 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Diversity in Large Language Models via Determinantal Point Processes
Sep 05, 2025Supervised fine-tuning and reinforcement learning are two popular methods for post-training large language models (LLMs). While improving the model's performance on downstream tasks, they often reduce the model's output diversity, leading to narrow, canonical responses. Existing methods to enhance diversity are limited, either by operating at inference time or by focusing on lexical differences. We propose a novel training method named DQO based on determinantal point processes (DPPs) to jointly optimize LLMs for quality and semantic diversity. Our approach samples and embeds a group of responses for each prompt, then uses the determinant of a kernel-based similarity matrix to measure diversity as the volume spanned by the embeddings of these responses. Experiments across instruction-following, summarization, story generation, and reasoning tasks demonstrate that our method substantially improves semantic diversity without sacrificing model quality.
Geometric Re-Analysis of Classical MDP Solving Algorithms
Mar 06, 2025We build on a recently introduced geometric interpretation of Markov Decision Processes (MDPs) to analyze classical MDP-solving algorithms: Value Iteration (VI) and Policy Iteration (PI). First, we develop a geometry-based analytical apparatus, including a transformation that modifies the discount factor $\gamma$, to improve convergence guarantees for these algorithms in several settings. In particular, one of our results identifies a rotation component in the VI method, and as a consequence shows that when a Markov Reward Process (MRP) induced by the optimal policy is irreducible and aperiodic, the asymptotic convergence rate of value iteration is strictly smaller than $\gamma$.
Analysis of Value Iteration Through Absolute Probability Sequences
Feb 05, 2025Value Iteration is a widely used algorithm for solving Markov Decision Processes (MDPs). While previous studies have extensively analyzed its convergence properties, they primarily focus on convergence with respect to the infinity norm. In this work, we use absolute probability sequences to develop a new line of analysis and examine the algorithm's convergence in terms of the $L^2$ norm, offering a new perspective on its behavior and performance.
MDP Geometry, Normalization and Value Free Solvers
Jul 09, 2024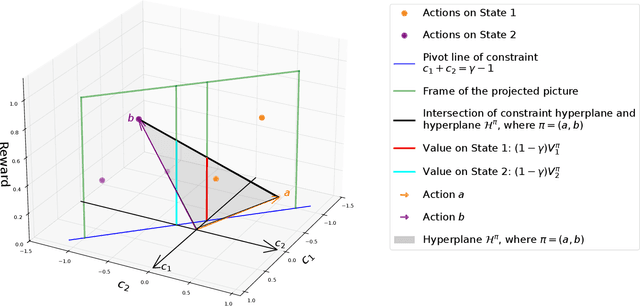
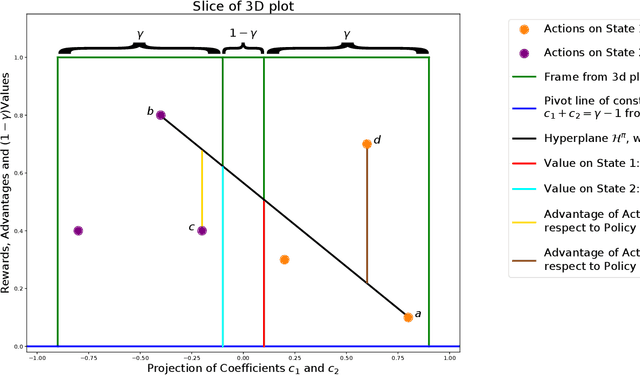
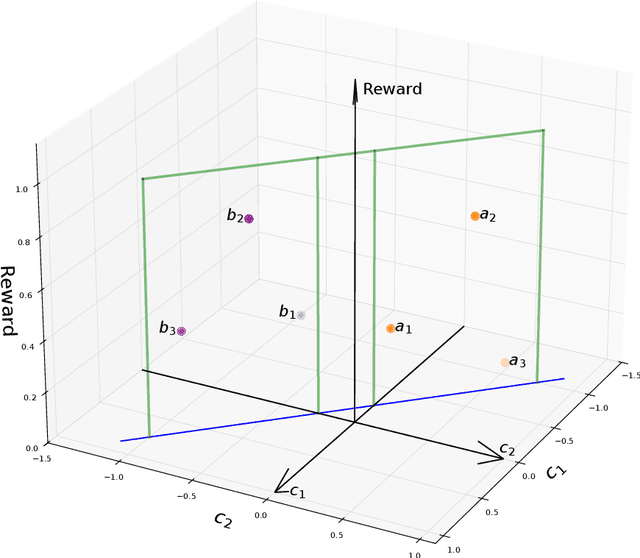
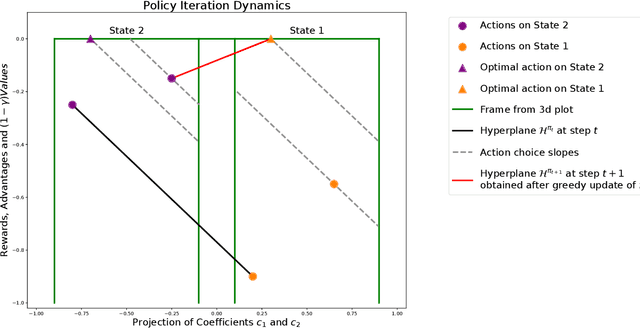
Markov Decision Process (MDP) is a common mathematical model for sequential decision-making problems. In this paper, we present a new geometric interpretation of MDP, which is useful for analyzing the dynamics of main MDP algorithms. Based on this interpretation, we demonstrate that MDPs can be split into equivalence classes with indistinguishable algorithm dynamics. The related normalization procedure allows for the design of a new class of MDP-solving algorithms that find optimal policies without computing policy values.
