 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncremental Sequence Classification with Temporal Consistency
May 22, 2025We address the problem of incremental sequence classification, where predictions are updated as new elements in the sequence are revealed. Drawing on temporal-difference learning from reinforcement learning, we identify a temporal-consistency condition that successive predictions should satisfy. We leverage this condition to develop a novel loss function for training incremental sequence classifiers. Through a concrete example, we demonstrate that optimizing this loss can offer substantial gains in data efficiency. We apply our method to text classification tasks and show that it improves predictive accuracy over competing approaches on several benchmark datasets. We further evaluate our approach on the task of verifying large language model generations for correctness in grade-school math problems. Our results show that models trained with our method are better able to distinguish promising generations from unpromising ones after observing only a few tokens.
RotRNN: Modelling Long Sequences with Rotations
Jul 09, 2024Linear recurrent models, such as State Space Models (SSMs) and Linear Recurrent Units (LRUs), have recently shown state-of-the-art performance on long sequence modelling benchmarks. Despite their success, they come with a number of drawbacks, most notably their complex initialisation and normalisation schemes. In this work, we address some of these issues by proposing RotRNN -- a linear recurrent model which utilises the convenient properties of rotation matrices. We show that RotRNN provides a simple model with fewer theoretical assumptions than prior works, with a practical implementation that remains faithful to its theoretical derivation, achieving comparable scores to the LRU and SSMs on several long sequence modelling datasets.
Log Summarisation for Defect Evolution Analysis
Mar 13, 2024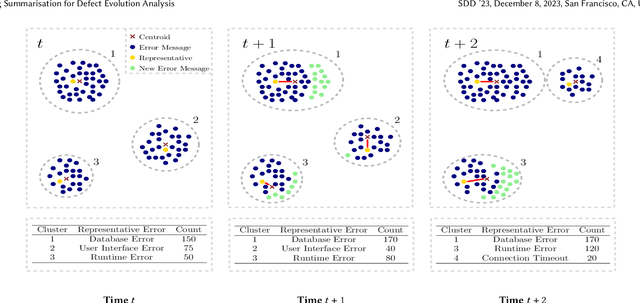
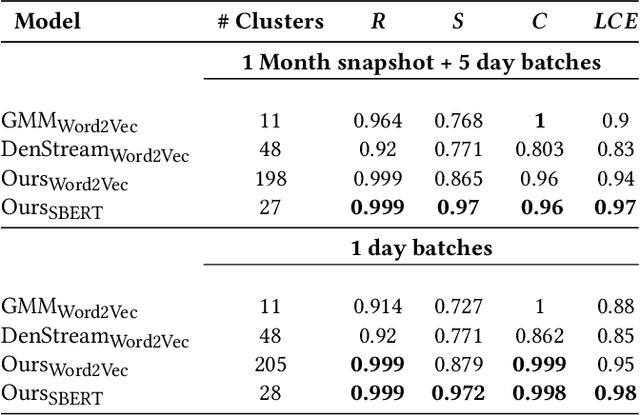
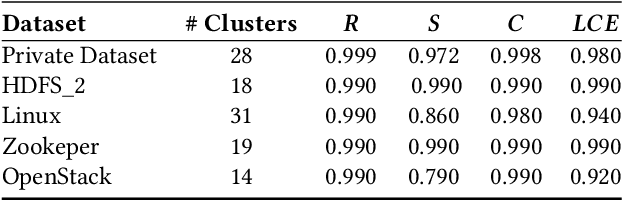
Log analysis and monitoring are essential aspects in software maintenance and identifying defects. In particular, the temporal nature and vast size of log data leads to an interesting and important research question: How can logs be summarised and monitored over time? While this has been a fundamental topic of research in the software engineering community, work has typically focused on heuristic-, syntax-, or static-based methods. In this work, we suggest an online semantic-based clustering approach to error logs that dynamically updates the log clusters to enable monitoring code error life-cycles. We also introduce a novel metric to evaluate the performance of temporal log clusters. We test our system and evaluation metric with an industrial dataset and find that our solution outperforms similar systems. We hope that our work encourages further temporal exploration in defect datasets.
Latent Attention for Linear Time Transformers
Mar 04, 2024The time complexity of the standard attention mechanism in a transformer scales quadratically with the length of the sequence. We introduce a method to reduce this to linear scaling with time, based on defining attention via latent vectors. The method is readily usable as a drop-in replacement for the standard attention mechanism. Our "Latte Transformer" model can be implemented for both bidirectional and unidirectional tasks, with the causal version allowing a recurrent implementation which is memory and time-efficient during inference of language generation tasks. Whilst next token prediction scales linearly with the sequence length for a standard transformer, a Latte Transformer requires constant time to compute the next token. The empirical performance of our method is comparable to standard attention, yet allows scaling to context windows much larger than practical in standard attention.