 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZipNN: Lossless Compression for AI Models
Nov 07, 2024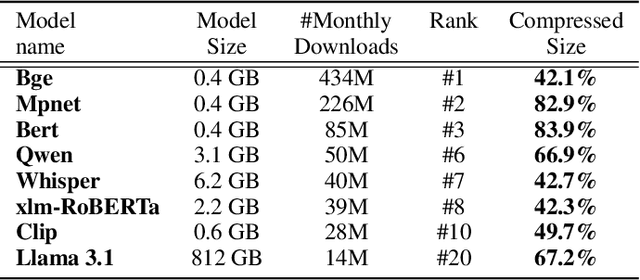
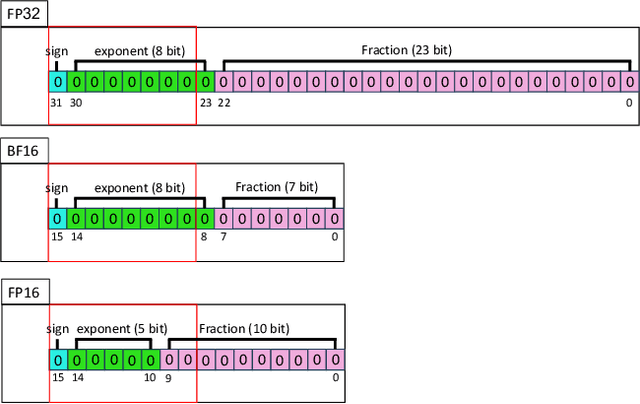
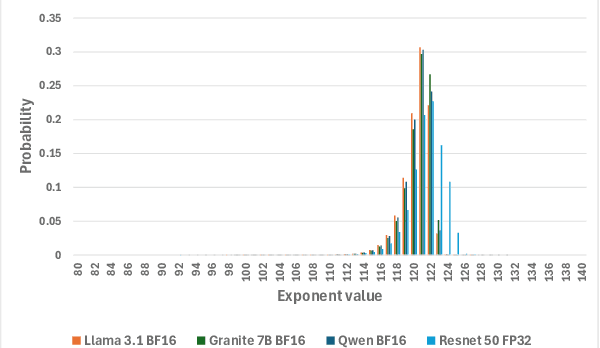
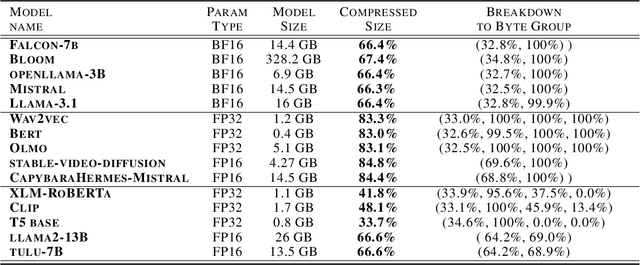
With the growth of model sizes and the scale of their deployment, their sheer size burdens the infrastructure requiring more network and more storage to accommodate these. While there is a vast model compression literature deleting parts of the model weights for faster inference, we investigate a more traditional type of compression - one that represents the model in a compact form and is coupled with a decompression algorithm that returns it to its original form and size - namely lossless compression. We present ZipNN a lossless compression tailored to neural networks. Somewhat surprisingly, we show that specific lossless compression can gain significant network and storage reduction on popular models, often saving 33% and at times reducing over 50% of the model size. We investigate the source of model compressibility and introduce specialized compression variants tailored for models that further increase the effectiveness of compression. On popular models (e.g. Llama 3) ZipNN shows space savings that are over 17% better than vanilla compression while also improving compression and decompression speeds by 62%. We estimate that these methods could save over an ExaByte per month of network traffic downloaded from a large model hub like Hugging Face.
