 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStep 3.5 Flash: Open Frontier-Level Intelligence with 11B Active Parameters
Feb 11, 2026We introduce Step 3.5 Flash, a sparse Mixture-of-Experts (MoE) model that bridges frontier-level agentic intelligence and computational efficiency. We focus on what matters most when building agents: sharp reasoning and fast, reliable execution. Step 3.5 Flash pairs a 196B-parameter foundation with 11B active parameters for efficient inference. It is optimized with interleaved 3:1 sliding-window/full attention and Multi-Token Prediction (MTP-3) to reduce the latency and cost of multi-round agentic interactions. To reach frontier-level intelligence, we design a scalable reinforcement learning framework that combines verifiable signals with preference feedback, while remaining stable under large-scale off-policy training, enabling consistent self-improvement across mathematics, code, and tool use. Step 3.5 Flash demonstrates strong performance across agent, coding, and math tasks, achieving 85.4% on IMO-AnswerBench, 86.4% on LiveCodeBench-v6 (2024.08-2025.05), 88.2% on tau2-Bench, 69.0% on BrowseComp (with context management), and 51.0% on Terminal-Bench 2.0, comparable to frontier models such as GPT-5.2 xHigh and Gemini 3.0 Pro. By redefining the efficiency frontier, Step 3.5 Flash provides a high-density foundation for deploying sophisticated agents in real-world industrial environments.
Can Mixture-of-Experts Surpass Dense LLMs Under Strictly Equal Resources?
Jun 13, 2025Mixture-of-Experts (MoE) language models dramatically expand model capacity and achieve remarkable performance without increasing per-token compute. However, can MoEs surpass dense architectures under strictly equal resource constraints - that is, when the total parameter count, training compute, and data budget are identical? This question remains under-explored despite its significant practical value and potential. In this paper, we propose a novel perspective and methodological framework to study this question thoroughly. First, we comprehensively investigate the architecture of MoEs and achieve an optimal model design that maximizes the performance. Based on this, we subsequently find that an MoE model with activation rate in an optimal region is able to outperform its dense counterpart under the same total parameter, training compute and data resource. More importantly, this optimal region remains consistent across different model sizes. Although additional amount of data turns out to be a trade-off for the enhanced performance, we show that this can be resolved via reusing data. We validate our findings through extensive experiments, training nearly 200 language models at 2B scale and over 50 at 7B scale, cumulatively processing 50 trillion tokens. All models will be released publicly.
A Closer Look into Mixture-of-Experts in Large Language Models
Jun 26, 2024
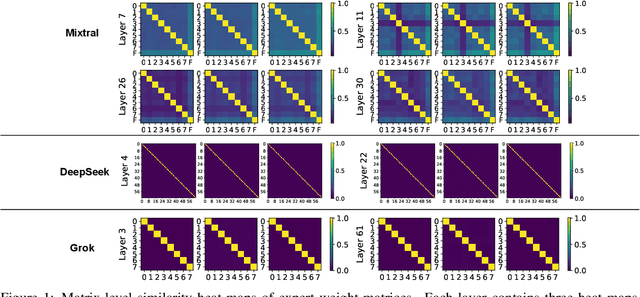

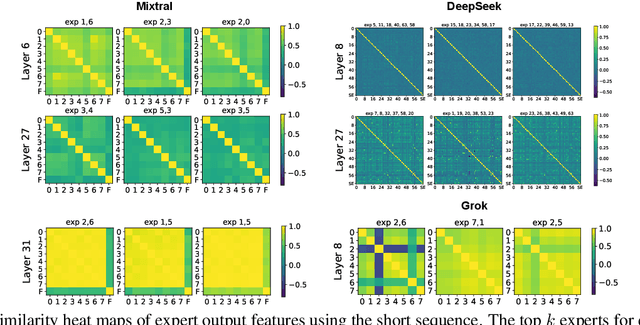
Mixture-of-experts (MoE) is gaining increasing attention due to its unique properties and remarkable performance, especially for language tasks. By sparsely activating a subset of parameters for each token, MoE architecture could increase the model size without sacrificing computational efficiency, achieving a better trade-off between performance and training costs. However, the underlying mechanism of MoE still lacks further exploration, and its modularization degree remains questionable. In this paper, we make an initial attempt to understand the inner workings of MoE-based large language models. Concretely, we comprehensively study the parametric and behavioral features of three recent MoE-based models and reveal some intriguing observations, including (1) Neurons act like fine-grained experts. (2) The router of MoE usually selects experts with larger output norms. (3) The expert diversity increases as the layer increases, while the last layer is an outlier. Based on the observations, we also provide suggestions for a broad spectrum of MoE practitioners, such as router design and expert allocation. We hope this work could shed light on future research on the MoE framework and other modular architectures. Code is available at https://github.com/kamanphoebe/Look-into-MoEs.
