 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDNQ: Deep Nash Q-Network for Partially Observable n-Player Games
Jun 04, 2026Many real-world competitive systems require multiple decision-makers to act simultaneously under shared constraints, limited information, and repeated interaction, as in auctions, resource allocation, and security competition. We study multi-turn simultaneous bidding as a controlled testbed for such problems and propose DNQ, a solver-in-the-loop equilibrium supervision framework for training bidding agents. DNQ alternates between trajectory collection, critic-based payoff estimation, equilibrium computation, and policy imitation. At each visited state, a shared critic predicts either pairwise payoff matrices or an exact N-player payoff tensor, an external solver computes equilibrium strategies, and the agents are trained by minimizing the KL divergence between their masked policies and the solver-derived equilibrium targets. We focus on a scalable pairwise formulation that greatly reduces equilibrium-solving cost and training time compared with the exact formulation, while the shared critic amortizes payoff learning across agents and states. Experiments compare the pairwise and exact variants using critic loss, policy entropy, bidding resource usage, and training cost, showing that the pairwise method scales to larger numbers of agents, whereas the exact method becomes computationally impractical as the joint game grows. These results illustrate the trade-off between strategic fidelity and scalability in repeated competitive environments.
Probing Minimalist Phase Structure in LLMs: What Universal Dependencies Cannot Represent
May 26, 2026Structural probes train on Universal Dependencies (UD), which does not encode formal-syntactic abstractions such as phase boundaries or phase-internal cohesion. Whether large language models (LLMs) encode these remains an open question that UD-based probing cannot answer by construction. We evaluate structural probes on wh-movement stimuli where UD distances are invariant across conditions by design -- any non-zero effect therefore reflects structure beyond UD. The three conditions -- bare small clause, infinitival, and finite -- are ordered by the number of Minimalist Program (MP) phase boundaries the wh-element crosses. Across 13 LLMs from four families, we find a phase-count gradient on a cross-clause pair (12/13 models) and a 13/13 sign asymmetry on a within-clause pair whose UD distance is identical across conditions -- the latter specifically predicted by phase-internal cohesion, an MP abstraction invisible to UD by construction. Activation patching confirms the representations are causally active in 12/13 models. These findings suggest that distributional pretraining can induce representations aligned with formal-syntactic abstractions beyond the reach of annotation-based probing; UD-grounded probes provide a lower bound on syntactic encoding, not an upper bound.
RADAR: Relative Angular Divergence Across Representations
May 21, 2026Machine learning methods rely on data. However, gathering suitable data can be challenging due to availability constraints, cost, or the need for domain expertise. Expanding datasets with additional sources is a common response to limited data, yet this practice does not always improve downstream performance and can sometimes lead to a loss of performance, known as negative transfer. We propose RADAR, a simple, geometrically grounded metric for estimating cross-domain transferability in foundation models. RADAR analyzes the layer-wise evolution of representations by measuring angular alignments and relative changes in distance along layer-to-layer displacement trajectories, and by comparing empirical distributions of within-domain and cross-domain dynamics. We hypothesize that domain transferability is related to the divergence between these trajectory distributions. We evaluate the metric across multiple modalities, including cross-lingual sentiment classification with text embedding models and cross-domain image classification with foundation vision models. Across several settings, RADAR provides competitive predictive performance relative to existing transferability metrics on several vision and text benchmarks, with particularly strong results when domain transitions are smooth or cleanly separated. Our ablations further suggest that the effectiveness of transferability estimation depends on the geometry of the model's internal representation space, with different modalities favoring different topological formulations.
