 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStep 3.5 Flash: Open Frontier-Level Intelligence with 11B Active Parameters
Feb 11, 2026We introduce Step 3.5 Flash, a sparse Mixture-of-Experts (MoE) model that bridges frontier-level agentic intelligence and computational efficiency. We focus on what matters most when building agents: sharp reasoning and fast, reliable execution. Step 3.5 Flash pairs a 196B-parameter foundation with 11B active parameters for efficient inference. It is optimized with interleaved 3:1 sliding-window/full attention and Multi-Token Prediction (MTP-3) to reduce the latency and cost of multi-round agentic interactions. To reach frontier-level intelligence, we design a scalable reinforcement learning framework that combines verifiable signals with preference feedback, while remaining stable under large-scale off-policy training, enabling consistent self-improvement across mathematics, code, and tool use. Step 3.5 Flash demonstrates strong performance across agent, coding, and math tasks, achieving 85.4% on IMO-AnswerBench, 86.4% on LiveCodeBench-v6 (2024.08-2025.05), 88.2% on tau2-Bench, 69.0% on BrowseComp (with context management), and 51.0% on Terminal-Bench 2.0, comparable to frontier models such as GPT-5.2 xHigh and Gemini 3.0 Pro. By redefining the efficiency frontier, Step 3.5 Flash provides a high-density foundation for deploying sophisticated agents in real-world industrial environments.
BabyVision: Visual Reasoning Beyond Language
Jan 10, 2026While humans develop core visual skills long before acquiring language, contemporary Multimodal LLMs (MLLMs) still rely heavily on linguistic priors to compensate for their fragile visual understanding. We uncovered a crucial fact: state-of-the-art MLLMs consistently fail on basic visual tasks that humans, even 3-year-olds, can solve effortlessly. To systematically investigate this gap, we introduce BabyVision, a benchmark designed to assess core visual abilities independent of linguistic knowledge for MLLMs. BabyVision spans a wide range of tasks, with 388 items divided into 22 subclasses across four key categories. Empirical results and human evaluation reveal that leading MLLMs perform significantly below human baselines. Gemini3-Pro-Preview scores 49.7, lagging behind 6-year-old humans and falling well behind the average adult score of 94.1. These results show despite excelling in knowledge-heavy evaluations, current MLLMs still lack fundamental visual primitives. Progress in BabyVision represents a step toward human-level visual perception and reasoning capabilities. We also explore solving visual reasoning with generation models by proposing BabyVision-Gen and automatic evaluation toolkit. Our code and benchmark data are released at https://github.com/UniPat-AI/BabyVision for reproduction.
m2mKD: Module-to-Module Knowledge Distillation for Modular Transformers
