 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Station: An Open-World Environment for AI-Driven Discovery
Nov 09, 2025



We introduce the STATION, an open-world multi-agent environment that models a miniature scientific ecosystem. Leveraging their extended context windows, agents in the Station can engage in long scientific journeys that include reading papers from peers, formulating hypotheses, submitting code, performing analyses, and publishing results. Importantly, there is no centralized system coordinating their activities - agents are free to choose their own actions and develop their own narratives within the Station. Experiments demonstrate that AI agents in the Station achieve new state-of-the-art performance on a wide range of benchmarks, spanning from mathematics to computational biology to machine learning, notably surpassing AlphaEvolve in circle packing. A rich tapestry of narratives emerges as agents pursue independent research, interact with peers, and build upon a cumulative history. From these emergent narratives, novel methods arise organically, such as a new density-adaptive algorithm for scRNA-seq batch integration. The Station marks a first step towards autonomous scientific discovery driven by emergent behavior in an open-world environment, representing a new paradigm that moves beyond rigid optimization.
Thinker: Learning to Think Fast and Slow
May 27, 2025



Recent studies show that the reasoning capabilities of Large Language Models (LLMs) can be improved by applying Reinforcement Learning (RL) to question-answering (QA) tasks in areas such as math and coding. With a long context length, LLMs may learn to perform search, as indicated by the self-correction behavior observed in DeepSeek R1. However, this search behavior is often imprecise and lacks confidence, resulting in long, redundant responses and highlighting deficiencies in intuition and verification. Inspired by the Dual Process Theory in psychology, we introduce a simple modification to the QA task that includes four stages: Fast Thinking, where the LLM must answer within a strict token budget; Verification, where the model evaluates its initial response; Slow Thinking, where it refines the initial response with more deliberation; and Summarization, where it distills the refinement from the previous stage into precise steps. Our proposed task improves average accuracy from 24.9% to 27.9% for Qwen2.5-1.5B, and from 45.9% to 49.8% for DeepSeek-R1-Qwen-1.5B. Notably, for Qwen2.5-1.5B, the Fast Thinking mode alone achieves 26.8% accuracy using fewer than 1000 tokens, demonstrating substantial inference efficiency gains. These findings suggest that intuition and deliberative reasoning are distinct, complementary systems benefiting from targeted training.
Learning from Peers in Reasoning Models
May 12, 2025Large Reasoning Models (LRMs) have the ability to self-correct even when they make mistakes in their reasoning paths. However, our study reveals that when the reasoning process starts with a short but poor beginning, it becomes difficult for the model to recover. We refer to this phenomenon as the "Prefix Dominance Trap". Inspired by psychological findings that peer interaction can promote self-correction without negatively impacting already accurate individuals, we propose **Learning from Peers** (LeaP) to address this phenomenon. Specifically, every tokens, each reasoning path summarizes its intermediate reasoning and shares it with others through a routing mechanism, enabling paths to incorporate peer insights during inference. However, we observe that smaller models sometimes fail to follow summarization and reflection instructions effectively. To address this, we fine-tune them into our **LeaP-T** model series. Experiments on AIME 2024, AIME 2025, AIMO 2025, and GPQA Diamond show that LeaP provides substantial improvements. For instance, QwQ-32B with LeaP achieves nearly 5 absolute points higher than the baseline on average, and surpasses DeepSeek-R1-671B on three math benchmarks with an average gain of 3.3 points. Notably, our fine-tuned LeaP-T-7B matches the performance of DeepSeek-R1-Distill-Qwen-14B on AIME 2024. In-depth analysis reveals LeaP's robust error correction by timely peer insights, showing strong error tolerance and handling varied task difficulty. LeaP marks a milestone by enabling LRMs to collaborate during reasoning. Our code, datasets, and models are available at https://learning-from-peers.github.io/ .
