 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge(PASS) Visual Prompt Locates Good Structure Sparsity through a Recurrent HyperNetwork
Paper and Code



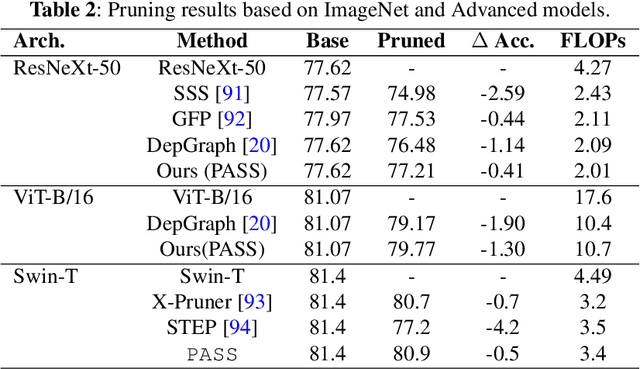
Large-scale neural networks have demonstrated remarkable performance in different domains like vision and language processing, although at the cost of massive computation resources. As illustrated by compression literature, structural model pruning is a prominent algorithm to encourage model efficiency, thanks to its acceleration-friendly sparsity patterns. One of the key questions of structural pruning is how to estimate the channel significance. In parallel, work on data-centric AI has shown that prompting-based techniques enable impressive generalization of large language models across diverse downstream tasks. In this paper, we investigate a charming possibility - \textit{leveraging visual prompts to capture the channel importance and derive high-quality structural sparsity}. To this end, we propose a novel algorithmic framework, namely \texttt{PASS}. It is a tailored hyper-network to take both visual prompts and network weight statistics as input, and output layer-wise channel sparsity in a recurrent manner. Such designs consider the intrinsic channel dependency between layers. Comprehensive experiments across multiple network architectures and six datasets demonstrate the superiority of \texttt{PASS} in locating good structural sparsity. For example, at the same FLOPs level, \texttt{PASS} subnetworks achieve $1\%\sim 3\%$ better accuracy on Food101 dataset; or with a similar performance of $80\%$ accuracy, \texttt{PASS} subnetworks obtain $0.35\times$ more speedup than the baselines.