 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoRAQuant: Mixed-Precision Quantization of LoRA to Ultra-Low Bits
Oct 30, 2025Low-Rank Adaptation (LoRA) has become a popular technique for parameter-efficient fine-tuning of large language models (LLMs). In many real-world scenarios, multiple adapters are loaded simultaneously to enable LLM customization for personalized user experiences or to support a diverse range of tasks. Although each adapter is lightweight in isolation, their aggregate cost becomes substantial at scale. To address this, we propose LoRAQuant, a mixed-precision post-training quantization method tailored to LoRA. Specifically, LoRAQuant reparameterizes each adapter by singular value decomposition (SVD) to concentrate the most important information into specific rows and columns. This makes it possible to quantize the important components to higher precision, while quantizing the rest to ultra-low bitwidth. We conduct comprehensive experiments with LLaMA 2-7B, LLaMA 2-13B, and Mistral 7B models on mathematical reasoning, coding, and summarization tasks. Results show that our LoRAQuant uses significantly lower bits than other quantization methods, but achieves comparable or even higher performance.
Revisiting Intermediate-Layer Matching in Knowledge Distillation: Layer-Selection Strategy Doesn't Matter (Much)
Feb 06, 2025


Knowledge distillation (KD) is a popular method of transferring knowledge from a large "teacher" model to a small "student" model. KD can be divided into two categories: prediction matching and intermediate-layer matching. We explore an intriguing phenomenon: layer-selection strategy does not matter (much) in intermediate-layer matching. In this paper, we show that seemingly nonsensical matching strategies such as matching the teacher's layers in reverse still result in surprisingly good student performance. We provide an interpretation for this phenomenon by examining the angles between teacher layers viewed from the student's perspective.
EBBS: An Ensemble with Bi-Level Beam Search for Zero-Shot Machine Translation
Feb 29, 2024
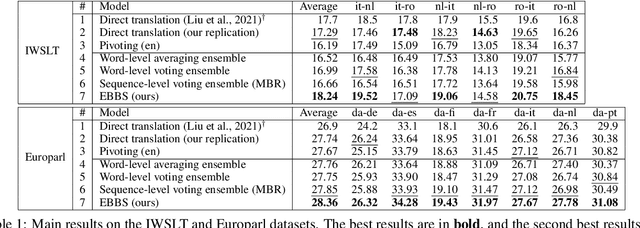

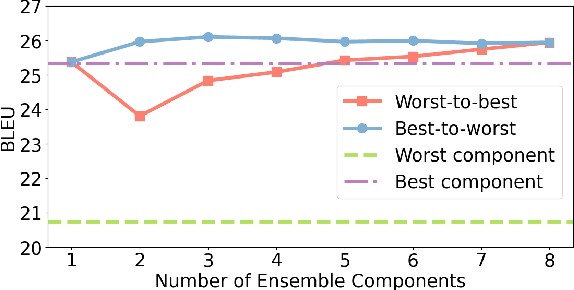
The ability of zero-shot translation emerges when we train a multilingual model with certain translation directions; the model can then directly translate in unseen directions. Alternatively, zero-shot translation can be accomplished by pivoting through a third language (e.g., English). In our work, we observe that both direct and pivot translations are noisy and achieve less satisfactory performance. We propose EBBS, an ensemble method with a novel bi-level beam search algorithm, where each ensemble component explores its own prediction step by step at the lower level but they are synchronized by a "soft voting" mechanism at the upper level. Results on two popular multilingual translation datasets show that EBBS consistently outperforms direct and pivot translations as well as existing ensemble techniques. Further, we can distill the ensemble's knowledge back to the multilingual model to improve inference efficiency; profoundly, our EBBS-based distillation does not sacrifice, or even improves, the translation quality.
Ensemble-Based Unsupervised Discontinuous Constituency Parsing by Tree Averaging
Feb 29, 2024We address unsupervised discontinuous constituency parsing, where we observe a high variance in the performance of the only previous model. We propose to build an ensemble of different runs of the existing discontinuous parser by averaging the predicted trees, to stabilize and boost performance. To begin with, we provide comprehensive computational complexity analysis (in terms of P and NP-complete) for tree averaging under different setups of binarity and continuity. We then develop an efficient exact algorithm to tackle the task, which runs in a reasonable time for all samples in our experiments. Results on three datasets show our method outperforms all baselines in all metrics; we also provide in-depth analyses of our approach.
f-Divergence Minimization for Sequence-Level Knowledge Distillation
Jul 27, 2023