Learning from Failures in Multi-Attempt Reinforcement Learning
Mar 04, 2025Recent advancements in reinforcement learning (RL) for large language models (LLMs), exemplified by DeepSeek R1, have shown that even a simple question-answering task can substantially improve an LLM's reasoning capabilities. In this work, we extend this approach by modifying the task into a multi-attempt setting. Instead of generating a single response per question, the model is given multiple attempts, with feedback provided after incorrect responses. The multi-attempt task encourages the model to refine its previous attempts and improve search efficiency. Experimental results show that even a small LLM trained on a multi-attempt task achieves significantly higher accuracy when evaluated with more attempts, improving from 45.6% with 1 attempt to 52.5% with 2 attempts on the math benchmark. In contrast, the same LLM trained on a standard single-turn task exhibits only a marginal improvement, increasing from 42.3% to 43.2% when given more attempts during evaluation. The results indicate that, compared to the standard single-turn task, an LLM trained on a multi-attempt task achieves slightly better performance on math benchmarks while also learning to refine its responses more effectively based on user feedback. Full code is available at https://github.com/DualityRL/multi-attempt
Finite State Automata Inside Transformers with Chain-of-Thought: A Mechanistic Study on State Tracking
Feb 27, 2025



Chain-of-Thought (CoT) significantly enhances the performance of large language models (LLMs) across a wide range of tasks, and prior research shows that CoT can theoretically increase expressiveness. However, there is limited mechanistic understanding of the algorithms that Transformer+CoT can learn. In this work, we (1) evaluate the state tracking capabilities of Transformer+CoT and its variants, confirming the effectiveness of CoT. (2) Next, we identify the circuit, a subset of model components, responsible for tracking the world state, finding that late-layer MLP neurons play a key role. We propose two metrics, compression and distinction, and show that the neuron sets for each state achieve nearly 100% accuracy, providing evidence of an implicit finite state automaton (FSA) embedded within the model. (3) Additionally, we explore three realistic settings: skipping intermediate steps, introducing data noise, and testing length generalization. Our results demonstrate that Transformer+CoT learns robust algorithms (FSA), highlighting its resilience in challenging scenarios.
Towards Understanding Fine-Tuning Mechanisms of LLMs via Circuit Analysis
Feb 17, 2025Fine-tuning significantly improves the performance of Large Language Models (LLMs), yet its underlying mechanisms remain poorly understood. This paper aims to provide an in-depth interpretation of the fine-tuning process through circuit analysis, a popular tool in Mechanistic Interpretability (MI). Unlike previous studies \cite{prakash2024finetuningenhancesexistingmechanisms,chhabra2024neuroplasticity} that focus on tasks where pre-trained models already perform well, we develop a set of mathematical tasks where fine-tuning yields substantial performance gains, which are closer to the practical setting. In our experiments, we identify circuits at various checkpoints during fine-tuning and examine the interplay between circuit analysis, fine-tuning methods, and task complexities. First, we find that while circuits maintain high node similarity before and after fine-tuning, their edges undergo significant changes, which is in contrast to the previous work \cite{prakash2024finetuningenhancesexistingmechanisms,chhabra2024neuroplasticity} that show circuits only add some additional components after fine-tuning. Based on these observations, we develop a circuit-aware Low-Rank Adaptation (LoRA) method, which assigns ranks to layers based on edge changes in the circuits. Experimental results demonstrate that our circuit-based LoRA algorithm achieves an average performance improvement of 2.46\% over standard LoRA with similar parameter sizes. Furthermore, we explore how combining circuits from subtasks can enhance fine-tuning in compositional tasks, providing new insights into the design of such tasks and deepening the understanding of circuit dynamics and fine-tuning mechanisms.