Feb 26, 2024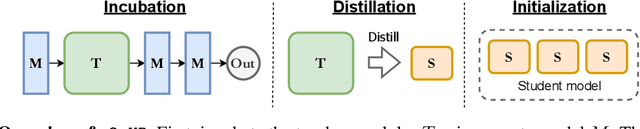
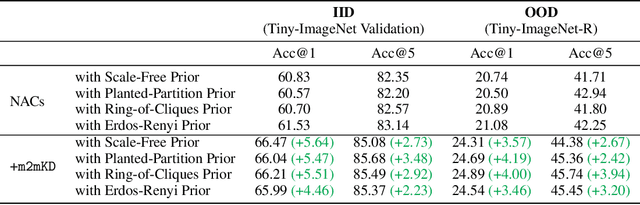
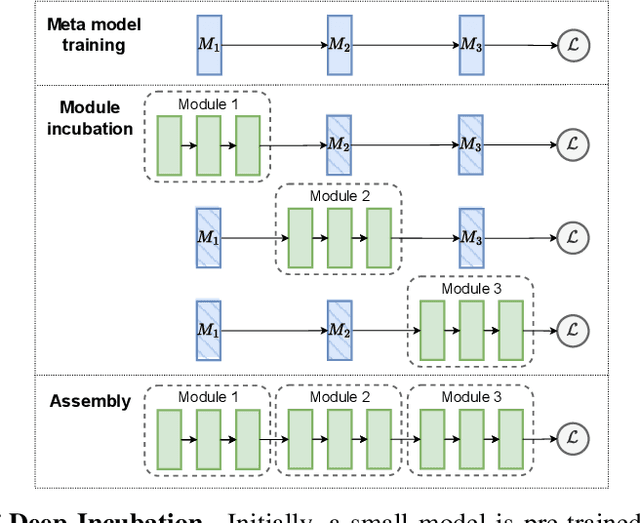
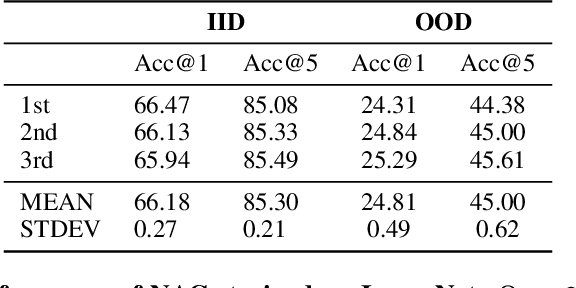
Modular neural architectures are gaining increasing attention due to their powerful capability for generalization and sample-efficient adaptation to new domains. However, training modular models, particularly in the early stages, poses challenges due to the optimization difficulties arising from their intrinsic sparse connectivity. Leveraging the knowledge from monolithic models, using techniques such as knowledge distillation, is likely to facilitate the training of modular models and enable them to integrate knowledge from multiple models pretrained on diverse sources. Nevertheless, conventional knowledge distillation approaches are not tailored to modular models and can fail when directly applied due to the unique architectures and the enormous number of parameters involved. Motivated by these challenges, we propose a general module-to-module knowledge distillation (m2mKD) method for transferring knowledge between modules. Our approach involves teacher modules split from a pretrained monolithic model, and student modules of a modular model. m2mKD separately combines these modules with a shared meta model and encourages the student module to mimic the behaviour of the teacher module. We evaluate the effectiveness of m2mKD on two distinct modular neural architectures: Neural Attentive Circuits (NACs) and Vision Mixture-of-Experts (V-MoE). By applying m2mKD to NACs, we achieve significant improvements in IID accuracy on Tiny-ImageNet (up to 5.6%) and OOD robustness on Tiny-ImageNet-R (up to 4.2%). On average, we observe a 1% gain in both ImageNet and ImageNet-R. The V-MoE-Base model trained using m2mKD also achieves 3.5% higher accuracy than end-to-end training on ImageNet. The experimental results demonstrate that our method offers a promising solution for connecting modular networks with pretrained monolithic models. Code is available at https://github.com/kamanphoebe/m2mKD.
Forecasting Auxiliary Energy Consumption for Electric Heavy-Duty Vehicles
Nov 27, 2023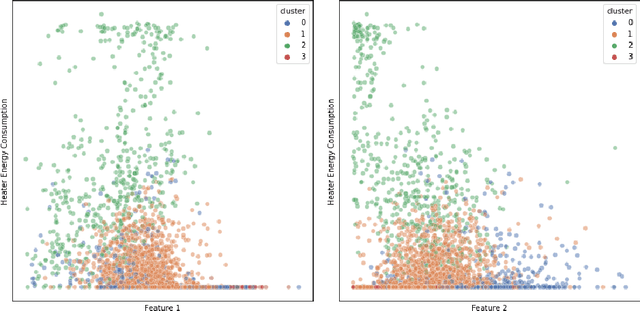
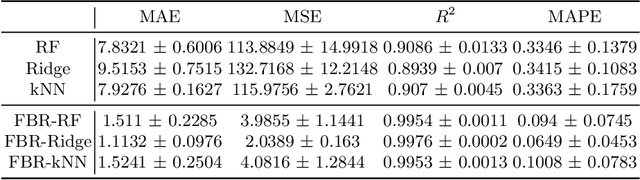
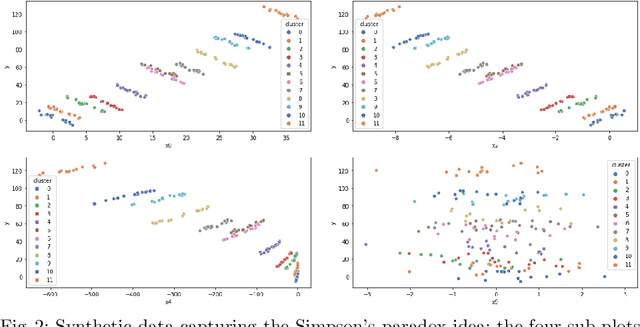
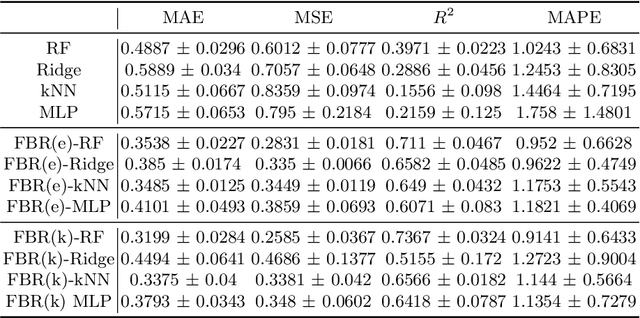
Accurate energy consumption prediction is crucial for optimizing the operation of electric commercial heavy-duty vehicles, e.g., route planning for charging. Moreover, understanding why certain predictions are cast is paramount for such a predictive model to gain user trust and be deployed in practice. Since commercial vehicles operate differently as transportation tasks, ambient, and drivers vary, a heterogeneous population is expected when building an AI system for forecasting energy consumption. The dependencies