 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZipNN: Lossless Compression for AI Models
Nov 07, 2024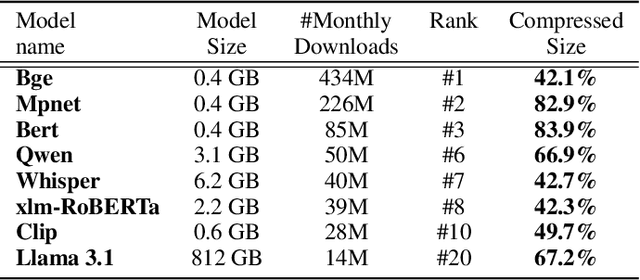
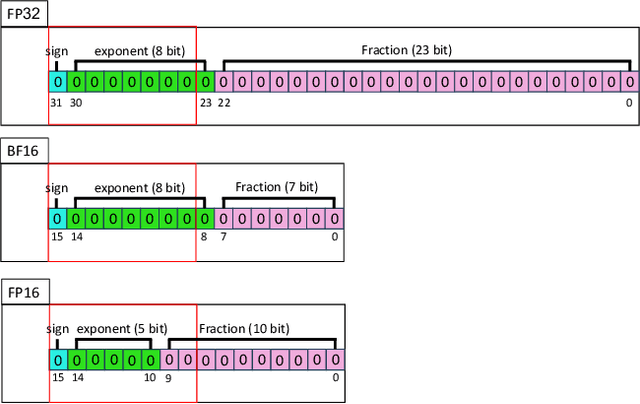
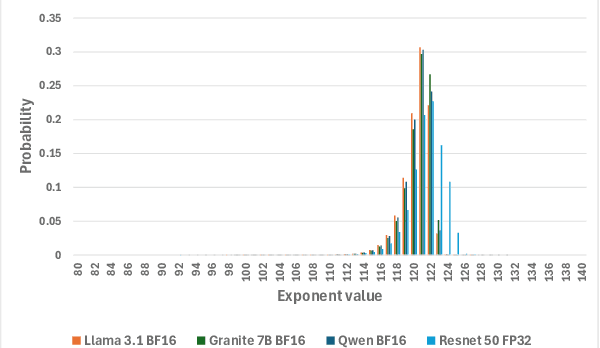
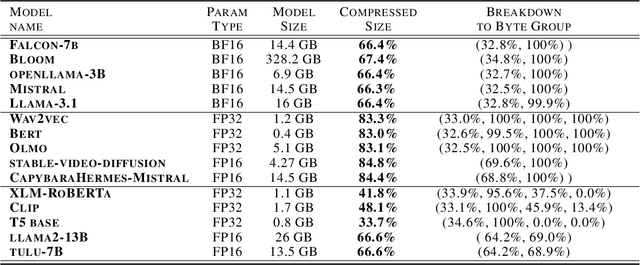
With the growth of model sizes and the scale of their deployment, their sheer size burdens the infrastructure requiring more network and more storage to accommodate these. While there is a vast model compression literature deleting parts of the model weights for faster inference, we investigate a more traditional type of compression - one that represents the model in a compact form and is coupled with a decompression algorithm that returns it to its original form and size - namely lossless compression. We present ZipNN a lossless compression tailored to neural networks. Somewhat surprisingly, we show that specific lossless compression can gain significant network and storage reduction on popular models, often saving 33% and at times reducing over 50% of the model size. We investigate the source of model compressibility and introduce specialized compression variants tailored for models that further increase the effectiveness of compression. On popular models (e.g. Llama 3) ZipNN shows space savings that are over 17% better than vanilla compression while also improving compression and decompression speeds by 62%. We estimate that these methods could save over an ExaByte per month of network traffic downloaded from a large model hub like Hugging Face.