 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging the Gap Between Average and Discounted TD Learning
May 03, 2026The analysis of Temporal Difference (TD) learning in the average-reward setting faces notable theoretical difficulties because the Bellman operator is not contractive with respect to any norm. This complicates standard analyses of stochastic updates that are effective in discounted settings. Although a considerable body of literature addresses these challenges, existing theoretical approaches come with limitations. We introduce a novel algorithm designed explicitly for policy evaluation in the average-reward setting, utilizing sampling from two Markovian trajectories. Our proposed method overcomes previous limitations by guaranteeing convergence to the unique solution of a properly defined projected Bellman equation. Notably, and in contrast to earlier work, our convergence analysis is uniformly applicable to both linear function approximation and tabular settings and does not involve explicit dimension-dependent terms in its convergence bounds. These results align with what is known to hold in the discounted setting. Furthermore, our algorithm achieves improved dependence on the problem's condition number, reducing the sample complexity from quartic, as in prior literature, to quadratic scaling, and thus matching the efficiency seen in the discounted setting.
Geometric Re-Analysis of Classical MDP Solving Algorithms
Mar 06, 2025We build on a recently introduced geometric interpretation of Markov Decision Processes (MDPs) to analyze classical MDP-solving algorithms: Value Iteration (VI) and Policy Iteration (PI). First, we develop a geometry-based analytical apparatus, including a transformation that modifies the discount factor $\gamma$, to improve convergence guarantees for these algorithms in several settings. In particular, one of our results identifies a rotation component in the VI method, and as a consequence shows that when a Markov Reward Process (MRP) induced by the optimal policy is irreducible and aperiodic, the asymptotic convergence rate of value iteration is strictly smaller than $\gamma$.
Sample Complexity of Linear Quadratic Regulator Without Initial Stability
Feb 20, 2025

Inspired by REINFORCE, we introduce a novel receding-horizon algorithm for the Linear Quadratic Regulator (LQR) problem with unknown parameters. Unlike prior methods, our algorithm avoids reliance on two-point gradient estimates while maintaining the same order of sample complexity. Furthermore, it eliminates the restrictive requirement of starting with a stable initial policy, broadening its applicability. Beyond these improvements, we introduce a refined analysis of error propagation through the contraction of the Riemannian distance over the Riccati operator. This refinement leads to a better sample complexity and ensures improved convergence guarantees. Numerical simulations validate the theoretical results, demonstrating the method's practical feasibility and performance in realistic scenarios.
Analysis of Value Iteration Through Absolute Probability Sequences
Feb 05, 2025Value Iteration is a widely used algorithm for solving Markov Decision Processes (MDPs). While previous studies have extensively analyzed its convergence properties, they primarily focus on convergence with respect to the infinity norm. In this work, we use absolute probability sequences to develop a new line of analysis and examine the algorithm's convergence in terms of the $L^2$ norm, offering a new perspective on its behavior and performance.
MDP Geometry, Normalization and Value Free Solvers
Jul 09, 2024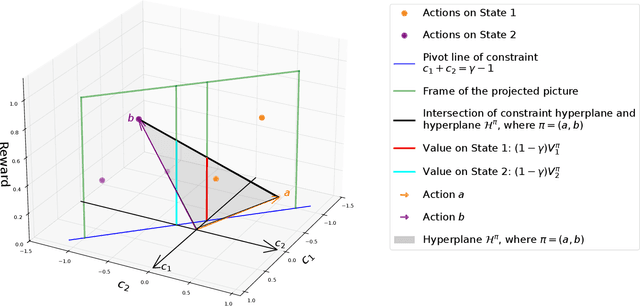
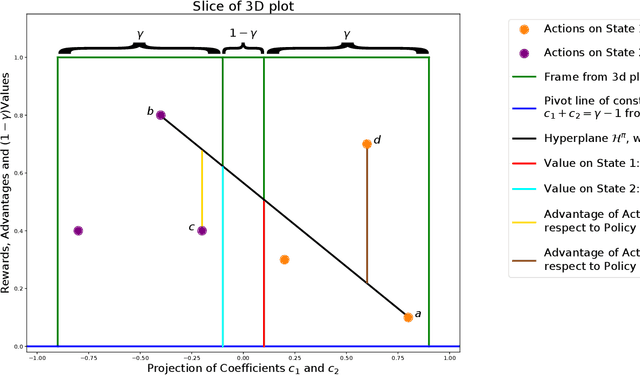
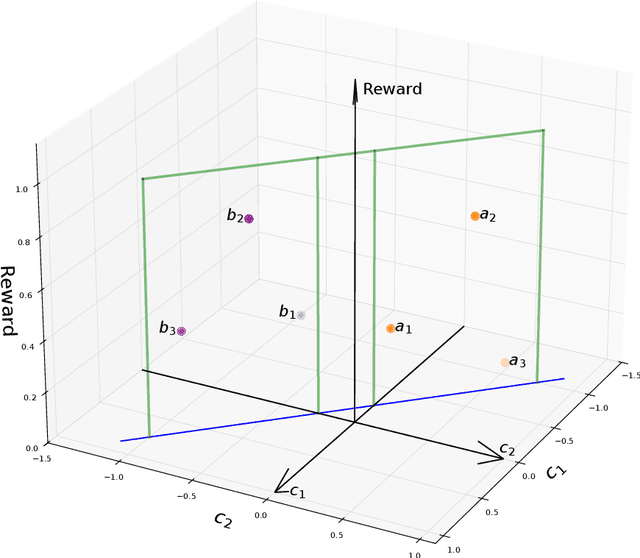
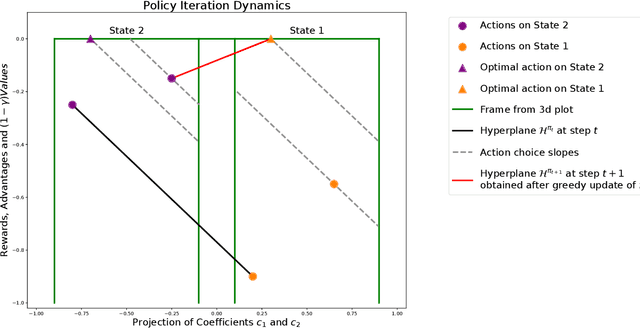
Markov Decision Process (MDP) is a common mathematical model for sequential decision-making problems. In this paper, we present a new geometric interpretation of MDP, which is useful for analyzing the dynamics of main MDP algorithms. Based on this interpretation, we demonstrate that MDPs can be split into equivalence classes with indistinguishable algorithm dynamics. The related normalization procedure allows for the design of a new class of MDP-solving algorithms that find optimal policies without computing policy values.
Tree Search for Simultaneous Move Games via Equilibrium Approximation
Jun 14, 2024



