 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified View of Attention and Residual Sinks: Outlier-Driven Rescaling is Essential for Transformer Training
Jan 30, 2026We investigate the functional role of emergent outliers in large language models, specifically attention sinks (a few tokens that consistently receive large attention logits) and residual sinks (a few fixed dimensions with persistently large activations across most tokens). We hypothesize that these outliers, in conjunction with the corresponding normalizations (\textit{e.g.}, softmax attention and RMSNorm), effectively rescale other non-outlier components. We term this phenomenon \textit{outlier-driven rescaling} and validate this hypothesis across different model architectures and training token counts. This view unifies the origin and mitigation of both sink types. Our main conclusions and observations include: (1) Outliers function jointly with normalization: removing normalization eliminates the corresponding outliers but degrades training stability and performance; directly clipping outliers while retaining normalization leads to degradation, indicating that outlier-driven rescaling contributes to training stability. (2) Outliers serve more as rescale factors rather than contributors, as the final contributions of attention and residual sinks are significantly smaller than those of non-outliers. (3) Outliers can be absorbed into learnable parameters or mitigated via explicit gated rescaling, leading to improved training performance (average gain of 2 points) and enhanced quantization robustness (1.2 points degradation under W4A4 quantization).
Improving Low-Latency Learning Performance in Spiking Neural Networks via a Change-Perceptive Dendrite-Soma-Axon Neuron
Dec 18, 2025Spiking neurons, the fundamental information processing units of Spiking Neural Networks (SNNs), have the all-or-zero information output form that allows SNNs to be more energy-efficient compared to Artificial Neural Networks (ANNs). However, the hard reset mechanism employed in spiking neurons leads to information degradation due to its uniform handling of diverse membrane potentials. Furthermore, the utilization of overly simplified neuron models that disregard the intricate biological structures inherently impedes the network's capacity to accurately simulate the actual potential transmission process. To address these issues, we propose a dendrite-soma-axon (DSA) neuron employing the soft reset strategy, in conjunction with a potential change-based perception mechanism, culminating in the change-perceptive dendrite-soma-axon (CP-DSA) neuron. Our model contains multiple learnable parameters that expand the representation space of neurons. The change-perceptive (CP) mechanism enables our model to achieve competitive performance in short time steps utilizing the difference information of adjacent time steps. Rigorous theoretical analysis is provided to demonstrate the efficacy of the CP-DSA model and the functional characteristics of its internal parameters. Furthermore, extensive experiments conducted on various datasets substantiate the significant advantages of the CP-DSA model over state-of-the-art approaches.
MVISU-Bench: Benchmarking Mobile Agents for Real-World Tasks by Multi-App, Vague, Interactive, Single-App and Unethical Instructions
Aug 12, 2025Given the significant advances in Large Vision Language Models (LVLMs) in reasoning and visual understanding, mobile agents are rapidly emerging to meet users' automation needs. However, existing evaluation benchmarks are disconnected from the real world and fail to adequately address the diverse and complex requirements of users. From our extensive collection of user questionnaire, we identified five tasks: Multi-App, Vague, Interactive, Single-App, and Unethical Instructions. Around these tasks, we present \textbf{MVISU-Bench}, a bilingual benchmark that includes 404 tasks across 137 mobile applications. Furthermore, we propose Aider, a plug-and-play module that acts as a dynamic prompt prompter to mitigate risks and clarify user intent for mobile agents. Our Aider is easy to integrate into several frameworks and has successfully improved overall success rates by 19.55\% compared to the current state-of-the-art (SOTA) on MVISU-Bench. Specifically, it achieves success rate improvements of 53.52\% and 29.41\% for unethical and interactive instructions, respectively. Through extensive experiments and analysis, we highlight the gap between existing mobile agents and real-world user expectations.
AR-LIF: Adaptive reset leaky-integrate and fire neuron for spiking neural networks
Jul 28, 2025Spiking neural networks possess the advantage of low energy consumption due to their event-driven nature. Compared with binary spike outputs, their inherent floating-point dynamics are more worthy of attention. The threshold level and reset mode of neurons play a crucial role in determining the number and timing of spikes. The existing hard reset method causes information loss, while the improved soft reset method adopts a uniform treatment for neurons. In response to this, this paper designs an adaptive reset neuron, establishing the correlation between input, output and reset, and integrating a simple yet effective threshold adjustment strategy. It achieves excellent performance on various datasets while maintaining the advantage of low energy consumption.
