 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoxtral TTS
Mar 26, 2026We introduce Voxtral TTS, an expressive multilingual text-to-speech model that generates natural speech from as little as 3 seconds of reference audio. Voxtral TTS adopts a hybrid architecture that combines auto-regressive generation of semantic speech tokens with flow-matching for acoustic tokens. These tokens are encoded and decoded with Voxtral Codec, a speech tokenizer trained from scratch with a hybrid VQ-FSQ quantization scheme. In human evaluations conducted by native speakers, Voxtral TTS is preferred for multilingual voice cloning due to its naturalness and expressivity, achieving a 68.4\% win rate over ElevenLabs Flash v2.5. We release the model weights under a CC BY-NC license.
Generalized Multiple Intent Conditioned Slot Filling
May 18, 2023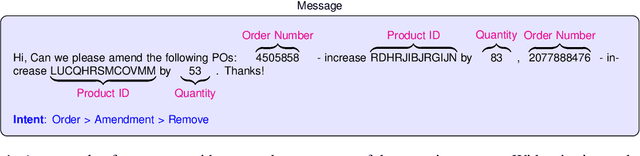
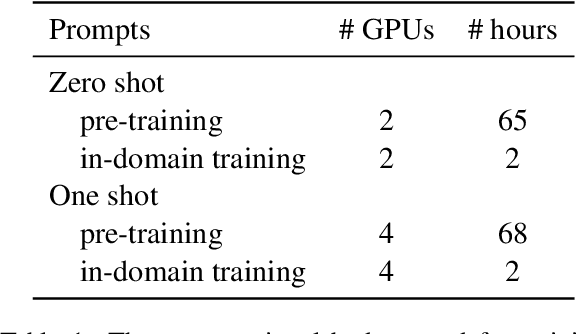
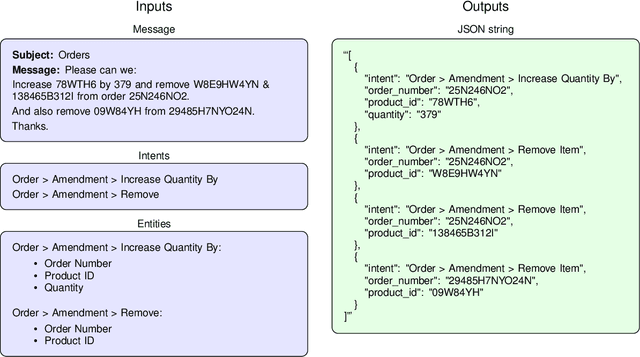
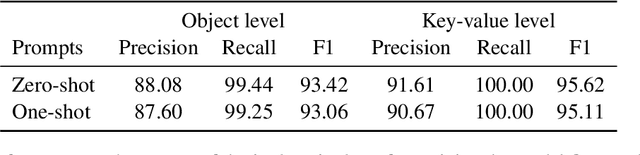
Natural language understanding includes the tasks of intent detection (identifying a user's objectives) and slot filling (extracting the entities relevant to those objectives). Prior slot filling methods assume that each intent type cannot occur more than once within a message, however this is often not a valid assumption for real-world settings. In this work, we generalize slot filling by removing the constraint of unique intents in a message. We cast this as a JSON generation task and approach it using a language model. We create a pre-training dataset by combining DBpedia and existing slot filling datasets that we convert for JSON generation. We also generate an in-domain dataset using GPT-3. We train T5 models for this task (with and without exemplars in the prompt) and find that both training datasets improve performance, and that the model is able to generalize to intent types not seen during training.
