 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCodeMirage: Hallucinations in Code Generated by Large Language Models
Aug 14, 2024



Large Language Models (LLMs) have shown promising potentials in program generation and no-code automation. However, LLMs are prone to generate hallucinations, i.e., they generate text which sounds plausible but is incorrect. Although there has been a recent surge in research on LLM hallucinations for text generation, similar hallucination phenomenon can happen in code generation. Sometimes the generated code can have syntactical or logical errors as well as more advanced issues like security vulnerabilities, memory leaks, etc. Given the wide adaptation of LLMs to enhance efficiency in code generation and development in general, it becomes imperative to investigate hallucinations in code generation. To the best of our knowledge, this is the first attempt at studying hallucinations in the code generated by LLMs. We start by introducing the code hallucination definition and a comprehensive taxonomy of code hallucination types. We propose the first benchmark CodeMirage dataset for code hallucinations. The benchmark contains 1,137 GPT-3.5 generated hallucinated code snippets for Python programming problems from two base datasets - HumanEval and MBPP. We then propose the methodology for code hallucination detection and experiment with open source LLMs such as CodeLLaMA as well as OpenAI's GPT-3.5 and GPT-4 models using one-shot prompt. We find that GPT-4 performs the best on HumanEval dataset and gives comparable results to the fine-tuned CodeBERT baseline on MBPP dataset. Towards the end, we discuss various mitigation strategies for code hallucinations and conclude our work.
Translating between SQL Dialects for Cloud Migration
Mar 13, 2024
Migrations of systems from on-site premises to the cloud has been a fundamental endeavor by many industrial institutions. A crucial component of such cloud migrations is the transition of databases to be hosted online. In this work, we consider the difficulties of this migration for SQL databases. While SQL is one of the prominent methods for storing database procedures, there are a plethora of different SQL dialects (e.g., MySQL, Postgres, etc.) which can complicate migrations when the on-premise SQL dialect differs to the dialect hosted on the cloud. Tools exist by common cloud provides such as AWS and Azure to aid in translating between dialects in order to mitigate the majority of the difficulties. However, these tools do not successfully translate $100\%$ of the code. Consequently, software engineers must manually convert the remainder of the untranslated database. For large organizations, this task quickly becomes intractable and so more innovative solutions are required. We consider this challenge a novel yet vital industrial research problem for any large corporation that is considering cloud migrations. Furthermore, we introduce potential avenues of research to tackle this challenge that have yielded promising preliminary results.
Search-based Optimisation of LLM Learning Shots for Story Point Estimation
Mar 13, 2024One of the ways Large Language Models (LLMs) are used to perform machine learning tasks is to provide them with a few examples before asking them to produce a prediction. This is a meta-learning process known as few-shot learning. In this paper, we use available Search-Based methods to optimise the number and combination of examples that can improve an LLM's estimation performance, when it is used to estimate story points for new agile tasks. Our preliminary results show that our SBSE technique improves the estimation performance of the LLM by 59.34% on average (in terms of mean absolute error of the estimation) over three datasets against a zero-shot setting.
* 6 pages, Accepted at SSBSE'23 NIER Track
Software Vulnerability and Functionality Assessment using LLMs
Mar 13, 2024
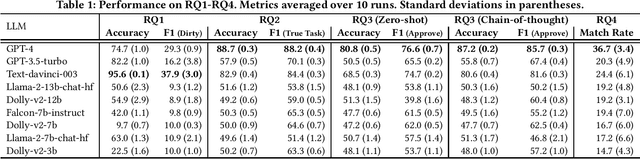