Analytica: Soft Propositional Reasoning for Robust and Scalable LLM-Driven Analysis
Apr 24, 2026Large language model (LLM) agents are increasingly tasked with complex real-world analysis (e.g., in financial forecasting, scientific discovery), yet their reasoning suffers from stochastic instability and lacks a verifiable, compositional structure. To address this, we introduce Analytica, a novel agent architecture built on the principle of Soft Propositional Reasoning (SPR). SPR reframes complex analysis as a structured process of estimating the soft truth values of different outcome propositions, allowing us to formally model and minimize the estimation error in terms of its bias and variance. Analytica operationalizes this through a parallel, divide-and-conquer framework that systematically reduces both sources of error. To reduce bias, problems are first decomposed into a tree of subpropositions, and tool-equipped LLM grounder agents are employed, including a novel Jupyter Notebook agent for data-driven analysis, that help to validate and score facts. To reduce variance, Analytica recursively synthesizes these grounded leaves using robust linear models that average out stochastic noise with superior efficiency, scalability, and enable interactive "what-if" scenario analysis. Our theoretical and empirical results on economic, financial, and political forecasting tasks show that Analytica improves 15.84% accuracy on average over diverse base models, achieving 71.06% accuracy with the lowest variance of 6.02% when working with a Deep Research grounder. Our Jupyter Notebook grounder shows strong cost-effectiveness that achieves a close 70.11% accuracy with 90.35% less cost and 52.85% less time. Analytica also exhibits highly noise-resilient and stable performance growth as the analysis depth increases, with a near-linear time complexity, as well as good adaptivity to open-weight LLMs and scientific domains.
FORMULA: FORmation MPC with neUral barrier Learning for safety Assurance
Apr 06, 2026Multi-robot systems (MRS) are essential for large-scale applications such as disaster response, material transport, and warehouse logistics, yet ensuring robust, safety-aware formation control in cluttered and dynamic environments remains a major challenge. Existing model predictive control (MPC) approaches suffer from limitations in scalability and provable safety, while control barrier functions (CBFs), though principled for safety enforcement, are difficult to handcraft for large-scale nonlinear systems. This paper presents FORMULA, a safe distributed, learning-enhanced predictive control framework that integrates MPC with Control Lyapunov Functions (CLFs) for stability and neural network-based CBFs for decentralized safety, eliminating manual safety constraint design. This scheme maintains formation integrity during obstacle avoidance, resolves deadlocks in dense configurations, and reduces online computational load. Simulation results demonstrate that FORMULA enables scalable, safety-aware, formation-preserving navigation for multi-robot teams in complex environments.
Retrieval-Augmented LLMs for Security Incident Analysis
Mar 18, 2026Investigating cybersecurity incidents requires collecting and analyzing evidence from multiple log sources, including intrusion detection alerts, network traffic records, and authentication events. This process is labor-intensive: analysts must sift through large volumes of data to identify relevant indicators and piece together what happened. We present a RAG-based system that performs security incident analysis through targeted query-based filtering and LLM semantic reasoning. The system uses a query library with associated MITRE ATT\&CK techniques to extract indicators from raw logs, then retrieves relevant context to answer forensic questions and reconstruct attack sequences. We evaluate the system with five LLM providers on malware traffic incidents and multi-stage Active Directory attacks. We find that LLM models have different performance and tradeoffs, with Claude Sonnet~4 and DeepSeek~V3 achieving 100\% recall across all four malware scenarios, while DeepSeek costs 15$\times$ less (\$0.008 vs.\ \$0.12 per analysis). Attack step detection on Active Directory scenarios reaches 100\% precision and 82\% recall. Ablation studies confirm that a RAG architecture is essential: LLM baselines without RAG-enhanced context correctly identify victim hosts but miss all attack infrastructure including malicious domains and command-and-control servers. These results demonstrate that combining targeted query-based filtering with RAG-based retrieval enables accurate, cost-effective security analysis within LLM context limits.
ABCD: All Biases Come Disguised
Feb 19, 2026Multiple-choice question (MCQ) benchmarks have been a standard evaluation practice for measuring LLMs' ability to reason and answer knowledge-based questions. Through a synthetic NonsenseQA benchmark, we observe that different LLMs exhibit varying degrees of label-position-few-shot-prompt bias, where the model either uses the answer position, the label in front of the answer, the distributions of correct answers present in the few-shot prompt, or a combination of all to answer each MCQ question. We propose a simple bias-reduced evaluation protocol that replaces the labels of each question with uniform, unordered labels and prompts the LLM to use the whole answer presented. With a simple sentence similarity model, we demonstrate improved robustness and lower standard deviation between different permutations of answers with a minimal drop in LLM's performance, exposing the LLM's capabilities under reduced evaluation artifacts, without any help from the prompt examples or the option labels. Across multiple benchmarks and models, this protocol substantially improves the robustness to answer permutations, reducing mean accuracy variance $3\times$ with only a minimal decrease in the mean model's performance. Through ablation studies on various embedding models and similarity functions, we show that the method is more robust than the standard ones.
