 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometric Re-Analysis of Classical MDP Solving Algorithms
Mar 06, 2025We build on a recently introduced geometric interpretation of Markov Decision Processes (MDPs) to analyze classical MDP-solving algorithms: Value Iteration (VI) and Policy Iteration (PI). First, we develop a geometry-based analytical apparatus, including a transformation that modifies the discount factor $\gamma$, to improve convergence guarantees for these algorithms in several settings. In particular, one of our results identifies a rotation component in the VI method, and as a consequence shows that when a Markov Reward Process (MRP) induced by the optimal policy is irreducible and aperiodic, the asymptotic convergence rate of value iteration is strictly smaller than $\gamma$.
MDP Geometry, Normalization and Value Free Solvers
Jul 09, 2024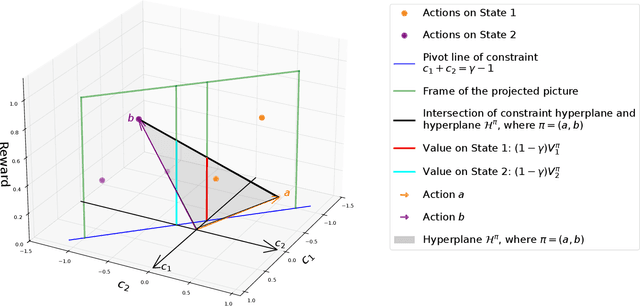
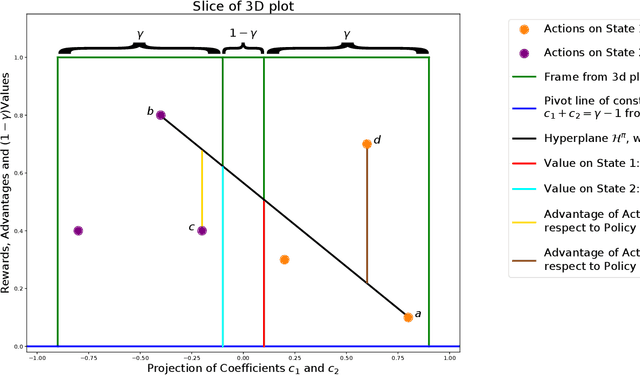
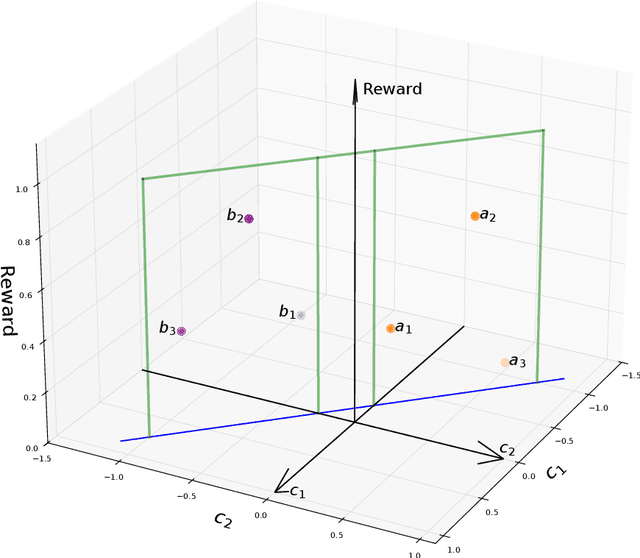
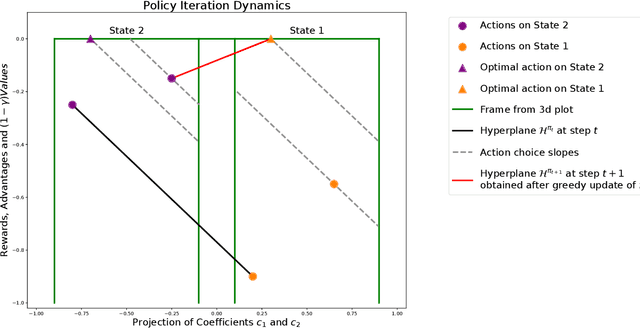
Markov Decision Process (MDP) is a common mathematical model for sequential decision-making problems. In this paper, we present a new geometric interpretation of MDP, which is useful for analyzing the dynamics of main MDP algorithms. Based on this interpretation, we demonstrate that MDPs can be split into equivalence classes with indistinguishable algorithm dynamics. The related normalization procedure allows for the design of a new class of MDP-solving algorithms that find optimal policies without computing policy values.