The infrastructure powering IBM's Gen AI model development
Jul 07, 2024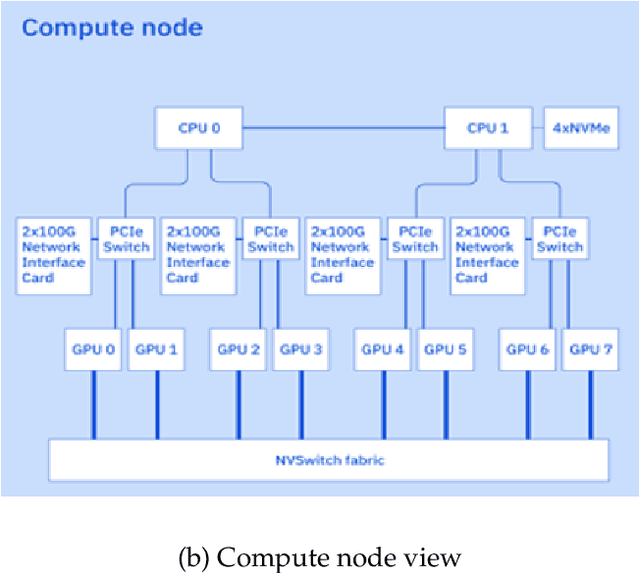
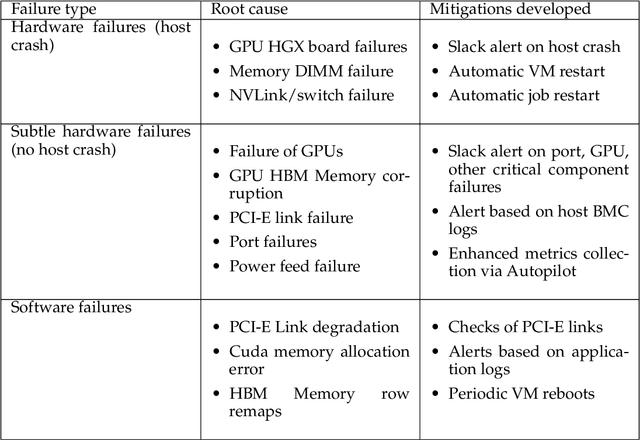
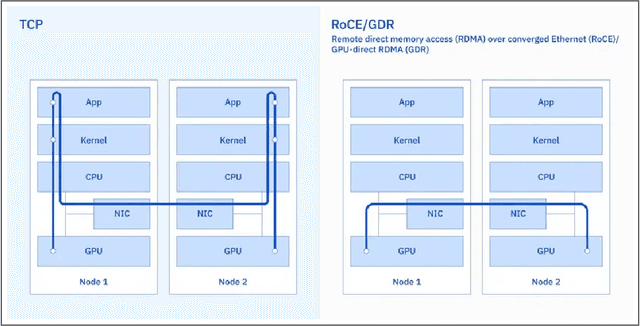
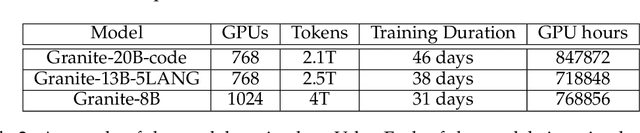
AI Infrastructure plays a key role in the speed and cost-competitiveness of developing and deploying advanced AI models. The current demand for powerful AI infrastructure for model training is driven by the emergence of generative AI and foundational models, where on occasion thousands of GPUs must cooperate on a single training job for the model to be trained in a reasonable time. Delivering efficient and high-performing AI training requires an end-to-end solution that combines hardware, software and holistic telemetry to cater for multiple types of AI workloads. In this report, we describe IBM's hybrid cloud infrastructure that powers our generative AI model development. This infrastructure includes (1) Vela: an AI-optimized supercomputing capability directly integrated into the IBM Cloud, delivering scalable, dynamic, multi-tenant and geographically distributed infrastructure for large-scale model training and other AI workflow steps and (2) Blue Vela: a large-scale, purpose-built, on-premises hosting environment that is optimized to support our largest and most ambitious AI model training tasks. Vela provides IBM with the dual benefit of high performance for internal use along with the flexibility to adapt to an evolving commercial landscape. Blue Vela provides us with the benefits of rapid development of our largest and most ambitious models, as well as future-proofing against the evolving model landscape in the industry. Taken together, they provide IBM with the ability to rapidly innovate in the development of both AI models and commercial offerings.
