 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Active Learning (RoAL): Countering Dynamic Adversaries in Active Learning with Elastic Weight Consolidation
Aug 15, 2024

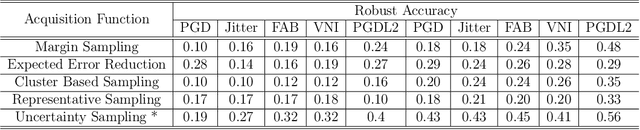
Despite significant advancements in active learning and adversarial attacks, the intersection of these two fields remains underexplored, particularly in developing robust active learning frameworks against dynamic adversarial threats. The challenge of developing robust active learning frameworks under dynamic adversarial attacks is critical, as these attacks can lead to catastrophic forgetting within the active learning cycle. This paper introduces Robust Active Learning (RoAL), a novel approach designed to address this issue by integrating Elastic Weight Consolidation (EWC) into the active learning process. Our contributions are threefold: First, we propose a new dynamic adversarial attack that poses significant threats to active learning frameworks. Second, we introduce a novel method that combines EWC with active learning to mitigate catastrophic forgetting caused by dynamic adversarial attacks. Finally, we conduct extensive experimental evaluations to demonstrate the efficacy of our approach. The results show that RoAL not only effectively counters dynamic adversarial threats but also significantly reduces the impact of catastrophic forgetting, thereby enhancing the robustness and performance of active learning systems in adversarial environments.
CodeMirage: Hallucinations in Code Generated by Large Language Models
Aug 14, 2024



Large Language Models (LLMs) have shown promising potentials in program generation and no-code automation. However, LLMs are prone to generate hallucinations, i.e., they generate text which sounds plausible but is incorrect. Although there has been a recent surge in research on LLM hallucinations for text generation, similar hallucination phenomenon can happen in code generation. Sometimes the generated code can have syntactical or logical errors as well as more advanced issues like security vulnerabilities, memory leaks, etc. Given the wide adaptation of LLMs to enhance efficiency in code generation and development in general, it becomes imperative to investigate hallucinations in code generation. To the best of our knowledge, this is the first attempt at studying hallucinations in the code generated by LLMs. We start by introducing the code hallucination definition and a comprehensive taxonomy of code hallucination types. We propose the first benchmark CodeMirage dataset for code hallucinations. The benchmark contains 1,137 GPT-3.5 generated hallucinated code snippets for Python programming problems from two base datasets - HumanEval and MBPP. We then propose the methodology for code hallucination detection and experiment with open source LLMs such as CodeLLaMA as well as OpenAI's GPT-3.5 and GPT-4 models using one-shot prompt. We find that GPT-4 performs the best on HumanEval dataset and gives comparable results to the fine-tuned CodeBERT baseline on MBPP dataset. Towards the end, we discuss various mitigation strategies for code hallucinations and conclude our work.
(PASS) Visual Prompt Locates Good Structure Sparsity through a Recurrent HyperNetwork
Jul 24, 2024