On Value Iteration Convergence in Connected MDPs
Jun 13, 2024
This paper establishes that an MDP with a unique optimal policy and ergodic associated transition matrix ensures the convergence of various versions of the Value Iteration algorithm at a geometric rate that exceeds the discount factor {\gamma} for both discounted and average-reward criteria.
Provably Efficient Off-Policy Adversarial Imitation Learning with Convergence Guarantees
May 26, 2024

Adversarial Imitation Learning (AIL) faces challenges with sample inefficiency because of its reliance on sufficient on-policy data to evaluate the performance of the current policy during reward function updates. In this work, we study the convergence properties and sample complexity of off-policy AIL algorithms. We show that, even in the absence of importance sampling correction, reusing samples generated by the $o(\sqrt{K})$ most recent policies, where $K$ is the number of iterations of policy updates and reward updates, does not undermine the convergence guarantees of this class of algorithms. Furthermore, our results indicate that the distribution shift error induced by off-policy updates is dominated by the benefits of having more data available. This result provides theoretical support for the sample efficiency of off-policy AIL algorithms. To the best of our knowledge, this is the first work that provides theoretical guarantees for off-policy AIL algorithms.
Multiple-policy Evaluation via Density Estimation
Mar 29, 2024In this work, we focus on the multiple-policy evaluation problem where we are given a set of $K$ target policies and the goal is to evaluate their performance (the expected total rewards) to an accuracy $\epsilon$ with probability at least $1-\delta$. We propose an algorithm named $\mathrm{CAESAR}$ to address this problem. Our approach is based on computing an approximate optimal offline sampling distribution and using the data sampled from it to perform the simultaneous estimation of the policy values. $\mathrm{CAESAR}$ consists of two phases. In the first one we produce coarse estimates of the vistation distributions of the target policies at a low order sample complexity rate that scales with $\tilde{O}(\frac{1}{\epsilon})$. In the second phase, we approximate the optimal offline sampling distribution and compute the importance weighting ratios for all target policies by minimizing a step-wise quadratic loss function inspired by the objective in DualDICE. Up to low order and logarithm terms $\mathrm{CAESAR}$ achieves a sample complexity $\tilde{O}\left(\frac{H^4}{\epsilon^2}\sum_{h=1}^H\max_{k\in[K]}\sum_{s,a}\frac{(d_h^{\pi^k}(s,a))^2}{\mu^*_h(s,a)}\right)$, where $d^{\pi}$ is the visitation distribution of policy $\pi$ and $\mu^*$ is the optimal sampling distribution.