MPP: Model Performance Predictor
Feb 22, 2019

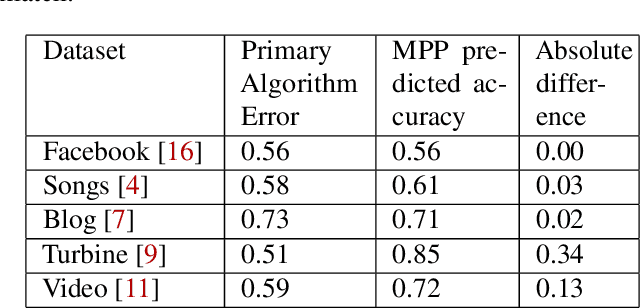
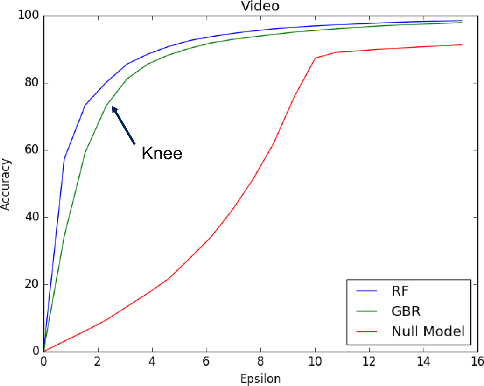
Operations is a key challenge in the domain of machine learning pipeline deployments involving monitoring and management of real-time prediction quality. Typically, metrics like accuracy, RMSE etc., are used to track the performance of models in deployment. However, these metrics cannot be calculated in production due to the absence of labels. We propose using an ML algorithm, Model Performance Predictor (MPP), to track the performance of the models in deployment. We argue that an ensemble of such metrics can be used to create a score representing the prediction quality in production. This in turn facilitates formulation and customization of ML alerts, that can be escalated by an operations team to the data science team. Such a score automates monitoring and enables ML deployments at scale.
ML Health: Fitness Tracking for Production Models
Feb 07, 2019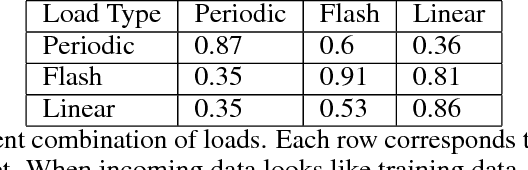
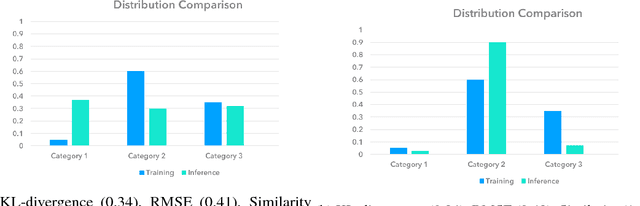

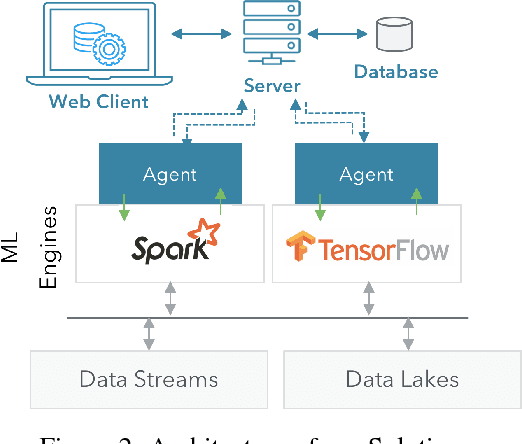
Deployment of machine learning (ML) algorithms in production for extended periods of time has uncovered new challenges such as monitoring and management of real-time prediction quality of a model in the absence of labels. However, such tracking is imperative to prevent catastrophic business outcomes resulting from incorrect predictions. The scale of these deployments makes manual monitoring prohibitive, making automated techniques to track and raise alerts imperative. We present a framework, ML Health, for tracking potential drops in the predictive performance of ML models in the absence of labels. The framework employs diagnostic methods to generate alerts for further investigation. We develop one such method to monitor potential problems when production data patterns do not match training data distributions. We demonstrate that our method performs better than standard "distance metrics", such as RMSE, KL-Divergence, and Wasserstein at detecting issues with mismatched data sets. Finally, we present a working system that incorporates the ML Health approach to monitor and manage ML deployments within a realistic full production ML lifecycle.