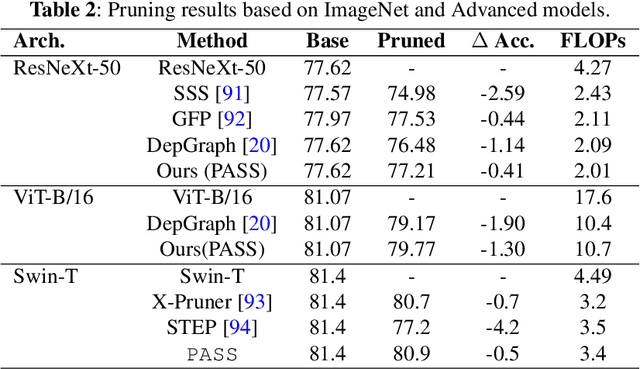
Large-scale neural networks have demonstrated remarkable performance in different domains like vision and language processing, although at the cost of massive computation resources. As illustrated by compression literature, structural model pruning is a prominent algorithm to encourage model efficiency, thanks to its acceleration-friendly sparsity patterns. One of the key questions of structural pruning is how to estimate the channel significance. In parallel, work on data-centric AI has shown that prompting-based techniques enable impressive generalization of large language models across diverse downstream tasks. In this paper, we investigate a charming possibility - \textit{leveraging visual prompts to capture the channel importance and derive high-quality structural sparsity}. To this end, we propose a novel algorithmic framework, namely \texttt{PASS}. It is a tailored hyper-network to take both visual prompts and network weight statistics as input, and output layer-wise channel sparsity in a recurrent manner. Such designs consider the intrinsic channel dependency between layers. Comprehensive experiments across multiple network architectures and six datasets demonstrate the superiority of \texttt{PASS} in locating good structural sparsity. For example, at the same FLOPs level, \texttt{PASS} subnetworks achieve $1\%\sim 3\%$ better accuracy on Food101 dataset; or with a similar performance of $80\%$ accuracy, \texttt{PASS} subnetworks obtain $0.35\times$ more speedup than the baselines.
BuDDIE: A Business Document Dataset for Multi-task Information Extraction
Apr 05, 2024The field of visually rich document understanding (VRDU) aims to solve a multitude of well-researched NLP tasks in a multi-modal domain. Several datasets exist for research on specific tasks of VRDU such as document classification (DC), key entity extraction (KEE), entity linking, visual question answering (VQA), inter alia. These datasets cover documents like invoices and receipts with sparse annotations such that they support one or two co-related tasks (e.g., entity extraction and entity linking). Unfortunately, only focusing on a single specific of documents or task is not representative of how documents often need to be processed in the wild - where variety in style and requirements is expected. In this paper, we introduce BuDDIE (Business Document Dataset for Information Extraction), the first multi-task dataset of 1,665 real-world business documents that contains rich and dense annotations for DC, KEE, and VQA. Our dataset consists of publicly available business entity documents from US state government websites. The documents are structured and vary in their style and layout across states and types (e.g., forms, certificates, reports, etc.). We provide data variety and quality metrics for BuDDIE as well as a series of baselines for each task. Our baselines cover traditional textual, multi-modal, and large language model approaches to VRDU.
DocLLM: A layout-aware generative language model for multimodal document understanding
Dec 31, 2023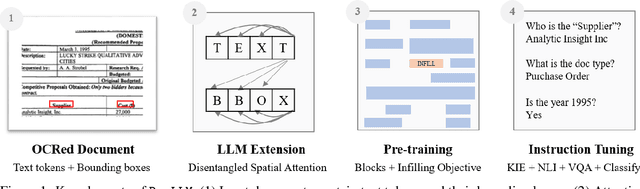

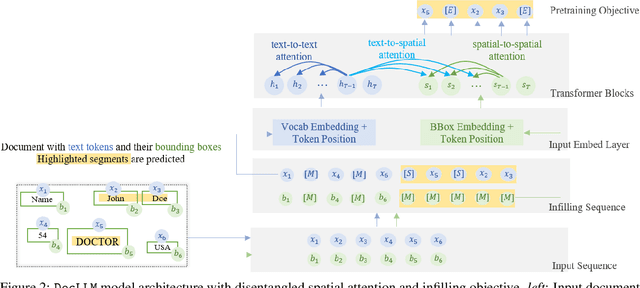
Enterprise documents such as forms, invoices, receipts, reports, contracts, and other similar records, often carry rich semantics at the intersection of textual and spatial modalities. The visual cues offered by their complex layouts play a crucial role in comprehending these documents effectively. In this paper, we present DocLLM, a lightweight extension to traditional large language models (LLMs) for reasoning over visual documents, taking into account both textual semantics and spatial layout. Our model differs from existing multimodal LLMs by avoiding expensive image encoders and focuses exclusively on bounding box information to incorporate the spatial layout structure. Specifically, the cross-alignment between text and spatial modalities is captured by decomposing the attention mechanism in classical transformers to a set of disentangled matrices. Furthermore, we devise a pre-training objective that learns to infill text segments. This approach allows us to address irregular layouts and heterogeneous content frequently encountered in visual documents. The pre-trained model is fine-tuned using a large-scale instruction dataset, covering four core document intelligence tasks. We demonstrate that our solution outperforms SotA LLMs on 14 out of 16 datasets across all tasks, and generalizes well to 4 out of 5 previously unseen datasets.
A Structural-Clustering Based Active Learning for Graph Neural Networks
Dec 07, 2023