NURBS-Diff: A Differentiable NURBS Layer for Machine Learning CAD Applications
Apr 29, 2021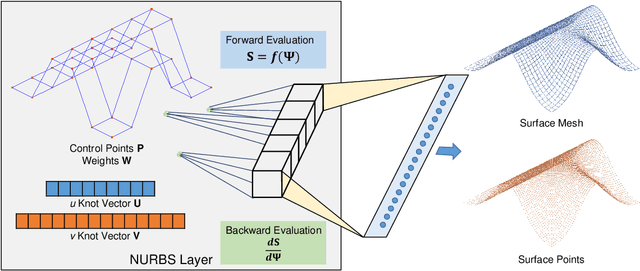
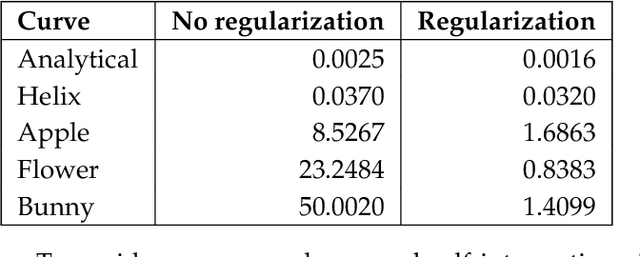
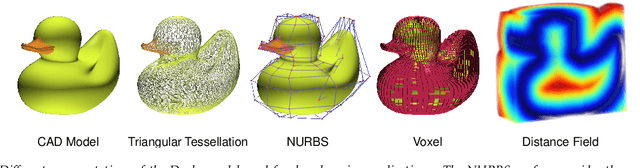
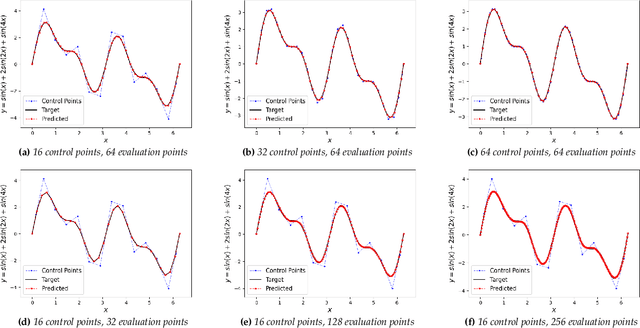
Recent deep-learning-based techniques for the reconstruction of geometries from different input representations such as images and point clouds have been instrumental in advancing research in geometric machine learning. Most of these techniques rely on a triangular mesh representation for representing the geometry, with very recent attempts in using B-splines. While Non-Uniform Rational B-splines (NURBS) are the de facto standard in the CAD industry, minimal efforts have been made to bridge the gap between deep-learning frameworks and the NURBS representation for geometry. The backbone of modern deep learning techniques is the use of a fully automatic differentiable definition for each mathematical operation to enable backpropagation of losses while training. In order to integrate the NURBS representation of CAD models with deep learning methods, we propose a differentiable NURBS layer for evaluating the curve or surface given a set of NURBS parameters. We have developed a NURBS layer defining the forward and backward pass required for automatic differentiation. Our implementation is GPU accelerated and is directly integrated with PyTorch, a popular deep learning framework. We demonstrate the efficacy of our NURBS layer by automatically incorporating it with the stochastic gradient descent algorithm and performing CAD operations such as curve or surface fitting and surface offsetting. Further, we show its utility in deep learning applications such as point cloud reconstruction and structural modeling and analysis of shell structures such as heart valves. These examples show that our layer has better performance for certain deep learning frameworks and can be directly integrated with any CAD deep-learning framework that require the use of NURBS.
Locally-Contextual Nonlinear CRFs for Sequence Labeling
Mar 30, 2021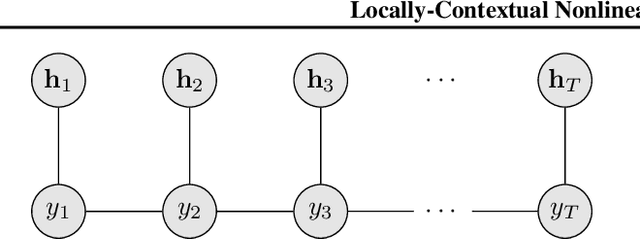
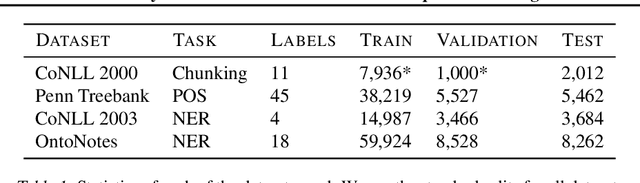
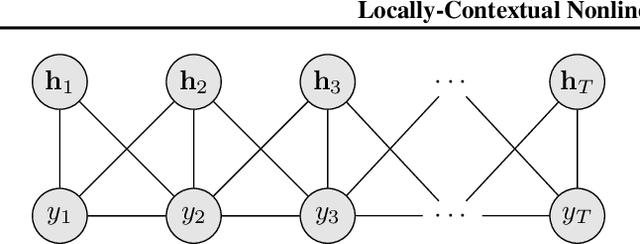
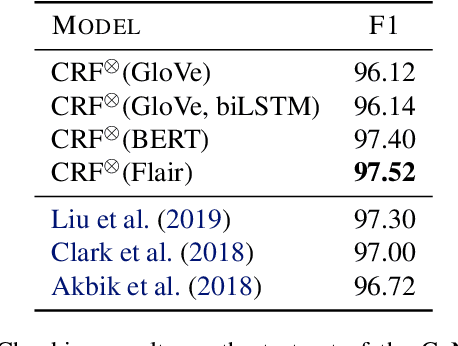
Linear chain conditional random fields (CRFs) combined with contextual word embeddings have achieved state of the art performance on sequence labeling tasks. In many of these tasks, the identity of the neighboring words is often the most useful contextual information when predicting the label of a given word. However, contextual embeddings are usually trained in a task-agnostic manner. This means that although they may encode information about the neighboring words, it is not guaranteed. It can therefore be beneficial to design the sequence labeling architecture to directly extract this information from the embeddings. We propose locally-contextual nonlinear CRFs for sequence labeling. Our approach directly incorporates information from the neighboring embeddings when predicting the label for a given word, and parametrizes the potential functions using deep neural networks. Our model serves as a drop-in replacement for the linear chain CRF, consistently outperforming it in our ablation study. On a variety of tasks, our results are competitive with those of the best published methods. In particular, we outperform the previous state of the art on chunking on CoNLL 2000 and named entity recognition on OntoNotes 5.0 English.
