 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralized Policy Improvement Algorithms with Theoretically Supported Sample Reuse
Paper and Code
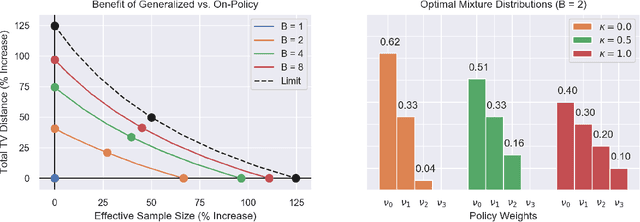

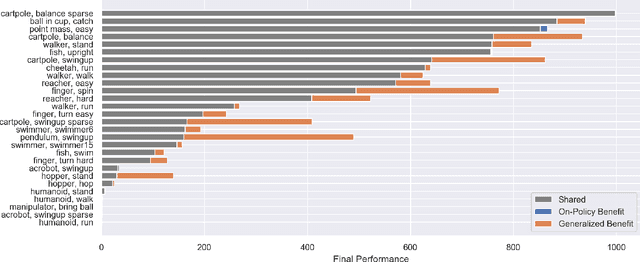
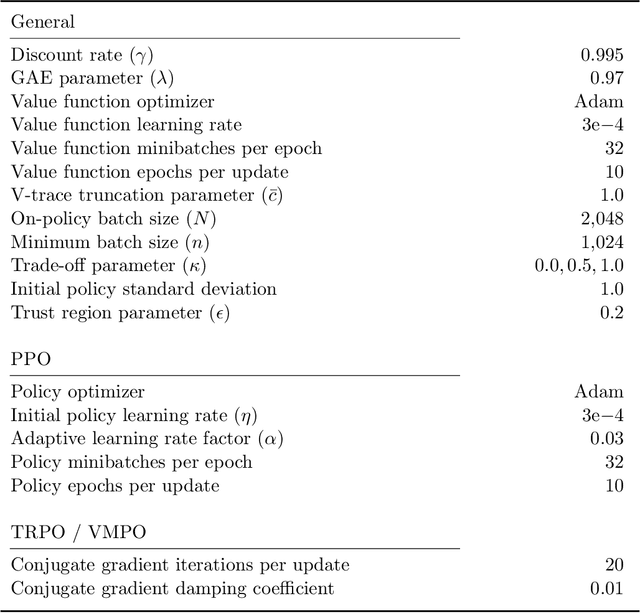
Real-world sequential decision making requires data-driven algorithms that provide practical guarantees on performance throughout training while also making efficient use of data. Model-free deep reinforcement learning represents a framework for such data-driven decision making, but existing algorithms typically only focus on one of these goals while sacrificing performance with respect to the other. On-policy algorithms guarantee policy improvement throughout training but suffer from high sample complexity, while off-policy algorithms make efficient use of data through sample reuse but lack theoretical guarantees. In order to balance these competing goals, we develop a class of Generalized Policy Improvement algorithms that combines the policy improvement guarantees of on-policy methods with the efficiency of theoretically supported sample reuse. We demonstrate the benefits of this new class of algorithms through extensive experimental analysis on a variety of continuous control tasks from the DeepMind Control Suite.