In active learning for graph-structured data, Graph Neural Networks (GNNs) have shown effectiveness. However, a common challenge in these applications is the underutilization of crucial structural information. To address this problem, we propose the Structural-Clustering PageRank method for improved Active learning (SPA) specifically designed for graph-structured data. SPA integrates community detection using the SCAN algorithm with the PageRank scoring method for efficient and informative sample selection. SPA prioritizes nodes that are not only informative but also central in structure. Through extensive experiments, SPA demonstrates higher accuracy and macro-F1 score over existing methods across different annotation budgets and achieves significant reductions in query time. In addition, the proposed method only adds two hyperparameters, $\epsilon$ and $\mu$ in the algorithm to finely tune the balance between structural learning and node selection. This simplicity is a key advantage in active learning scenarios, where extensive hyperparameter tuning is often impractical.
Heterophily-Based Graph Neural Network for Imbalanced Classification
Oct 12, 2023



Graph neural networks (GNNs) have shown promise in addressing graph-related problems, including node classification. However, conventional GNNs assume an even distribution of data across classes, which is often not the case in real-world scenarios, where certain classes are severely underrepresented. This leads to suboptimal performance of standard GNNs on imbalanced graphs. In this paper, we introduce a unique approach that tackles imbalanced classification on graphs by considering graph heterophily. We investigate the intricate relationship between class imbalance and graph heterophily, revealing that minority classes not only exhibit a scarcity of samples but also manifest lower levels of homophily, facilitating the propagation of erroneous information among neighboring nodes. Drawing upon this insight, we propose an efficient method, called Fast Im-GBK, which integrates an imbalance classification strategy with heterophily-aware GNNs to effectively address the class imbalance problem while significantly reducing training time. Our experiments on real-world graphs demonstrate our model's superiority in classification performance and efficiency for node classification tasks compared to existing baselines.
Can GPT models be Financial Analysts? An Evaluation of ChatGPT and GPT-4 on mock CFA Exams
Oct 12, 2023



Large Language Models (LLMs) have demonstrated remarkable performance on a wide range of Natural Language Processing (NLP) tasks, often matching or even beating state-of-the-art task-specific models. This study aims at assessing the financial reasoning capabilities of LLMs. We leverage mock exam questions of the Chartered Financial Analyst (CFA) Program to conduct a comprehensive evaluation of ChatGPT and GPT-4 in financial analysis, considering Zero-Shot (ZS), Chain-of-Thought (CoT), and Few-Shot (FS) scenarios. We present an in-depth analysis of the models' performance and limitations, and estimate whether they would have a chance at passing the CFA exams. Finally, we outline insights into potential strategies and improvements to enhance the applicability of LLMs in finance. In this perspective, we hope this work paves the way for future studies to continue enhancing LLMs for financial reasoning through rigorous evaluation.
MOLE: MOdular Learning FramEwork via Mutual Information Maximization
Aug 15, 2023This paper is to introduce an asynchronous and local learning framework for neural networks, named Modular Learning Framework (MOLE). This framework modularizes neural networks by layers, defines the training objective via mutual information for each module, and sequentially trains each module by mutual information maximization. MOLE makes the training become local optimization with gradient-isolated across modules, and this scheme is more biologically plausible than BP. We run experiments on vector-, grid- and graph-type data. In particular, this framework is capable of solving both graph- and node-level tasks for graph-type data. Therefore, MOLE has been experimentally proven to be universally applicable to different types of data.
Enhancing Adversarial Training via Reweighting Optimization Trajectory
Jul 07, 2023



Despite the fact that adversarial training has become the de facto method for improving the robustness of deep neural networks, it is well-known that vanilla adversarial training suffers from daunting robust overfitting, resulting in unsatisfactory robust generalization. A number of approaches have been proposed to address these drawbacks such as extra regularization, adversarial weights perturbation, and training with more data over the last few years. However, the robust generalization improvement is yet far from satisfactory. In this paper, we approach this challenge with a brand new perspective -- refining historical optimization trajectories. We propose a new method named \textbf{Weighted Optimization Trajectories (WOT)} that leverages the optimization trajectories of adversarial training in time. We have conducted extensive experiments to demonstrate the effectiveness of WOT under various state-of-the-art adversarial attacks. Our results show that WOT integrates seamlessly with the existing adversarial training methods and consistently overcomes the robust overfitting issue, resulting in better adversarial robustness. For example, WOT boosts the robust accuracy of AT-PGD under AA-$L_{\infty}$ attack by 1.53\% $\sim$ 6.11\% and meanwhile increases the clean accuracy by 0.55\%$\sim$5.47\% across SVHN, CIFAR-10, CIFAR-100, and Tiny-ImageNet datasets.
* Accepted by ECML 2023