Learning Informative Representations of Biomedical Relations with Latent Variable Models
Nov 20, 2020

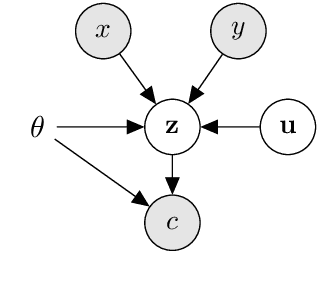

Extracting biomedical relations from large corpora of scientific documents is a challenging natural language processing task. Existing approaches usually focus on identifying a relation either in a single sentence (mention-level) or across an entire corpus (pair-level). In both cases, recent methods have achieved strong results by learning a point estimate to represent the relation; this is then used as the input to a relation classifier. However, the relation expressed in text between a pair of biomedical entities is often more complex than can be captured by a point estimate. To address this issue, we propose a latent variable model with an arbitrarily flexible distribution to represent the relation between an entity pair. Additionally, our model provides a unified architecture for both mention-level and pair-level relation extraction. We demonstrate that our model achieves results competitive with strong baselines for both tasks while having fewer parameters and being significantly faster to train. We make our code publicly available.
MPP: Model Performance Predictor
Feb 22, 2019

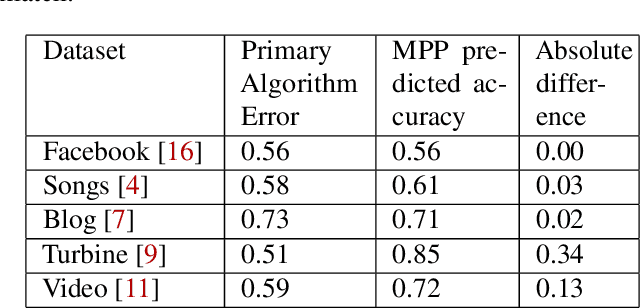
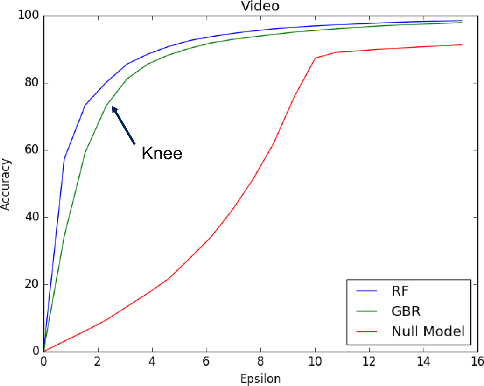
Operations is a key challenge in the domain of machine learning pipeline deployments involving monitoring and management of real-time prediction quality. Typically, metrics like accuracy, RMSE etc., are used to track the performance of models in deployment. However, these metrics cannot be calculated in production due to the absence of labels. We propose using an ML algorithm, Model Performance Predictor (MPP), to track the performance of the models in deployment. We argue that an ensemble of such metrics can be used to create a score representing the prediction quality in production. This in turn facilitates formulation and customization of ML alerts, that can be escalated by an operations team to the data science team. Such a score automates monitoring and enables ML deployments at scale.
