 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Am I Missing? Question-Answering as Hidden State Probing
May 29, 2026Test-time reasoning has become a significant field of study since the introduction of chain-of-thought reasoning in large language models (LLMs). However, the mechanisms of this reasoning process are still under-explored -- from the same input prompt, and even the same partial solution, LLMs can produce varied answers if sampled multiple times. We propose to leverage question-asking as an inference-time intervention that articulates information about the model's hidden state. To achieve that, we present a student-teacher setting where a student asks questions to a teacher. We train a probe on the student's hidden state before and after asking a question and find it is predictive of the trajectory's final correctness, even before generating the teacher's answer. This suggests there is a meaningful signal from the self-diagnosis that occurs during question generation rather than information transfer from the teacher. We then frame question-asking as a sequential decision problem, using this probe as a quality score, and define a gating policy to ask questions that maximize likelihood of correctness. We find that the success of question-asking as an intervention is largely dependent on the model's self-consistency. Our empirical results show a gap between detection and recovery; while our gating policy captures model correctness and uncertainty, interventions are equally likely to harm correct trajectories as they are to recover incorrect ones. This gap between diagnosis and correction has broader implications on language models' capacity for self-refinement under uncertainty.
Chronicle: A Multimodal Foundation Model for Joint Language and Time Series Understanding
May 18, 2026Real-world time series come with text: metadata, descriptions, news, reports. Yet time series foundation models process numerical sequences in isolation, and the multimodal text-and-time-series models that attempt to bridge the two all adapt a pretrained language model post hoc, inheriting representations shaped without ever seeing temporal data. These models are also evaluated almost exclusively against other multimodal baselines, not against the strongest unimodal foundation models in either domain, leaving open whether joint training is needed at all. We present Chronicle, a compact 324M-parameter decoder-only transformer trained from scratch on natural language and time series within a single unified architecture. Both modalities share the same transformer blocks, attention mechanism, and residual stream; the bulk of pretraining uses unimodal batches so cross-modal capability emerges purely from shared parameters, with a short alignment stage that interleaves the two. To our knowledge, Chronicle is the first model jointly pretrained on text and time series from scratch, and the first multimodal model evaluated against dedicated foundation models in both domains. It matches Gemma-3-270M-PT on 19 NLU tasks, sets a new bar for frozen-embedding time series classification on 24 UCR/UEA datasets, and produces multimodal forecasts on Time-MMD that beat every supervised fusion baseline, all from a single backbone.
ADAPTive Input Training for Many-to-One Pre-Training on Time-Series Classification
Apr 09, 2026Recent work on time-series models has leveraged self-supervised training to learn meaningful features and patterns in order to improve performance on downstream tasks and generalize to unseen modalities. While these pretraining methods have shown great promise in one-to-many scenarios, where a model is pre-trained on one dataset and fine-tuned on a downstream dataset, they have struggled to generalize to new datasets when more datasets are added during pre-training. This is a fundamental challenge in building foundation models for time-series data, as it limits the ability to develop models that can learn from a large variety of diverse datasets available. To address this challenge, we present a new pre-training paradigm for time-series data called ADAPT, which can efficiently align the physical properties of data in the time-series domain, enabling mixed-batch pre-training despite the extreme discrepancies in the input sizes and channel dimensions of pre-training data. We trained on 162 time-series classification datasets and set new state-of-the-art performance for classification benchmarks. We successfully train a model within the time-series domain on a wide range of datasets simultaneously, which is a major building block for building generalist foundation models in time-series domains.
Jump Start or False Start? A Theoretical and Empirical Evaluation of LLM-initialized Bandits
Apr 02, 2026The recent advancement of Large Language Models (LLMs) offers new opportunities to generate user preference data to warm-start bandits. Recent studies on contextual bandits with LLM initialization (CBLI) have shown that these synthetic priors can significantly lower early regret. However, these findings assume that LLM-generated choices are reasonably aligned with actual user preferences. In this paper, we systematically examine how LLM-generated preferences perform when random and label-flipping noise is injected into the synthetic training data. For aligned domains, we find that warm-starting remains effective up to 30% corruption, loses its advantage around 40%, and degrades performance beyond 50%. When there is systematic misalignment, even without added noise, LLM-generated priors can lead to higher regret than a cold-start bandit. To explain these behaviors, we develop a theoretical analysis that decomposes the effect of random label noise and systematic misalignment on the prior error driving the bandit's regret, and derive a sufficient condition under which LLM-based warm starts are provably better than a cold-start bandit. We validate these results across multiple conjoint datasets and LLMs, showing that estimated alignment reliably tracks when warm-starting improves or degrades recommendation quality.