between the input features and the target values are expected to also differ across sub-populations. One well-known example of such a statistical phenomenon is the Simpson paradox. In this paper, we illustrate that such a setting poses a challenge for existing XAI methods that produce global feature statistics, e.g. LIME or SHAP, causing them to yield misleading results. We demonstrate a potential solution by training multiple regression models on subsets of data. It not only leads to superior regression performance but also more relevant and consistent LIME explanations. Given that the employed groupings correspond to relevant sub-populations, the associations between the input features and the target values are consistent within each cluster but different across clusters. Experiments on both synthetic and real-world datasets show that such splitting of a complex problem into simpler ones yields better regression performance and interpretability.
Explainable Predictive Maintenance
Jun 08, 2023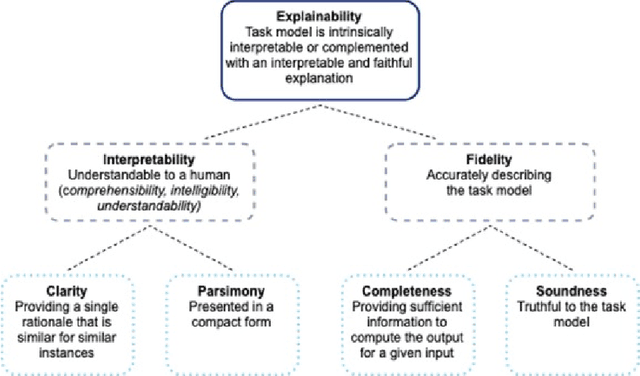

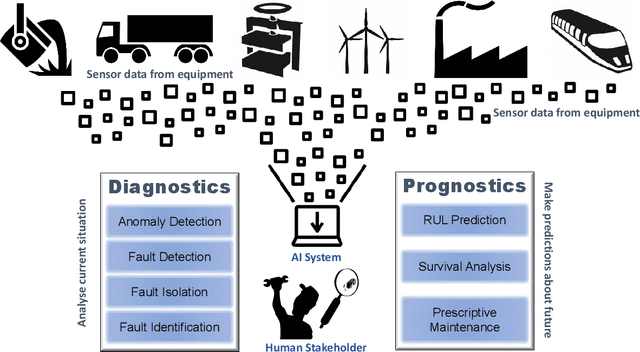
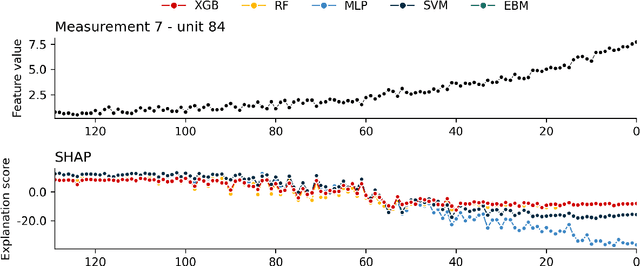
Explainable Artificial Intelligence (XAI) fills the role of a critical interface fostering interactions between sophisticated intelligent systems and diverse individuals, including data scientists, domain experts, end-users, and more. It aids in deciphering the intricate internal mechanisms of ``black box'' Machine Learning (ML), rendering the reasons behind their decisions more understandable. However, current research in XAI primarily focuses on two aspects; ways to facilitate user trust, or to debug and refine the ML model. The majority of it falls short of recognising the diverse types of explanations needed in broader contexts, as different users and varied application areas necessitate solutions tailored to their specific needs. One such domain is Predictive Maintenance (PdM), an exploding area of research under the Industry 4.0 \& 5.0 umbrella. This position paper highlights the gap between existing XAI methodologies and the specific requirements for explanations within industrial applications, particularly the Predictive Maintenance field. Despite explainability's crucial role, this subject remains a relatively under-explored area, making this paper a pioneering attempt to bring relevant challenges to the research community's attention. We provide an overview of predictive maintenance tasks and accentuate the need and varying purposes for corresponding explanations. We then list and describe XAI techniques commonly employed in the literature, discussing their suitability for PdM tasks. Finally, to make the ideas and claims more concrete, we demonstrate XAI applied in four specific industrial use cases: commercial vehicles, metro trains, steel plants, and wind farms, spotlighting areas requiring further research.
