 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Attention for Linear Time Transformers
Mar 04, 2024The time complexity of the standard attention mechanism in a transformer scales quadratically with the length of the sequence. We introduce a method to reduce this to linear scaling with time, based on defining attention via latent vectors. The method is readily usable as a drop-in replacement for the standard attention mechanism. Our "Latte Transformer" model can be implemented for both bidirectional and unidirectional tasks, with the causal version allowing a recurrent implementation which is memory and time-efficient during inference of language generation tasks. Whilst next token prediction scales linearly with the sequence length for a standard transformer, a Latte Transformer requires constant time to compute the next token. The empirical performance of our method is comparable to standard attention, yet allows scaling to context windows much larger than practical in standard attention.
Generalized Multiple Intent Conditioned Slot Filling
May 18, 2023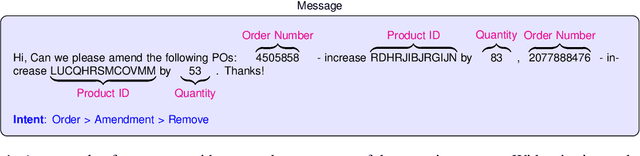
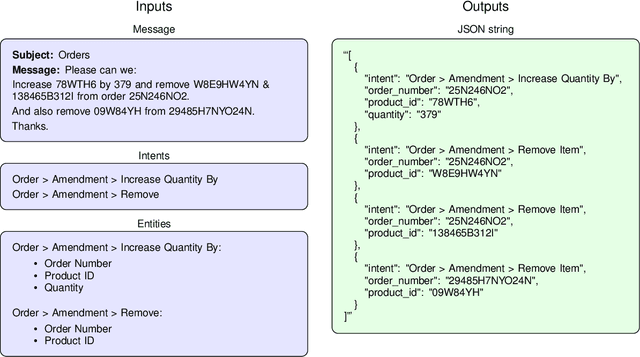
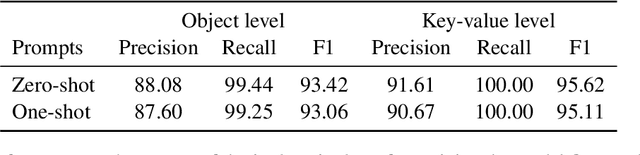
Natural language understanding includes the tasks of intent detection (identifying a user's objectives) and slot filling (extracting the entities relevant to those objectives). Prior slot filling methods assume that each intent type cannot occur more than once within a message, however this is often not a valid assumption for real-world settings. In this work, we generalize slot filling by removing the constraint of unique intents in a message. We cast this as a JSON generation task and approach it using a language model. We create a pre-training dataset by combining DBpedia and existing slot filling datasets that we convert for JSON generation. We also generate an in-domain dataset using GPT-3. We train T5 models for this task (with and without exemplars in the prompt) and find that both training datasets improve performance, and that the model is able to generalize to intent types not seen during training.