Unlocking Continual Learning Abilities in Language Models
Jun 25, 2024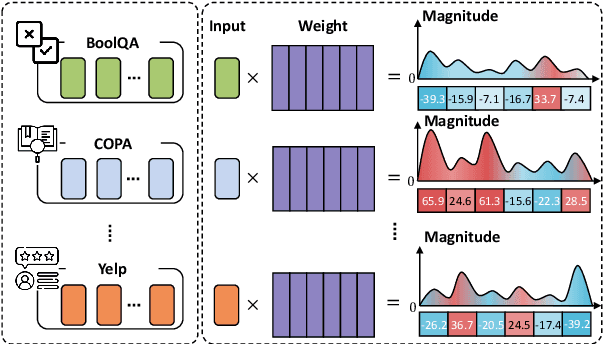
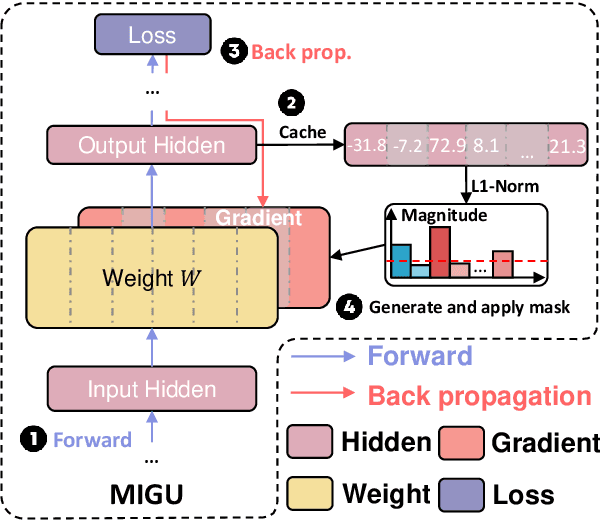
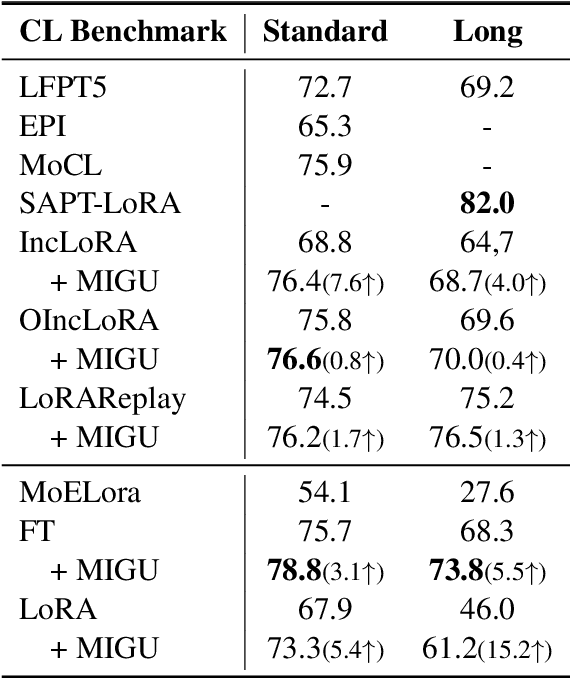
Language models (LMs) exhibit impressive performance and generalization capabilities. However, LMs struggle with the persistent challenge of catastrophic forgetting, which undermines their long-term sustainability in continual learning (CL). Existing approaches usually address the issue by incorporating old task data or task-wise inductive bias into LMs. However, old data and accurate task information are often unavailable or costly to collect, hindering the availability of current CL approaches for LMs. To address this limitation, we introduce $\textbf{MIGU}$ ($\textbf{M}$agn$\textbf{I}$tude-based $\textbf{G}$radient $\textbf{U}$pdating for continual learning), a rehearsal-free and task-label-free method that only updates the model parameters with large magnitudes of output in LMs' linear layers. MIGU is based on our observation that the L1-normalized magnitude distribution of the output in LMs' linear layers is different when the LM models deal with different task data. By imposing this simple constraint on the gradient update process, we can leverage the inherent behaviors of LMs, thereby unlocking their innate CL abilities. Our experiments demonstrate that MIGU is universally applicable to all three LM architectures (T5, RoBERTa, and Llama2), delivering state-of-the-art or on-par performance across continual finetuning and continual pre-training settings on four CL benchmarks. For example, MIGU brings a 15.2% average accuracy improvement over conventional parameter-efficient finetuning baselines in a 15-task CL benchmark. MIGU can also seamlessly integrate with all three existing CL types to further enhance performance. Code is available at \href{https://github.com/wenyudu/MIGU}{this https URL}.