Blending Supervised and Reinforcement Fine-Tuning with Prefix Sampling
Jul 02, 2025Existing post-training techniques for large language models are broadly categorized into Supervised Fine-Tuning (SFT) and Reinforcement Fine-Tuning (RFT). Each paradigm presents a distinct trade-off: SFT excels at mimicking demonstration data but can lead to problematic generalization as a form of behavior cloning. Conversely, RFT can significantly enhance a model's performance but is prone to learn unexpected behaviors, and its performance is highly sensitive to the initial policy. In this paper, we propose a unified view of these methods and introduce Prefix-RFT, a hybrid approach that synergizes learning from both demonstration and exploration. Using mathematical reasoning problems as a testbed, we empirically demonstrate that Prefix-RFT is both simple and effective. It not only surpasses the performance of standalone SFT and RFT but also outperforms parallel mixed-policy RFT methods. A key advantage is its seamless integration into existing open-source frameworks, requiring only minimal modifications to the standard RFT pipeline. Our analysis highlights the complementary nature of SFT and RFT, and validates that Prefix-RFT effectively harmonizes these two learning paradigms. Furthermore, ablation studies confirm the method's robustness to variations in the quality and quantity of demonstration data. We hope this work offers a new perspective on LLM post-training, suggesting that a unified paradigm that judiciously integrates demonstration and exploration could be a promising direction for future research.
Identification of RIS-Assisted Paths for Wireless Integrated Sensing and Communication
Jun 04, 2025Distinguishing between reconfigurable intelligent surface (RIS) assisted paths and non-line-of-sight (NLOS) paths is a fundamental problem for RIS-assisted integrated sensing and communication. In this work, we propose a pattern alternation scheme for the RIS response that uses part of the RIS as a dynamic part to modulate the estimated channel power, which can considerably help the user equipments (UEs) to identify the RIS-assisted paths. Under such a dynamic setup, we formulate the detection framework for a single UE, where we develop a statistical model of the estimated channel power, allowing us to analytically evaluate the performance of the system. We investigate our method under two critical factors: the number of RIS elements allocated for the dynamic part and the allocation of RIS elements among different users. Simulation results verify the accuracy of our analysis.
Gated Attention for Large Language Models: Non-linearity, Sparsity, and Attention-Sink-Free
May 10, 2025Gating mechanisms have been widely utilized, from early models like LSTMs and Highway Networks to recent state space models, linear attention, and also softmax attention. Yet, existing literature rarely examines the specific effects of gating. In this work, we conduct comprehensive experiments to systematically investigate gating-augmented softmax attention variants. Specifically, we perform a comprehensive comparison over 30 variants of 15B Mixture-of-Experts (MoE) models and 1.7B dense models trained on a 3.5 trillion token dataset. Our central finding is that a simple modification-applying a head-specific sigmoid gate after the Scaled Dot-Product Attention (SDPA)-consistently improves performance. This modification also enhances training stability, tolerates larger learning rates, and improves scaling properties. By comparing various gating positions and computational variants, we attribute this effectiveness to two key factors: (1) introducing non-linearity upon the low-rank mapping in the softmax attention, and (2) applying query-dependent sparse gating scores to modulate the SDPA output. Notably, we find this sparse gating mechanism mitigates 'attention sink' and enhances long-context extrapolation performance, and we also release related $\href{https://github.com/qiuzh20/gated_attention}{codes}$ and $\href{https://huggingface.co/QwQZh/gated_attention}{models}$ to facilitate future research.
