 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeError Diversity Matters: An Error-Resistant Ensemble Method for Unsupervised Dependency Parsing
Dec 16, 2024We address unsupervised dependency parsing by building an ensemble of diverse existing models through post hoc aggregation of their output dependency parse structures. We observe that these ensembles often suffer from low robustness against weak ensemble components due to error accumulation. To tackle this problem, we propose an efficient ensemble-selection approach that avoids error accumulation. Results demonstrate that our approach outperforms each individual model as well as previous ensemble techniques. Additionally, our experiments show that the proposed ensemble-selection method significantly enhances the performance and robustness of our ensemble, surpassing previously proposed strategies, which have not accounted for error diversity.
EBBS: An Ensemble with Bi-Level Beam Search for Zero-Shot Machine Translation
Feb 29, 2024
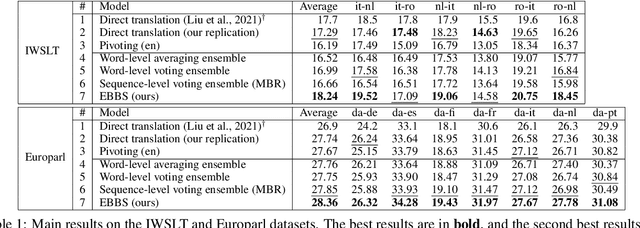

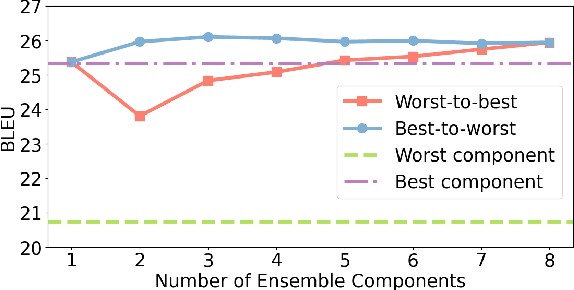
The ability of zero-shot translation emerges when we train a multilingual model with certain translation directions; the model can then directly translate in unseen directions. Alternatively, zero-shot translation can be accomplished by pivoting through a third language (e.g., English). In our work, we observe that both direct and pivot translations are noisy and achieve less satisfactory performance. We propose EBBS, an ensemble method with a novel bi-level beam search algorithm, where each ensemble component explores its own prediction step by step at the lower level but they are synchronized by a "soft voting" mechanism at the upper level. Results on two popular multilingual translation datasets show that EBBS consistently outperforms direct and pivot translations as well as existing ensemble techniques. Further, we can distill the ensemble's knowledge back to the multilingual model to improve inference efficiency; profoundly, our EBBS-based distillation does not sacrifice, or even improves, the translation quality.
Ensemble-Based Unsupervised Discontinuous Constituency Parsing by Tree Averaging
Feb 29, 2024We address unsupervised discontinuous constituency parsing, where we observe a high variance in the performance of the only previous model. We propose to build an ensemble of different runs of the existing discontinuous parser by averaging the predicted trees, to stabilize and boost performance. To begin with, we provide comprehensive computational complexity analysis (in terms of P and NP-complete) for tree averaging under different setups of binarity and continuity. We then develop an efficient exact algorithm to tackle the task, which runs in a reasonable time for all samples in our experiments. Results on three datasets show our method outperforms all baselines in all metrics; we also provide in-depth analyses of our approach.
Ensemble Distillation for Unsupervised Constituency Parsing
Oct 03, 2023We investigate the unsupervised constituency parsing task, which organizes words and phrases of a sentence into a hierarchical structure without using linguistically annotated data. We observe that existing unsupervised parsers capture differing aspects of parsing structures, which can be leveraged to enhance unsupervised parsing performance. To this end, we propose a notion of "tree averaging," based on which we further propose a novel ensemble method for unsupervised parsing. To improve inference efficiency, we further distill the ensemble knowledge into a student model; such an ensemble-then-distill process is an effective approach to mitigate the over-smoothing problem existing in common multi-teacher distilling methods. Experiments show that our method surpasses all previous approaches, consistently demonstrating its effectiveness and robustness across various runs, with different ensemble components, and under domain-shift conditions.