Stacking Your Transformers: A Closer Look at Model Growth for Efficient LLM Pre-Training
May 24, 2024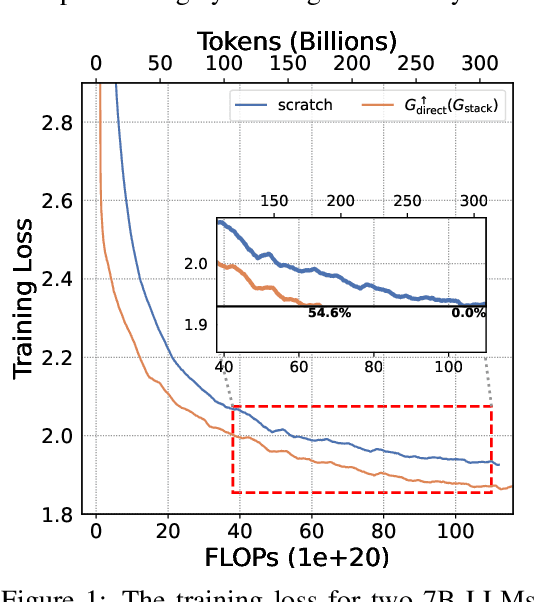

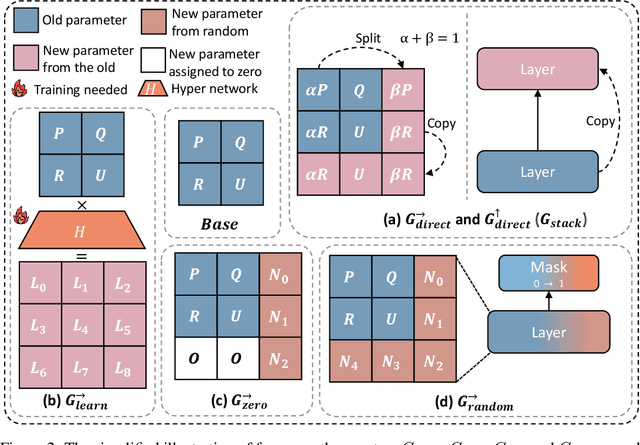

LLMs are computationally expensive to pre-train due to their large scale. Model growth emerges as a promising approach by leveraging smaller models to accelerate the training of larger ones. However, the viability of these model growth methods in efficient LLM pre-training remains underexplored. This work identifies three critical $\underline{\textit{O}}$bstacles: ($\textit{O}$1) lack of comprehensive evaluation, ($\textit{O}$2) untested viability for scaling, and ($\textit{O}$3) lack of empirical guidelines. To tackle $\textit{O}$1, we summarize existing approaches into four atomic growth operators and systematically evaluate them in a standardized LLM pre-training setting. Our findings reveal that a depthwise stacking operator, called $G_{\text{stack}}$, exhibits remarkable acceleration in training, leading to decreased loss and improved overall performance on eight standard NLP benchmarks compared to strong baselines. Motivated by these promising results, we conduct extensive experiments to delve deeper into $G_{\text{stack}}$ to address $\textit{O}$2 and $\textit{O}$3. For $\textit{O}$2 (untested scalability), our study shows that $G_{\text{stack}}$ is scalable and consistently performs well, with experiments up to 7B LLMs after growth and pre-training LLMs with 750B tokens. For example, compared to a conventionally trained 7B model using 300B tokens, our $G_{\text{stack}}$ model converges to the same loss with 194B tokens, resulting in a 54.6\% speedup. We further address $\textit{O}$3 (lack of empirical guidelines) by formalizing guidelines to determine growth timing and growth factor for $G_{\text{stack}}$, making it practical in general LLM pre-training. We also provide in-depth discussions and comprehensive ablation studies of $G_{\text{stack}}$. Our code and pre-trained model are available at $\href{https://llm-stacking.github.io/}{https://llm-stacking.github.io/}$.