Knowledge distillation (KD) is the process of transferring knowledge from a large model to a small one. It has gained increasing attention in the natural language processing community, driven by the demands of compressing ever-growing language models. In this work, we propose an f-DISTILL framework, which formulates sequence-level knowledge distillation as minimizing a generalized f-divergence function. We propose four distilling variants under our framework and show that existing SeqKD and ENGINE approaches are approximations of our f-DISTILL methods. We further derive step-wise decomposition for our f-DISTILL, reducing intractable sequence-level divergence to word-level losses that can be computed in a tractable manner. Experiments across four datasets show that our methods outperform existing KD approaches, and that our symmetric distilling losses can better force the student to learn from the teacher distribution.
An Equal-Size Hard EM Algorithm for Diverse Dialogue Generation
Sep 29, 2022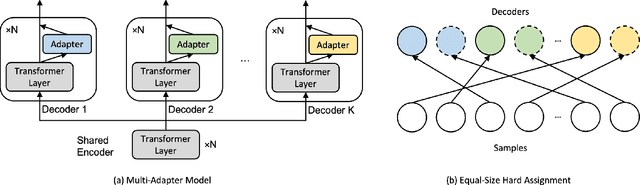
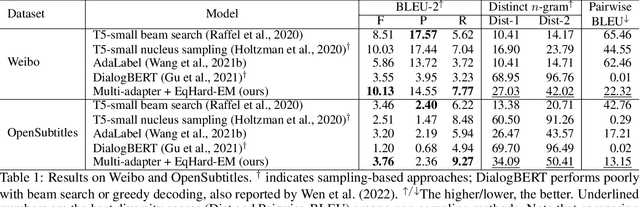
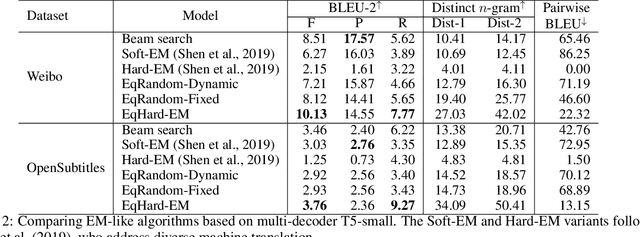
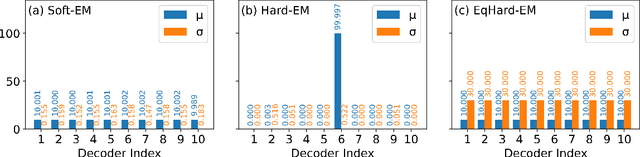
Open-domain dialogue systems aim to interact with humans through natural language texts in an open-ended fashion. However, the widely successful neural networks may not work well for dialogue systems, as they tend to generate generic responses. In this work, we propose an Equal-size Hard Expectation--Maximization (EqHard-EM) algorithm to train a multi-decoder model for diverse dialogue generation. Our algorithm assigns a sample to a decoder in a hard manner and additionally imposes an equal-assignment constraint to ensure that all decoders are well-trained. We provide detailed theoretical analysis to justify our approach. Further, experiments on two large-scale, open-domain dialogue datasets verify that our EqHard-EM algorithm generates high-quality diverse responses.
An Empirical Study on the Overlapping Problem of Open-Domain Dialogue Datasets
Jan 17, 2022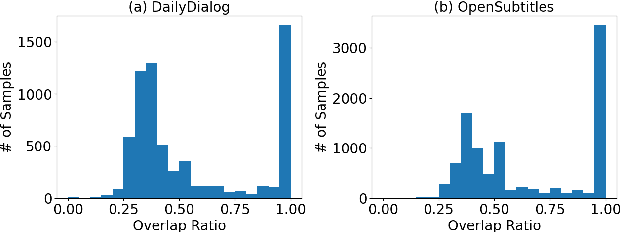

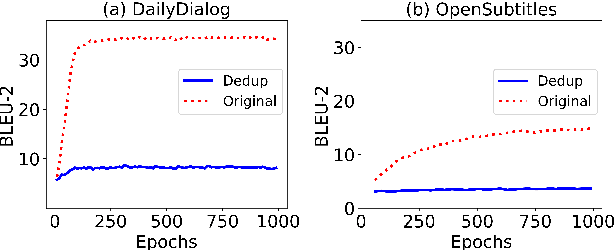

Open-domain dialogue systems aim to converse with humans through text, and its research has heavily relied on benchmark datasets. In this work, we first identify the overlapping problem in DailyDialog and OpenSubtitles, two popular open-domain dialogue benchmark datasets. Our systematic analysis then shows that such overlapping can be exploited to obtain fake state-of-the-art performance. Finally, we address this issue by cleaning these datasets and setting up a proper data processing procedure for future research.