Demons in the Detail: On Implementing Load Balancing Loss for Training Specialized Mixture-of-Expert Models
Jan 21, 2025
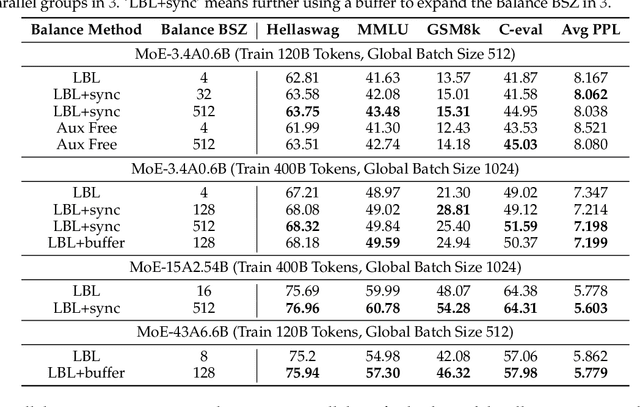
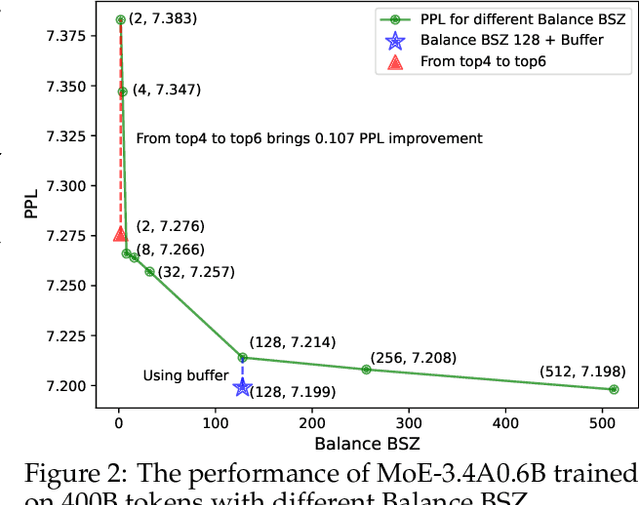
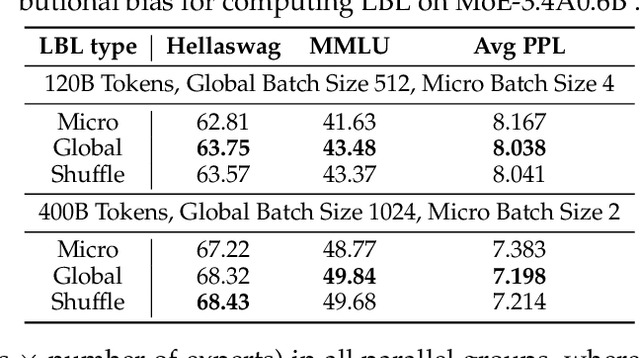
This paper revisits the implementation of $\textbf{L}$oad-$\textbf{b}$alancing $\textbf{L}$oss (LBL) when training Mixture-of-Experts (MoEs) models. Specifically, LBL for MoEs is defined as $N_E \sum_{i=1}^{N_E} f_i p_i$, where $N_E$ is the total number of experts, $f_i$ represents the frequency of expert $i$ being selected, and $p_i$ denotes the average gating score of the expert $i$. Existing MoE training frameworks usually employ the parallel training strategy so that $f_i$ and the LBL are calculated within a $\textbf{micro-batch}$ and then averaged across parallel groups. In essence, a micro-batch for training billion-scale LLMs normally contains very few sequences. So, the micro-batch LBL is almost at the sequence level, and the router is pushed to distribute the token evenly within each sequence. Under this strict constraint, even tokens from a domain-specific sequence ($\textit{e.g.}$, code) are uniformly routed to all experts, thereby inhibiting expert specialization. In this work, we propose calculating LBL using a $\textbf{global-batch}$ to loose this constraint. Because a global-batch contains much more diverse sequences than a micro-batch, which will encourage load balance at the corpus level. Specifically, we introduce an extra communication step to synchronize $f_i$ across micro-batches and then use it to calculate the LBL. Through experiments on training MoEs-based LLMs (up to $\textbf{42.8B}$ total parameters and $\textbf{400B}$ tokens), we surprisingly find that the global-batch LBL strategy yields excellent performance gains in both pre-training perplexity and downstream tasks. Our analysis reveals that the global-batch LBL also greatly improves the domain specialization of MoE experts.