Neural network supported tree-search has shown strong results in a variety of perfect information multi-agent tasks. However, the performance of these methods on partial information games has generally been below competing approaches. Here we study the class of simultaneous-move games, which are a subclass of partial information games which are most similar to perfect information games: both agents know the game state with the exception of the opponent's move, which is revealed only after each agent makes its own move. Simultaneous move games include popular benchmarks such as Google Research Football and Starcraft. In this study we answer the question: can we take tree search algorithms trained through self-play from perfect information settings and adapt them to simultaneous move games without significant loss of performance? We answer this question by deriving a practical method that attempts to approximate a coarse correlated equilibrium as a subroutine within a tree search. Our algorithm works on cooperative, competitive, and mixed tasks. Our results are better than the current best MARL algorithms on a wide range of accepted baseline environments.
On Value Iteration Convergence in Connected MDPs
Jun 13, 2024
This paper establishes that an MDP with a unique optimal policy and ergodic associated transition matrix ensures the convergence of various versions of the Value Iteration algorithm at a geometric rate that exceeds the discount factor {\gamma} for both discounted and average-reward criteria.
Sample Complexity of the Linear Quadratic Regulator: A Reinforcement Learning Lens
Apr 18, 2024

We provide the first known algorithm that provably achieves $\varepsilon$-optimality within $\widetilde{\mathcal{O}}(1/\varepsilon)$ function evaluations for the discounted discrete-time LQR problem with unknown parameters, without relying on two-point gradient estimates. These estimates are known to be unrealistic in many settings, as they depend on using the exact same initialization, which is to be selected randomly, for two different policies. Our results substantially improve upon the existing literature outside the realm of two-point gradient estimates, which either leads to $\widetilde{\mathcal{O}}(1/\varepsilon^2)$ rates or heavily relies on stability assumptions.
One-Shot Averaging for Distributed TD Under Markov Sampling
Mar 13, 2024We consider a distributed setup for reinforcement learning, where each agent has a copy of the same Markov Decision Process but transitions are sampled from the corresponding Markov chain independently by each agent. We show that in this setting, we can achieve a linear speedup for TD($\lambda$), a family of popular methods for policy evaluation, in the sense that $N$ agents can evaluate a policy $N$ times faster provided the target accuracy is small enough. Notably, this speedup is achieved by ``one shot averaging,'' a procedure where the agents run TD($\lambda$) with Markov sampling independently and only average their results after the final step. This significantly reduces the amount of communication required to achieve a linear speedup relative to previous work.
Convex SGD: Generalization Without Early Stopping
Jan 08, 2024We consider the generalization error associated with stochastic gradient descent on a smooth convex function over a compact set. We show the first bound on the generalization error that vanishes when the number of iterations $T$ and the dataset size $n$ go to zero at arbitrary rates; our bound scales as $\tilde{O}(1/\sqrt{T} + 1/\sqrt{n})$ with step-size $\alpha_t = 1/\sqrt{t}$. In particular, strong convexity is not needed for stochastic gradient descent to generalize well.