 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCurriculum Learning with Quality-Driven Data Selection
Paper and Code
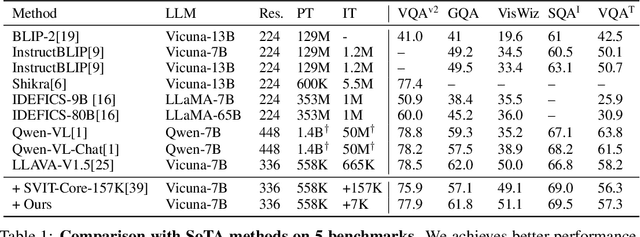
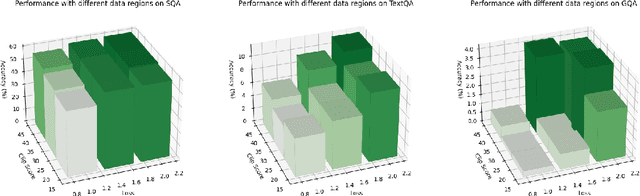
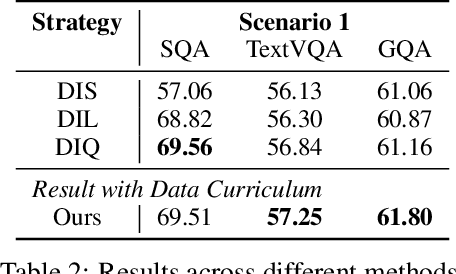
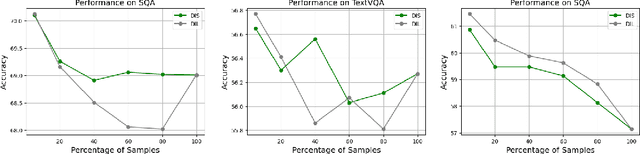
The impressive multimodal capabilities demonstrated by OpenAI's GPT-4 have generated significant interest in the development of Multimodal Large Language Models (MLLMs). Visual instruction tuning of MLLMs with machine-generated instruction-following data has shown to enhance zero-shot capabilities across various tasks. However, there has been limited exploration into controlling the quality of the instruction data.Current methodologies for data selection in MLLMs often rely on single, unreliable scores or use downstream tasks for selection, which is time-consuming and can lead to potential overfitting on the chosen evaluation datasets. To mitigate these limitations, we propose a novel data selection methodology that utilizes image-text correlation and model perplexity to evaluate and select data of varying quality. This approach leverages the distinct distribution of these two attributes, mapping data quality into a two-dimensional space that allows for the selection of data based on their location within this distribution. By utilizing this space, we can analyze the impact of task type settings, used as prompts, on data quality. Additionally, this space can be used to construct multi-stage subsets of varying quality to facilitate curriculum learning. Our research includes comprehensive experiments conducted on various datasets. The results emphasize substantial enhancements in five commonly assessed capabilities compared to using the complete dataset. Our codes, data, and models are publicly available at: \url{https://anonymous.4open.science/r/EHIT-31B4}