Hybrid Channel Modeling and Environment Reconstruction for Terahertz Monostatic Sensing
Nov 12, 2024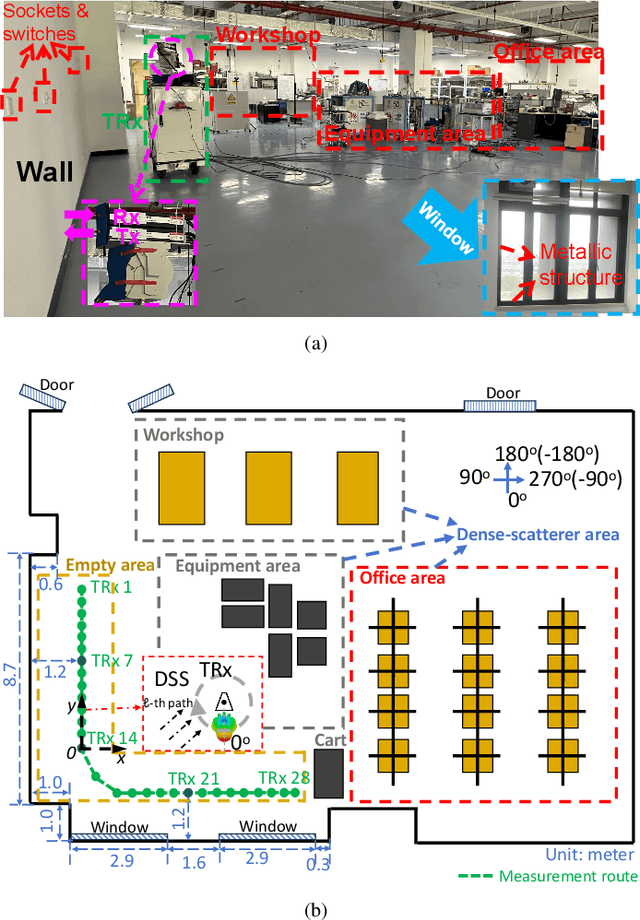
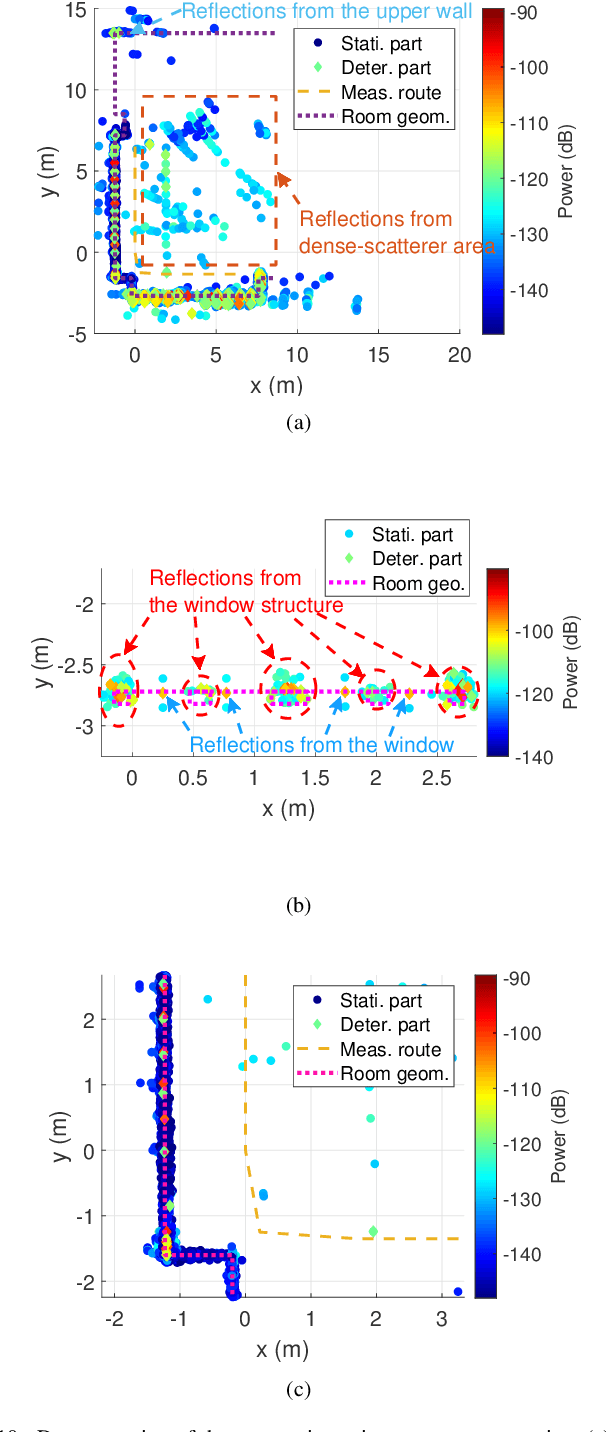

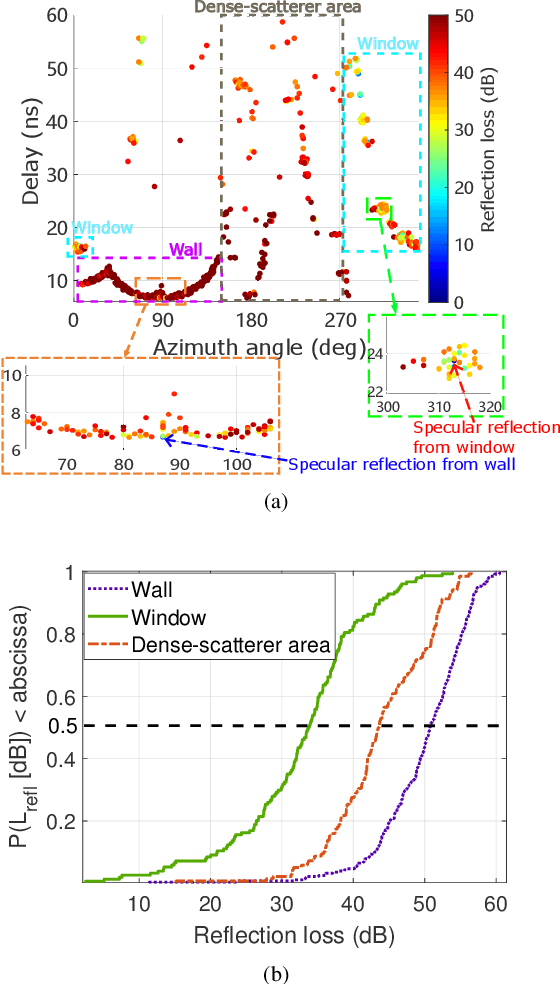
THz ISAC aims to integrate novel functionalities, such as positioning and environmental sensing, into communication systems. Accurate channel modeling is crucial for the design and performance evaluation of future ISAC systems. In this paper, a THz measurement campaign for monostatic sensing is presented. VNA-based channel measurements are conducted in a laboratory scenario, where the transmitter and receiver are positioned together to mimic monostatic sensing. The centering frequency and measured bandwidth for these measurements are 300 GHz and 20 GHz, respectively. A DSS scheme is employed to capture spatial sensing channel profiles. Measurements are conducted across 28 transceiver locations arranged along an 'L'-shaped route. Then, an element-wise SAGE algorithm is used to estimate the MPC parameters, i.e., amplitude and delay. Specular and diffuse reflections are analyzed based on geometric principles and the estimated MPC parameters, where the effects from the radiation pattern are observed. A geometry-based MPC trajectory tracking algorithm is then proposed to classify the MPCs and de-embed the effects of the radiation pattern. Following this algorithm, a hybrid channel model is proposed based on the de-embedded MPC parameters. In this hybrid channel model for monostatic sensing, the MPCs are categorized into target-related and environment-related components. The target-related components are utilized for target detection and identification, while the environment-related