 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeErgodicity in reinforcement learning
Mar 11, 2026In reinforcement learning, we typically aim to optimize the expected value of the sum of rewards an agent collects over a trajectory. However, if the process generating these rewards is non-ergodic, the expected value, i.e., the average over infinitely many trajectories with a given policy, is uninformative for the average over a single, but infinitely long trajectory. Thus, if we care about how the individual agent performs during deployment, the expected value is not a good optimization objective. In this paper, we discuss the impact of non-ergodic reward processes on reinforcement learning agents through an instructive example, relate the notion of ergodic reward processes to more widely used notions of ergodic Markov chains, and present existing solutions that optimize long-term performance of individual trajectories under non-ergodic reward dynamics.
Geometric Re-Analysis of Classical MDP Solving Algorithms
Mar 06, 2025We build on a recently introduced geometric interpretation of Markov Decision Processes (MDPs) to analyze classical MDP-solving algorithms: Value Iteration (VI) and Policy Iteration (PI). First, we develop a geometry-based analytical apparatus, including a transformation that modifies the discount factor $\gamma$, to improve convergence guarantees for these algorithms in several settings. In particular, one of our results identifies a rotation component in the VI method, and as a consequence shows that when a Markov Reward Process (MRP) induced by the optimal policy is irreducible and aperiodic, the asymptotic convergence rate of value iteration is strictly smaller than $\gamma$.
Analysis of Value Iteration Through Absolute Probability Sequences
Feb 05, 2025Value Iteration is a widely used algorithm for solving Markov Decision Processes (MDPs). While previous studies have extensively analyzed its convergence properties, they primarily focus on convergence with respect to the infinity norm. In this work, we use absolute probability sequences to develop a new line of analysis and examine the algorithm's convergence in terms of the $L^2$ norm, offering a new perspective on its behavior and performance.
MDP Geometry, Normalization and Value Free Solvers
Jul 09, 2024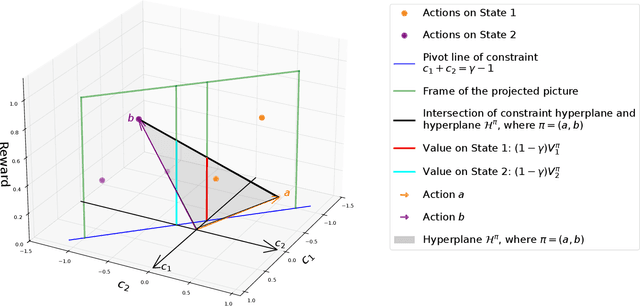
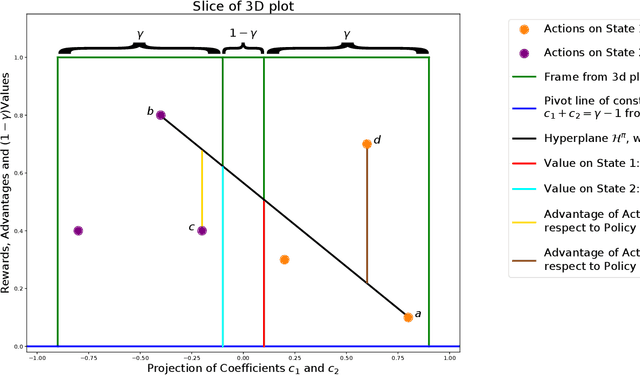
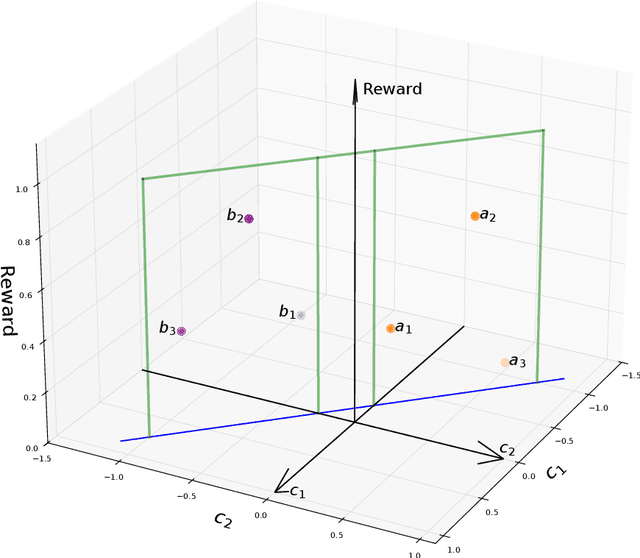
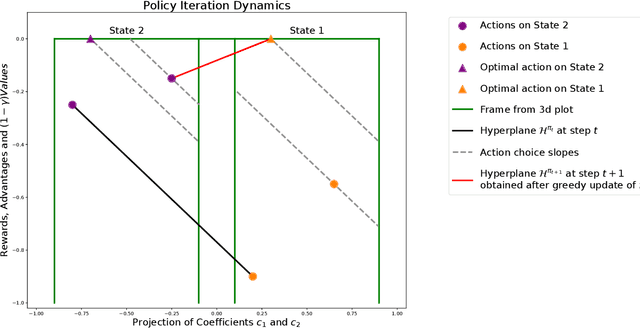
Markov Decision Process (MDP) is a common mathematical model for sequential decision-making problems. In this paper, we present a new geometric interpretation of MDP, which is useful for analyzing the dynamics of main MDP algorithms. Based on this interpretation, we demonstrate that MDPs can be split into equivalence classes with indistinguishable algorithm dynamics. The related normalization procedure allows for the design of a new class of MDP-solving algorithms that find optimal policies without computing policy values.
On Value Iteration Convergence in Connected MDPs
Jun 13, 2024
This paper establishes that an MDP with a unique optimal policy and ergodic associated transition matrix ensures the convergence of various versions of the Value Iteration algorithm at a geometric rate that exceeds the discount factor {\gamma} for both discounted and average-reward criteria.
Closing the gap between SVRG and TD-SVRG with Gradient Splitting
Nov 29, 2022Temporal difference (TD) learning is a simple algorithm for policy evaluation in reinforcement learning. The performance of TD learning is affected by high variance and it can be naturally enhanced with variance reduction techniques, such as the Stochastic Variance Reduced Gradient (SVRG) method. Recently, multiple works have sought to fuse TD learning with SVRG to obtain a policy evaluation method with a geometric rate of convergence. However, the resulting convergence rate is significantly weaker than what is achieved by SVRG in the setting of convex optimization. In this work we utilize a recent interpretation of TD-learning as the splitting of the gradient of an appropriately chosen function, thus simplifying the algorithm and fusing TD with SVRG. We prove a geometric convergence bound with predetermined learning rate of 1/8, that is identical to the convergence bound available for SVRG in the convex setting.