Reinforcement Learning-based Receding Horizon Control using Adaptive Control Barrier Functions for Safety-Critical Systems
Mar 26, 2024Optimal control methods provide solutions to safety-critical problems but easily become intractable. Control Barrier Functions (CBFs) have emerged as a popular technique that facilitates their solution by provably guaranteeing safety, through their forward invariance property, at the expense of some performance loss. This approach involves defining a performance objective alongside CBF-based safety constraints that must always be enforced. Unfortunately, both performance and solution feasibility can be significantly impacted by two key factors: (i) the selection of the cost function and associated parameters, and (ii) the calibration of parameters within the CBF-based constraints, which capture the trade-off between performance and conservativeness. %as well as infeasibility. To address these challenges, we propose a Reinforcement Learning (RL)-based Receding Horizon Control (RHC) approach leveraging Model Predictive Control (MPC) with CBFs (MPC-CBF). In particular, we parameterize our controller and use bilevel optimization, where RL is used to learn the optimal parameters while MPC computes the optimal control input. We validate our method by applying it to the challenging automated merging control problem for Connected and Automated Vehicles (CAVs) at conflicting roadways. Results demonstrate improved performance and a significant reduction in the number of infeasible cases compared to traditional heuristic approaches used for tuning CBF-based controllers, showcasing the effectiveness of the proposed method.
One-Shot Averaging for Distributed TD Under Markov Sampling
Mar 13, 2024We consider a distributed setup for reinforcement learning, where each agent has a copy of the same Markov Decision Process but transitions are sampled from the corresponding Markov chain independently by each agent. We show that in this setting, we can achieve a linear speedup for TD($\lambda$), a family of popular methods for policy evaluation, in the sense that $N$ agents can evaluate a policy $N$ times faster provided the target accuracy is small enough. Notably, this speedup is achieved by ``one shot averaging,'' a procedure where the agents run TD($\lambda$) with Markov sampling independently and only average their results after the final step. This significantly reduces the amount of communication required to achieve a linear speedup relative to previous work.
A Model-Based Approach for Improving Reinforcement Learning Efficiency Leveraging Expert Observations
Feb 29, 2024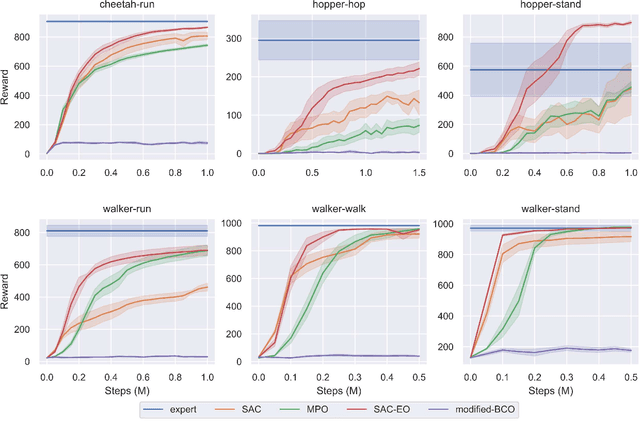
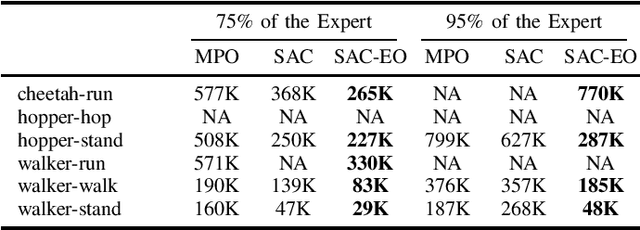


This paper investigates how to incorporate expert observations (without explicit information on expert actions) into a deep reinforcement learning setting to improve sample efficiency. First, we formulate an augmented policy loss combining a maximum entropy reinforcement learning objective with a behavioral cloning loss that leverages a forward dynamics model. Then, we propose an algorithm that automatically adjusts the weights of each component in the augmented loss function. Experiments on a variety of continuous control tasks demonstrate that the proposed algorithm outperforms various benchmarks by effectively utilizing available expert observations.