 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge(PASS) Visual Prompt Locates Good Structure Sparsity through a Recurrent HyperNetwork
Jul 24, 2024


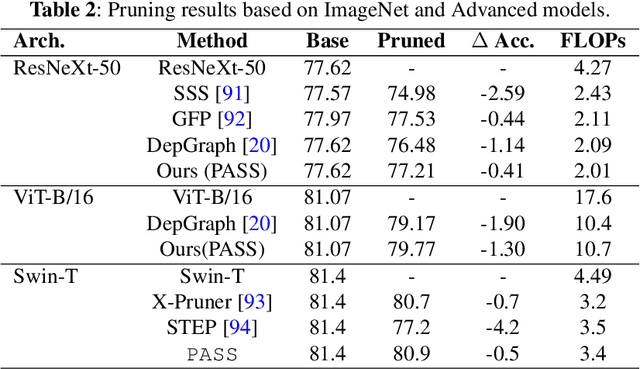
Large-scale neural networks have demonstrated remarkable performance in different domains like vision and language processing, although at the cost of massive computation resources. As illustrated by compression literature, structural model pruning is a prominent algorithm to encourage model efficiency, thanks to its acceleration-friendly sparsity patterns. One of the key questions of structural pruning is how to estimate the channel significance. In parallel, work on data-centric AI has shown that prompting-based techniques enable impressive generalization of large language models across diverse downstream tasks. In this paper, we investigate a charming possibility - \textit{leveraging visual prompts to capture the channel importance and derive high-quality structural sparsity}. To this end, we propose a novel algorithmic framework, namely \texttt{PASS}. It is a tailored hyper-network to take both visual prompts and network weight statistics as input, and output layer-wise channel sparsity in a recurrent manner. Such designs consider the intrinsic channel dependency between layers. Comprehensive experiments across multiple network architectures and six datasets demonstrate the superiority of \texttt{PASS} in locating good structural sparsity. For example, at the same FLOPs level, \texttt{PASS} subnetworks achieve $1\%\sim 3\%$ better accuracy on Food101 dataset; or with a similar performance of $80\%$ accuracy, \texttt{PASS} subnetworks obtain $0.35\times$ more speedup than the baselines.
Curriculum Learning with Quality-Driven Data Selection
Jun 27, 2024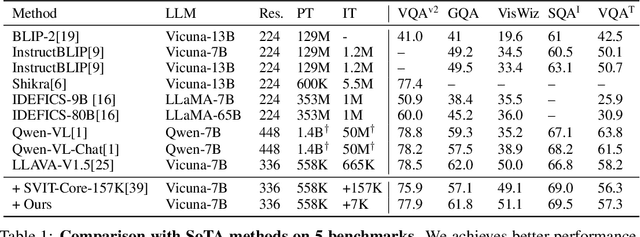
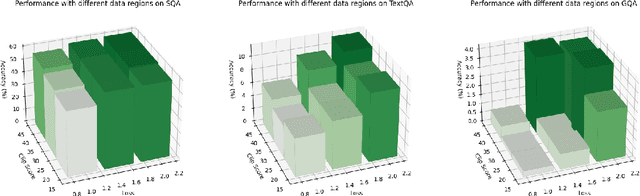
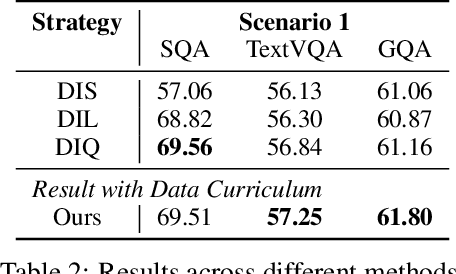
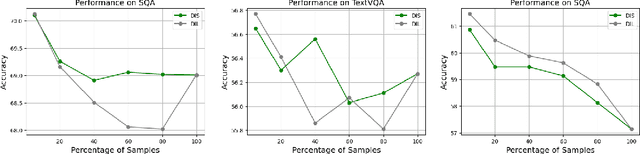
The impressive multimodal capabilities demonstrated by OpenAI's GPT-4 have generated significant interest in the development of Multimodal Large Language Models (MLLMs). Visual instruction tuning of MLLMs with machine-generated instruction-following data has shown to enhance zero-shot capabilities across various tasks. However, there has been limited exploration into controlling the quality of the instruction data.Current methodologies for data selection in MLLMs often rely on single, unreliable scores or use downstream tasks for selection, which is time-consuming and can lead to potential overfitting on the chosen evaluation datasets. To mitigate these limitations, we propose a novel data selection methodology that