Transfer learning for Remaining Useful Life Prediction Based on Consensus Self-Organizing Models
Sep 30, 2019
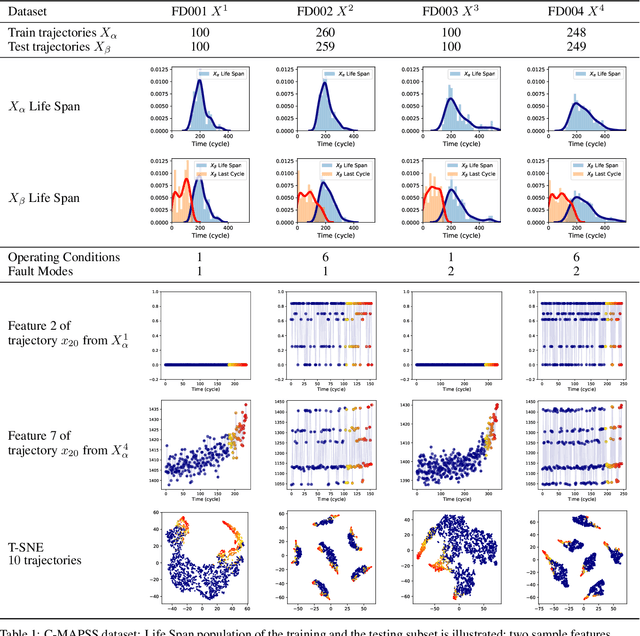
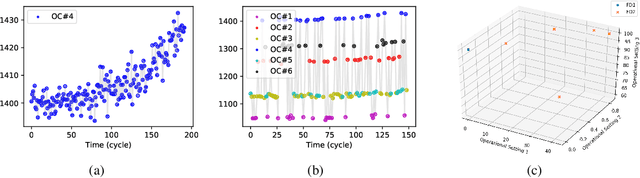

The traditional paradigm for developing machine prognostics usually relies on generalization from data acquired in experiments under controlled conditions prior to deployment of the equipment. Detecting or predicting failures and estimating machine health in this way assumes that future field data will have a very similar distribution to the experiment data. However, many complex machines operate under dynamic environmental conditions and are used in many different ways. This makes collecting comprehensive data very challenging, and the assumption that pre-deployment data and post-deployment data follow very similar distributions is unlikely to hold. Transfer Learning (TL) refers to methods for transferring knowledge learned in one setting (the source domain) to another setting (the target domain). In this work, we present a TL method for predicting Remaining Useful Life (RUL) of equipment, under the assumption that labels are available only for the source domain and not the target domain. This setting corresponds to generalizing from a limited number of run-to-failure experiments performed prior to deployment into making prognostics with data coming from deployed equipment that is being used under multiple new operating conditions and experiencing previously unseen faults. We employ a deviation detection method, Consensus Self-Organizing Models (COSMO), to create transferable features for building the RUL regression model. These features capture how different target equipment is in comparison to its peers. The efficiency of the proposed TL method is demonstrated using the NASA Turbofan Engine Degradation Simulation Data Set. Models using the COSMO transferable features show better performance than other methods on predicting RUL when the target domain is more complex than the source domain.
