are suitable for the off-policy setting, and connect these bounds to the clipping mechanism used in Proximal Policy Optimization. This motivates an off-policy version of the popular algorithm that we call Generalized Proximal Policy Optimization with Sample Reuse. We demonstrate both theoretically and empirically that our algorithm delivers improved performance by effectively balancing the competing goals of stability and sample efficiency.