utilizes image-text correlation and model perplexity to evaluate and select data of varying quality. This approach leverages the distinct distribution of these two attributes, mapping data quality into a two-dimensional space that allows for the selection of data based on their location within this distribution. By utilizing this space, we can analyze the impact of task type settings, used as prompts, on data quality. Additionally, this space can be used to construct multi-stage subsets of varying quality to facilitate curriculum learning. Our research includes comprehensive experiments conducted on various datasets. The results emphasize substantial enhancements in five commonly assessed capabilities compared to using the complete dataset. Our codes, data, and models are publicly available at: \url{https://anonymous.4open.science/r/EHIT-31B4}
Lottery Pools: Winning More by Interpolating Tickets without Increasing Training or Inference Cost
Aug 23, 2022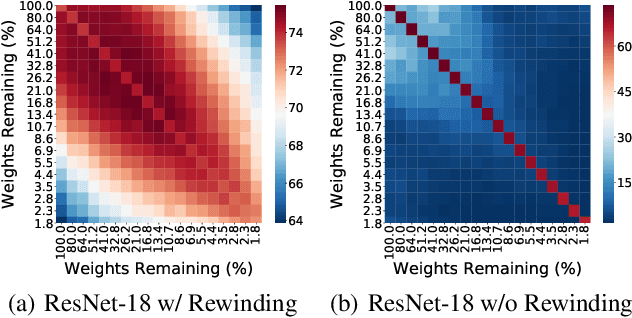
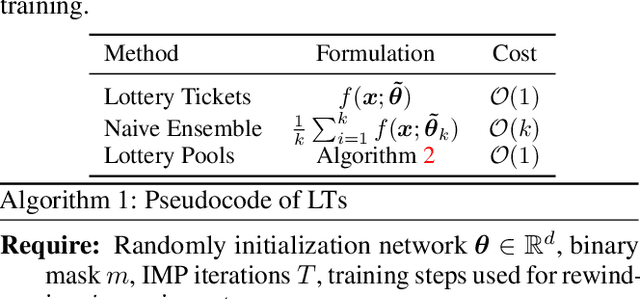
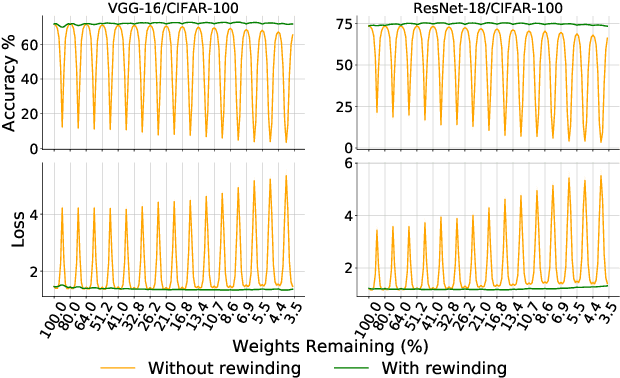

Lottery tickets (LTs) is able to discover accurate and sparse subnetworks that could be trained in isolation to match the performance of dense networks. Ensemble, in parallel, is one of the oldest time-proven tricks in machine learning to improve performance by combining the output of multiple independent models. However, the benefits of ensemble in the context of LTs will be diluted since ensemble does not directly lead to stronger sparse subnetworks, but leverages their predictions for a better decision. In this work, we first observe that directly averaging the weights of the adjacent learned subnetworks significantly boosts the performance of LTs. Encouraged by this observation, we further propose an alternative way to perform an 'ensemble' over the subnetworks identified by iterative magnitude pruning via a simple interpolating strategy. We call our method Lottery Pools. In contrast to the naive ensemble which brings no performance gains to each single subnetwork, Lottery Pools yields much stronger sparse subnetworks than the original LTs without requiring any extra training or inference cost. Across various modern architectures on CIFAR-10/100 and ImageNet, we show that our method achieves significant performance gains in both, in-distribution and out-of-distribution scenarios. Impressively, evaluated with VGG-16 and ResNet-18, the produced sparse subnetworks outperform the original LTs by up to 1.88% on CIFAR-100 and 2.36% on CIFAR-100-C; the resulting dense network surpasses the pre-trained dense-model up to 2.22% on CIFAR-100 and 2.38% on CIFAR-100-C.