m2mKD: Module-to-Module Knowledge Distillation for Modular Transformers
Feb 26, 2024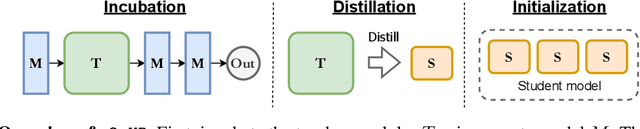
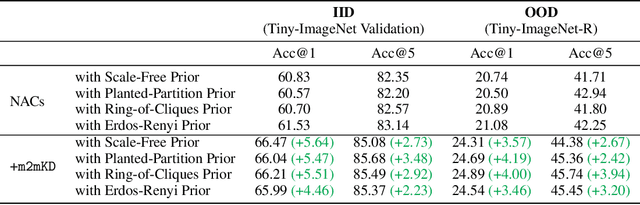
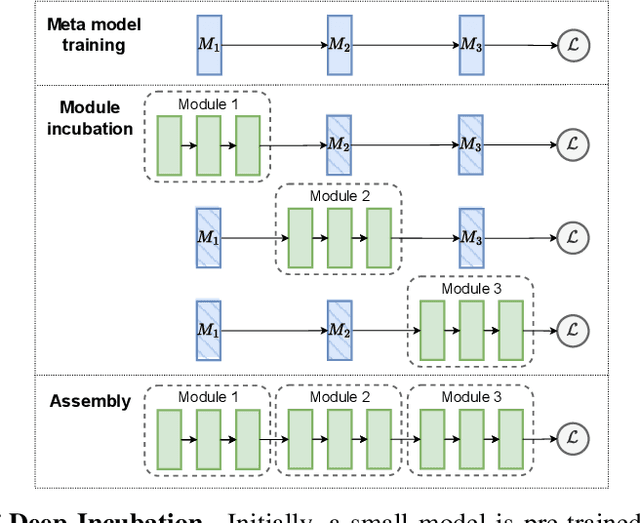
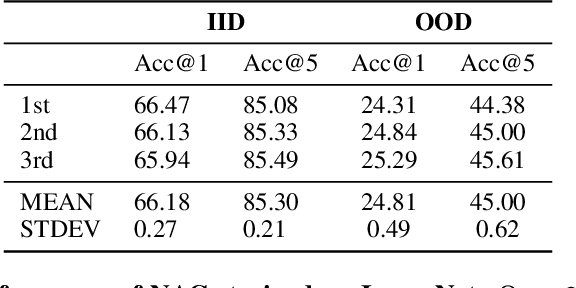
Modular neural architectures are gaining increasing attention due to their powerful capability for generalization and sample-efficient adaptation to new domains. However, training modular models, particularly in the early stages, poses challenges due to the optimization difficulties arising from their intrinsic sparse connectivity. Leveraging the knowledge from monolithic models, using techniques such as knowledge distillation, is likely to facilitate the training of modular models and enable them to integrate knowledge from multiple models pretrained on diverse sources. Nevertheless, conventional knowledge distillation approaches are not tailored to modular models and can fail when directly applied due to the unique architectures and the enormous number of parameters involved. Motivated by these challenges, we propose a general module-to-module knowledge distillation (m2mKD) method for transferring knowledge between modules. Our approach involves teacher modules split from a pretrained monolithic model, and student modules of a modular model. m2mKD separately combines these modules with a shared meta model and encourages the student module to mimic the behaviour of the teacher module. We evaluate the effectiveness of m2mKD on two distinct modular neural architectures: Neural Attentive Circuits (NACs) and Vision Mixture-of-Experts (V-MoE). By applying m2mKD to NACs, we achieve significant improvements in IID accuracy on Tiny-ImageNet (up to 5.6%) and OOD robustness on Tiny-ImageNet-R (up to 4.2%). On average, we observe a 1% gain in both ImageNet and ImageNet-R. The V-MoE-Base model trained using m2mKD also achieves 3.5% higher accuracy than end-to-end training on ImageNet. The experimental results demonstrate that our method offers a promising solution for connecting modular networks with pretrained monolithic models. Code is available at https://github.com/kamanphoebe/m2mKD.
f-Divergence Minimization for Sequence-Level Knowledge Distillation
Jul 27, 2023



Knowledge distillation (KD) is the process of transferring knowledge from a large model to a small one. It has gained increasing attention in the natural language processing community, driven by the demands of compressing ever-growing language models. In this work, we propose an f-DISTILL framework, which formulates sequence-level knowledge distillation as minimizing a generalized f-divergence function. We propose four distilling variants under our framework and show that existing SeqKD and ENGINE approaches are approximations of our f-DISTILL methods. We further derive step-wise decomposition for our f-DISTILL, reducing intractable sequence-level divergence to word-level losses that can be computed in a tractable manner. Experiments across four datasets show that our methods outperform existing KD approaches, and that our symmetric distilling losses can better force the student to learn from the teacher distribution.