 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSample Complexity of Linear Quadratic Regulator Without Initial Stability
Feb 20, 2025
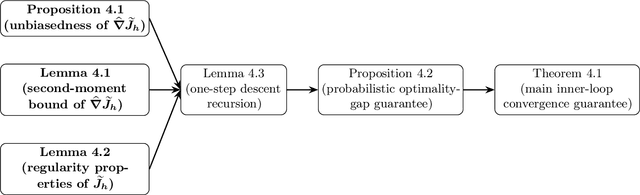

Inspired by REINFORCE, we introduce a novel receding-horizon algorithm for the Linear Quadratic Regulator (LQR) problem with unknown parameters. Unlike prior methods, our algorithm avoids reliance on two-point gradient estimates while maintaining the same order of sample complexity. Furthermore, it eliminates the restrictive requirement of starting with a stable initial policy, broadening its applicability. Beyond these improvements, we introduce a refined analysis of error propagation through the contraction of the Riemannian distance over the Riccati operator. This refinement leads to a better sample complexity and ensures improved convergence guarantees. Numerical simulations validate the theoretical results, demonstrating the method's practical feasibility and performance in realistic scenarios.
Sample Complexity of the Linear Quadratic Regulator: A Reinforcement Learning Lens
Apr 18, 2024

We provide the first known algorithm that provably achieves $\varepsilon$-optimality within $\widetilde{\mathcal{O}}(1/\varepsilon)$ function evaluations for the discounted discrete-time LQR problem with unknown parameters, without relying on two-point gradient estimates. These estimates are known to be unrealistic in many settings, as they depend on using the exact same initialization, which is to be selected randomly, for two different policies. Our results substantially improve upon the existing literature outside the realm of two-point gradient estimates, which either leads to $\widetilde{\mathcal{O}}(1/\varepsilon^2)$ rates or heavily relies on stability assumptions.