MuPT: A Generative Symbolic Music Pretrained Transformer
Apr 10, 2024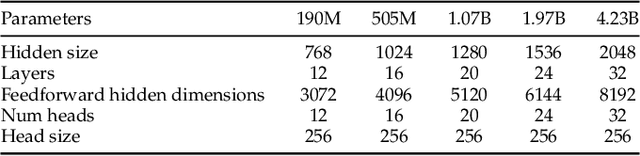

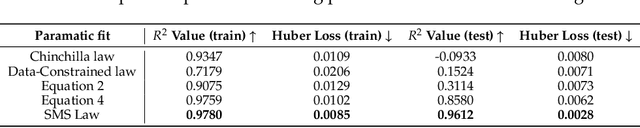
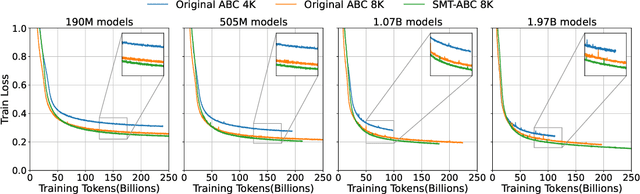
In this paper, we explore the application of Large Language Models (LLMs) to the pre-training of music. While the prevalent use of MIDI in music modeling is well-established, our findings suggest that LLMs are inherently more compatible with ABC Notation, which aligns more closely with their design and strengths, thereby enhancing the model's performance in musical composition. To address the challenges associated with misaligned measures from different tracks during generation, we propose the development of a Synchronized Multi-Track ABC Notation (SMT-ABC Notation), which aims to preserve coherence across multiple musical tracks. Our contributions include a series of models capable of handling up to 8192 tokens, covering 90% of the symbolic music data in our training set. Furthermore, we explore the implications of the Symbolic Music Scaling Law (SMS Law) on model performance. The results indicate a promising direction for future research in music generation, offering extensive resources for community-led research through our open-source contributions.
m2mKD: Module-to-Module Knowledge Distillation for Modular Transformers
Feb 26, 2024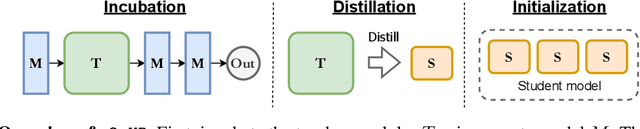
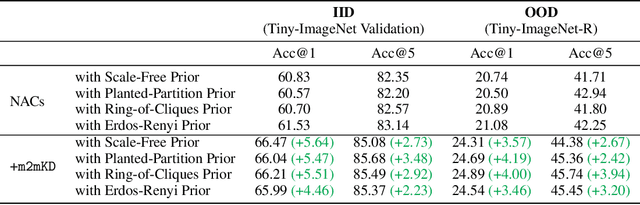
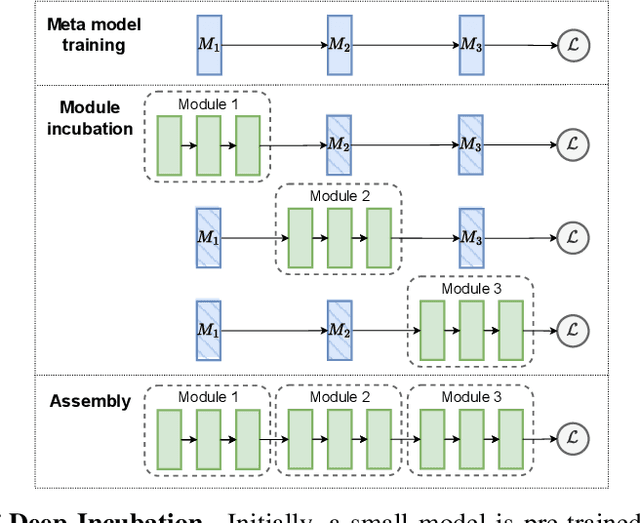
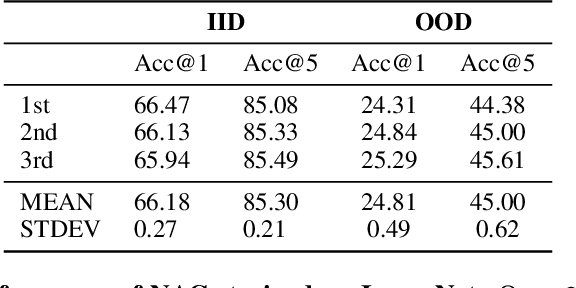
Modular neural architectures are gaining increasing attention due to their powerful capability for generalization and sample-efficient adaptation to new domains. However, training modular models, particularly in the early stages, poses challenges due to the optimization difficulties arising from their intrinsic sparse connectivity. Leveraging the knowledge from monolithic models, using techniques such as knowledge distillation, is likely to facilitate the training of modular models and enable them to integrate knowledge from multiple models pretrained on diverse sources. Nevertheless, conventional knowledge