Exploring home robot capabilities by medium fidelity prototyping
Oct 09, 2017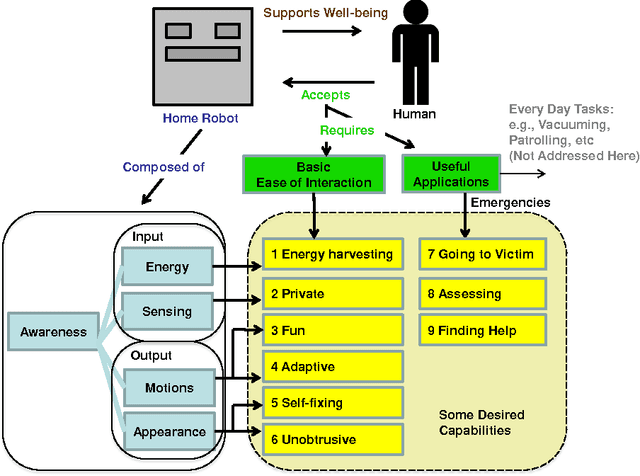
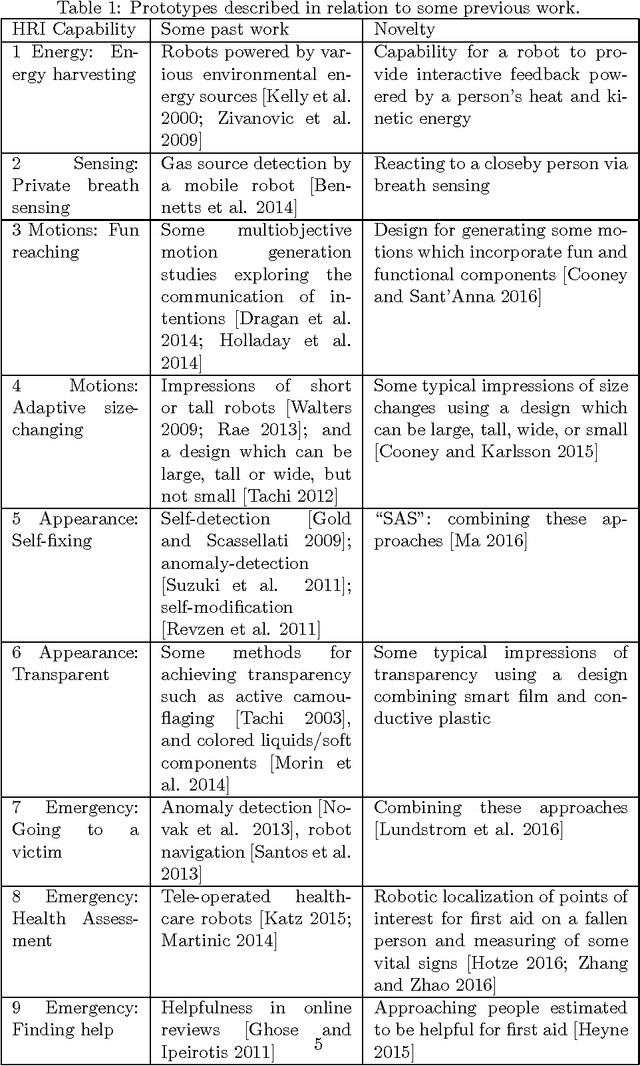
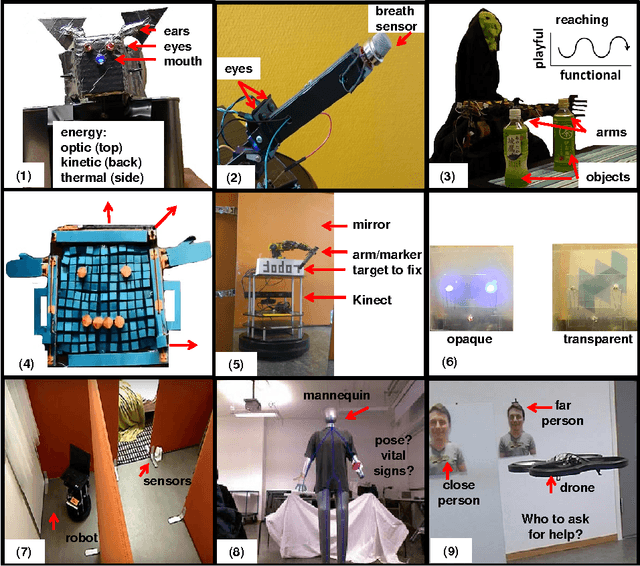

In order for autonomous robots to be able to support people's well-being in homes and everyday environments, new interactive capabilities will be required, as exemplified by the soft design used for Disney's recent robot character Baymax in popular fiction. Home robots will be required to be easy to interact with and intelligent--adaptive, fun, unobtrusive and involving little effort to power and maintain--and capable of carrying out useful tasks both on an everyday level and during emergencies. The current article adopts an exploratory medium fidelity prototyping approach for testing some new robotic capabilities in regard to recognizing people's activities and intentions and behaving in a way which is transparent to people. Results are discussed with the aim of informing next designs.