ML Health: Fitness Tracking for Production Models
Feb 07, 2019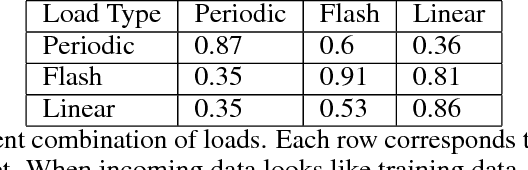
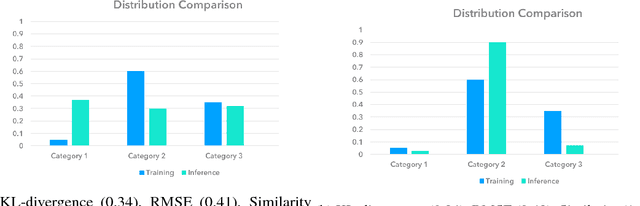

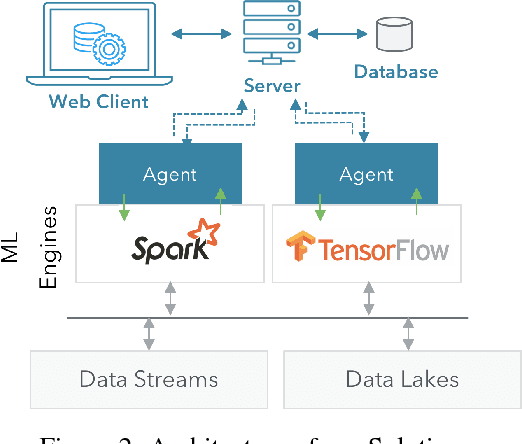
Deployment of machine learning (ML) algorithms in production for extended periods of time has uncovered new challenges such as monitoring and management of real-time prediction quality of a model in the absence of labels. However, such tracking is imperative to prevent catastrophic business outcomes resulting from incorrect predictions. The scale of these deployments makes manual monitoring prohibitive, making automated techniques to track and raise alerts imperative. We present a framework, ML Health, for tracking potential drops in the predictive performance of ML models in the absence of labels. The framework employs diagnostic methods to generate alerts for further investigation. We develop one such method to monitor potential problems when production data patterns do not match training data distributions. We demonstrate that our method performs better than standard "distance metrics", such as RMSE, KL-Divergence, and Wasserstein at detecting issues with mismatched data sets. Finally, we present a working system that incorporates the ML Health approach to monitor and manage ML deployments within a realistic full production ML lifecycle.
Generative Neural Machine Translation
Jun 13, 2018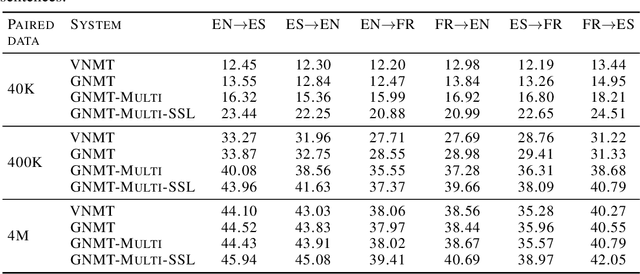



We introduce Generative Neural Machine Translation (GNMT), a latent variable architecture which is designed to model the semantics of the source and target sentences. We modify an encoder-decoder translation model by adding a latent variable as a language agnostic representation which is encouraged to learn the meaning of the sentence. GNMT achieves competitive BLEU scores on pure translation tasks, and is superior when there are missing words in the source sentence. We augment the model to facilitate multilingual translation and semi-supervised learning without adding parameters. This framework significantly reduces overfitting when there is limited paired data available, and is effective for translating between pairs of languages not seen during training.
Generating Sentences Using a Dynamic Canvas
Jun 13, 2018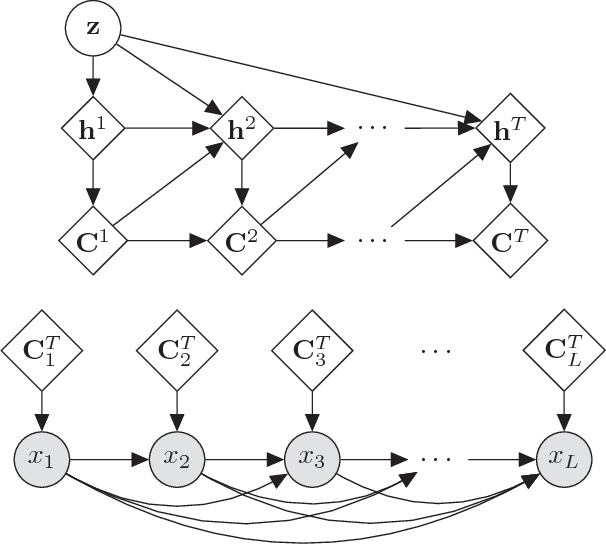
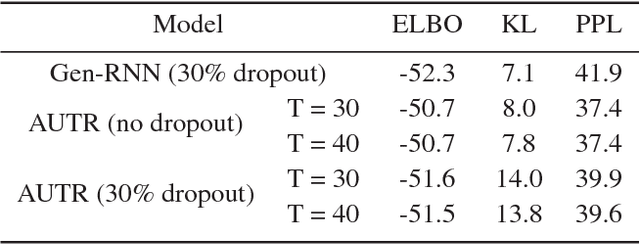


We introduce the Attentive Unsupervised Text (W)riter (AUTR), which is a word level generative model for natural language. It uses a recurrent neural network with a dynamic attention and canvas memory mechanism to iteratively construct sentences. By viewing the state of the memory at intermediate stages and where the model is placing its attention, we gain insight into how it constructs sentences. We demonstrate that AUTR learns a meaningful latent representation for each sentence, and achieves competitive log-likelihood lower bounds whilst being computationally efficient. It is effective at generating and reconstructing sentences, as well as imputing missing words.