On the Robustness of Verbal Confidence of LLMs in Adversarial Attacks
Jul 09, 2025



Robust verbal confidence generated by large language models (LLMs) is crucial for the deployment of LLMs to ensure transparency, trust, and safety in human-AI interactions across many high-stakes applications. In this paper, we present the first comprehensive study on the robustness of verbal confidence under adversarial attacks. We introduce a novel framework for attacking verbal confidence scores through both perturbation and jailbreak-based methods, and show that these attacks can significantly jeopardize verbal confidence estimates and lead to frequent answer changes. We examine a variety of prompting strategies, model sizes, and application domains, revealing that current confidence elicitation methods are vulnerable and that commonly used defence techniques are largely ineffective or counterproductive. Our findings underscore the urgent need to design more robust mechanisms for confidence expression in LLMs, as even subtle semantic-preserving modifications can lead to misleading confidence in responses.
SPARE: Single-Pass Annotation with Reference-Guided Evaluation for Automatic Process Supervision and Reward Modelling
Jun 18, 2025Process or step-wise supervision has played a crucial role in advancing complex multi-step reasoning capabilities of Large Language Models (LLMs). However, efficient, high-quality automated process annotation remains a significant challenge. To address this, we introduce Single-Pass Annotation with Reference-Guided Evaluation (SPARE), a novel structured framework that enables single-pass, per-step annotation by aligning each solution step to one or multiple steps in a reference solution, accompanied by explicit reasoning for evaluation. We show that reference-guided step-level evaluation effectively facilitates process supervision on four datasets spanning three domains: mathematical reasoning, multi-hop compositional question answering, and spatial reasoning. We demonstrate that SPARE, when compared to baselines, improves reasoning performance when used for: (1) fine-tuning models in an offline RL setup for inference-time greedy-decoding, and (2) training reward models for ranking/aggregating multiple LLM-generated outputs. Additionally, SPARE achieves competitive performance on challenging mathematical datasets while offering 2.6 times greater efficiency, requiring only 38% of the runtime, compared to tree search-based automatic annotation. The codebase, along with a trained SPARE-PRM model, is publicly released to facilitate further research and reproducibility.
Towards Robust Dialogue Breakdown Detection: Addressing Disruptors in Large Language Models with Self-Guided Reasoning
Apr 26, 2025


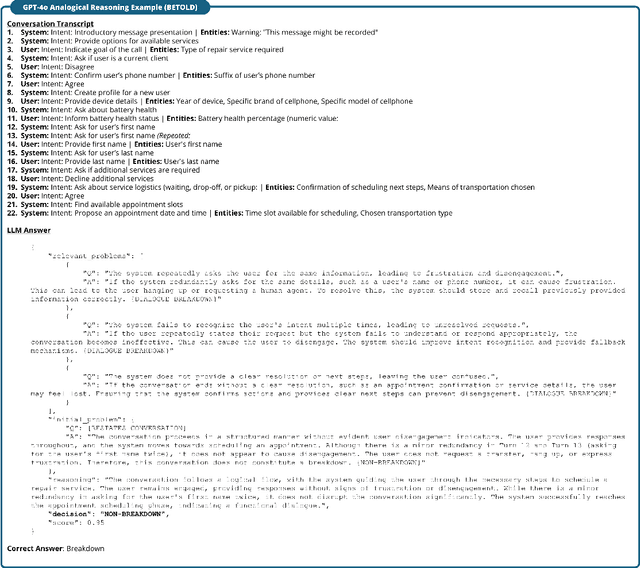
Large language models (LLMs) are rapidly changing various domains. However, their capabilities in handling conversational breakdowns still require an in-depth exploration. This paper addresses the challenge of detecting and mitigating dialogue breakdowns within LLM-driven conversational systems. While powerful models from OpenAI and Anthropic excel in many dialogue tasks, they can still produce incoherent or contradictory responses, commonly referred to as breakdowns, which undermine user trust. To tackle this, we propose an approach that combines specialized fine-tuning with advanced prompting strategies, including few-shot learning, chain-of-thought reasoning, and analogical prompting. In particular, we fine-tune a small 8B model and demonstrate its robust classification and calibration capabilities in English and Japanese dialogue. We also validate its generalization on the BETOLD dataset, achieving a 7\% accuracy improvement over its base model. Furthermore, we introduce a real-time deployment architecture that selectively escalates suspicious responses to more resource-intensive frontier models only when breakdowns are detected, significantly cutting operational expenses and energy consumption. Experimental results show our method surpasses prior state-of-the-art specialized classifiers while also narrowing performance gaps between smaller open-source models and large proprietary ones. Our approach offers a scalable solution for robust conversational AI in high-impact domains by combining efficiency, interpretability, and reliability.