distillation approaches are not tailored to modular models and can fail when directly applied due to the unique architectures and the enormous number of parameters involved. Motivated by these challenges, we propose a general module-to-module knowledge distillation (m2mKD) method for transferring knowledge between modules. Our approach involves teacher modules split from a pretrained monolithic model, and student modules of a modular model. m2mKD separately combines these modules with a shared meta model and encourages the student module to mimic the behaviour of the teacher module. We evaluate the effectiveness of m2mKD on two distinct modular neural architectures: Neural Attentive Circuits (NACs) and Vision Mixture-of-Experts (V-MoE). By applying m2mKD to NACs, we achieve significant improvements in IID accuracy on Tiny-ImageNet (up to 5.6%) and OOD robustness on Tiny-ImageNet-R (up to 4.2%). On average, we observe a 1% gain in both ImageNet and ImageNet-R. The V-MoE-Base model trained using m2mKD also achieves 3.5% higher accuracy than end-to-end training on ImageNet. The experimental results demonstrate that our method offers a promising solution for connecting modular networks with pretrained monolithic models. Code is available at https://github.com/kamanphoebe/m2mKD.
Optical Flow Based Motion Detection for Autonomous Driving
Mar 03, 2022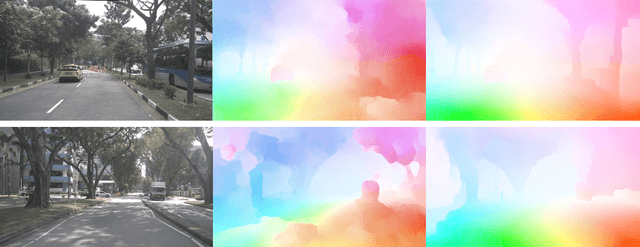


Motion detection is a fundamental but challenging task for autonomous driving. In particular scenes like highway, remote objects have to be paid extra attention for better controlling decision. Aiming at distant vehicles, we train a neural network model to classify the motion status using optical flow field information as the input. The experiments result in high accuracy, showing that our idea is viable and promising. The trained model also achieves an acceptable performance for nearby vehicles. Our work is implemented in PyTorch. Open tools including nuScenes, FastFlowNet and RAFT are used. Visualization videos are available at https://www.youtube.com/playlist?list=PLVVrWgq4OrlBnRebmkGZO1iDHEksMHKGk .