Simplify to Amplify: Achieving Information-Theoretic Bounds with Fewer Steps in Spectral Community Detection
Feb 19, 2026We propose a streamlined spectral algorithm for community detection in the two-community stochastic block model (SBM) under constant edge density assumptions. By reducing algorithmic complexity through the elimination of non-essential preprocessing steps, our method directly leverages the spectral properties of the adjacency matrix. We demonstrate that our algorithm exploits specific characteristics of the second eigenvalue to achieve improved error bounds that approach information-theoretic limits, representing a significant improvement over existing methods. Theoretical analysis establishes that our error rates are tighter than previously reported bounds in the literature. Comprehensive experimental validation confirms our theoretical findings and demonstrates the practical effectiveness of the simplified approach. Our results suggest that algorithmic simplification, rather than increasing complexity, can lead to both computational efficiency and enhanced performance in spectral community detection.
PoolFlip: A Multi-Agent Reinforcement Learning Security Environment for Cyber Defense
Aug 27, 2025Cyber defense requires automating defensive decision-making under stealthy, deceptive, and continuously evolving adversarial strategies. The FlipIt game provides a foundational framework for modeling interactions between a defender and an advanced adversary that compromises a system without being immediately detected. In FlipIt, the attacker and defender compete to control a shared resource by performing a Flip action and paying a cost. However, the existing FlipIt frameworks rely on a small number of heuristics or specialized learning techniques, which can lead to brittleness and the inability to adapt to new attacks. To address these limitations, we introduce PoolFlip, a multi-agent gym environment that extends the FlipIt game to allow efficient learning for attackers and defenders. Furthermore, we propose Flip-PSRO, a multi-agent reinforcement learning (MARL) approach that leverages population-based training to train defender agents equipped to generalize against a range of unknown, potentially adaptive opponents. Our empirical results suggest that Flip-PSRO defenders are $2\times$ more effective than baselines to generalize to a heuristic attack not exposed in training. In addition, our newly designed ownership-based utility functions ensure that Flip-PSRO defenders maintain a high level of control while optimizing performance.
MA-RAG: Multi-Agent Retrieval-Augmented Generation via Collaborative Chain-of-Thought Reasoning
May 26, 2025

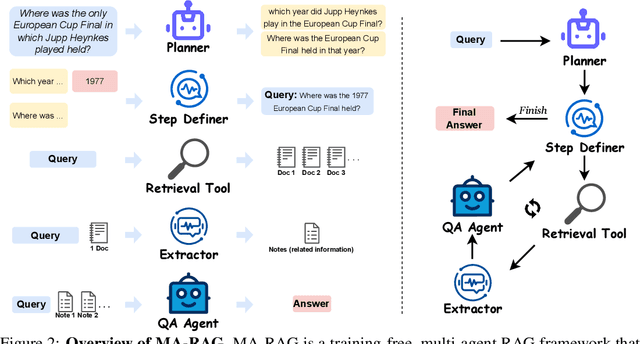

We present MA-RAG, a Multi-Agent framework for Retrieval-Augmented Generation (RAG) that addresses the inherent ambiguities and reasoning challenges in complex information-seeking tasks. Unlike conventional RAG methods that rely on either end-to-end fine-tuning or isolated component enhancements, MA-RAG orchestrates a collaborative set of specialized AI agents: Planner, Step Definer, Extractor, and QA Agents, to tackle each stage of the RAG pipeline with task-aware reasoning. Ambiguities may arise from underspecified queries, sparse or indirect evidence in retrieved documents, or the need to integrate information scattered across multiple sources. MA-RAG mitigates these challenges by decomposing the problem into subtasks, such as query disambiguation, evidence extraction, and answer synthesis, and dispatching them to dedicated agents equipped with chain-of-thought prompting. These agents communicate intermediate reasoning and progressively refine the retrieval and synthesis process. Our design allows fine-grained control over information flow without any model fine-tuning. Crucially, agents are invoked on demand, enabling a dynamic and efficient workflow that avoids unnecessary computation. This modular and reasoning-driven architecture enables MA-RAG to deliver robust, interpretable results. Experiments on multi-hop and ambiguous QA benchmarks demonstrate that MA-RAG outperforms state-of-the-art training-free baselines and rivals fine-tuned systems, validating the effectiveness of collaborative agent-based reasoning in RAG.