While code review is central to the software development process, it can be tedious and expensive to carry out. In this paper, we investigate whether and how Large Language Models (LLMs) can aid with code reviews. Our investigation focuses on two tasks that we argue are fundamental to good reviews: (i) flagging code with security vulnerabilities and (ii) performing software functionality validation, i.e., ensuring that code meets its intended functionality. To test performance on both tasks, we use zero-shot and chain-of-thought prompting to obtain final ``approve or reject'' recommendations. As data, we employ seminal code generation datasets (HumanEval and MBPP) along with expert-written code snippets with security vulnerabilities from the Common Weakness Enumeration (CWE). Our experiments consider a mixture of three proprietary models from OpenAI and smaller open-source LLMs. We find that the former outperforms the latter by a large margin. Motivated by promising results, we finally ask our models to provide detailed descriptions of security vulnerabilities. Results show that 36.7% of LLM-generated descriptions can be associated with true CWE vulnerabilities.
Log Summarisation for Defect Evolution Analysis
Mar 13, 2024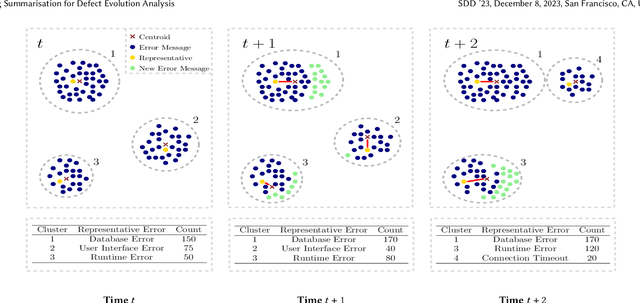
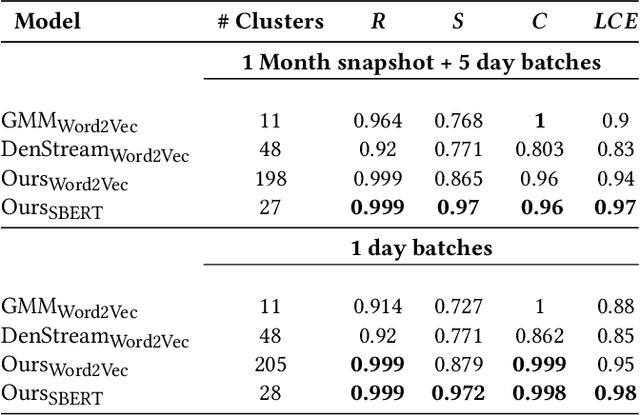
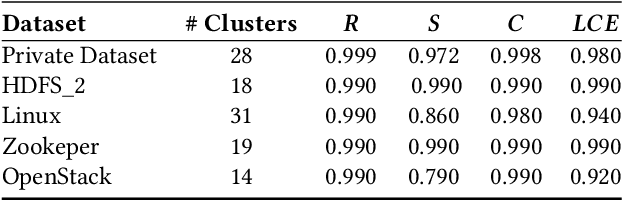
Log analysis and monitoring are essential aspects in software maintenance and identifying defects. In particular, the temporal nature and vast size of log data leads to an interesting and important research question: How can logs be summarised and monitored over time? While this has been a fundamental topic of research in the software engineering community, work has typically focused on heuristic-, syntax-, or static-based methods. In this work, we suggest an online semantic-based clustering approach to error logs that dynamically updates the log clusters to enable monitoring code error life-cycles. We also introduce a novel metric to evaluate the performance of temporal log clusters. We test our system and evaluation metric with an industrial dataset and find that our solution outperforms similar systems. We hope that our work encourages further temporal exploration in defect datasets.
Neural Transition-based Parsing of Library Deprecations
Dec 23, 2022
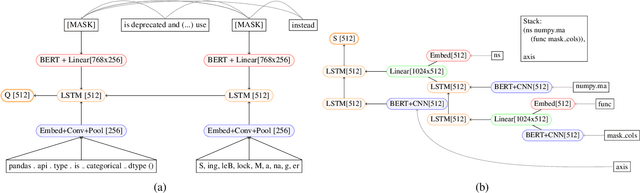


This paper tackles the challenging problem of automating code updates to fix deprecated API usages of open source libraries by analyzing their release notes. Our system employs a three-tier architecture: first, a web crawler service retrieves deprecation documentation from the web; then a specially built parser processes those text documents into tree-structured representations; finally, a client IDE plugin locates and fixes identified deprecated usages of libraries in a given codebase. The focus of this paper in particular is the parsing component. We introduce a novel transition-based parser in two variants: based on a classical feature engineered classifier and a neural tree encoder. To confirm the effectiveness of our method, we gathered and labeled a set of 426 API deprecations from 7 well-known Python data science libraries, and demonstrated our approach decisively outperforms a non-trivial neural machine translation baseline.