Entropy-Aware Branching for Improved Mathematical Reasoning
Mar 27, 2025While Large Language Models (LLMs) are effectively aligned through extensive pre-training and fine-tuning, they still struggle with varying levels of uncertainty during token generation. In our investigation of mathematical reasoning, we observe that errors are more likely to arise at tokens exhibiting high entropy and variance of entropy in the model's output distribution. Based on the observation, we propose a novel approach that dynamically branches the generation process on demand instead of defaulting to the single most probable token. By exploring in parallel multiple branches stemming from high probability tokens of critical decision points, the model can discover diverse reasoning paths that might otherwise be missed. We further harness external feedback from larger models to rank and select the most coherent and accurate reasoning branch. Our experimental results on mathematical word problems and calculation questions show that this branching strategy boosts the reasoning capabilities of small LLMs up to 4.6% compared to conventional argmax decoding.
Chat-TS: Enhancing Multi-Modal Reasoning Over Time-Series and Natural Language Data
Mar 13, 2025



Time-series analysis is critical for a wide range of fields such as healthcare, finance, transportation, and energy, among many others. The practical applications often involve analyzing time-series data alongside contextual information in the form of natural language to support informed decisions. However, current time-series models are limited in their ability to perform reasoning that involves both time-series and their textual content. In this work, we address this gap by introducing \textit{Chat-TS}, a large language model (LLM) based framework, designed to support reasoning over time series and textual data. Unlike traditional models, Chat-TS integrates time-series tokens into LLMs' vocabulary, enhancing its reasoning ability over both modalities without compromising the core natural language capabilities, enabling practical analysis and reasoning across modalities. To support learning and evaluation in this setup, we contribute new datasets: the \textit{TS Instruct Training Dataset} which pairs diverse time-series data with relevant text instructions and responses for instruction tuning, the \textit{TS Instruct Question and Answer (QA) Gold Dataset} which provides multiple-choice questions designed to evaluate multimodal reasoning, and a \textit{TS Instruct Quantitative Probing Set} which contains a small subset of the TS Instruct QA tasks alongside math and decision-making questions for LLM evaluation. We designed a training strategy to preserve the inherent reasoning capabilities of LLMs while augmenting them for time-series reasoning. Experiments show that Chat-TS achieves state-of-the-art performance in multi-modal reasoning tasks by maintaining strong natural language proficiency while improving time-series reasoning. ~\footnote{To ensure replicability and facilitate future research, all models, datasets, and code will be available at [\texttt{Github-URL}].}
Error Diversity Matters: An Error-Resistant Ensemble Method for Unsupervised Dependency Parsing
Dec 16, 2024We address unsupervised dependency parsing by building an ensemble of diverse existing models through post hoc aggregation of their output dependency parse structures. We observe that these ensembles often suffer from low robustness against weak ensemble components due to error accumulation. To tackle this problem, we propose an efficient ensemble-selection approach that avoids error accumulation. Results demonstrate that our approach outperforms each individual model as well as previous ensemble techniques. Additionally, our experiments show that the proposed ensemble-selection method significantly enhances the performance and robustness of our ensemble, surpassing previously proposed strategies, which have not accounted for error diversity.