ones focus on geometrical scenario reconstruction. A demonstration of geometrical environment reconstruction, along with an analysis of reflection loss for target identification, is subsequently presented. This work offers valuable insights into THz monostatic sensing channel modeling and the design of future THz ISAC systems.
Post-hoc Reward Calibration: A Case Study on Length Bias
Sep 25, 2024



Reinforcement Learning from Human Feedback aligns the outputs of Large Language Models with human values and preferences. Central to this process is the reward model (RM), which translates human feedback into training signals for optimising LLM behaviour. However, RMs can develop biases by exploiting spurious correlations in their training data, such as favouring outputs based on length or style rather than true quality. These biases can lead to incorrect output rankings, sub-optimal model evaluations, and the amplification of undesirable behaviours in LLMs alignment. This paper addresses the challenge of correcting such biases without additional data and training, introducing the concept of Post-hoc Reward Calibration. We first propose an intuitive approach to estimate the bias term and, thus, remove it to approximate the underlying true reward. We then extend the approach to a more general and robust form with the Locally Weighted Regression. Focusing on the prevalent length bias, we validate our proposed approaches across three experimental settings, demonstrating consistent improvements: (1) a 3.11 average performance gain across 33 reward models on the RewardBench dataset; (2) enhanced alignment of RM rankings with GPT-4 evaluations and human preferences based on the AlpacaEval benchmark; and (3) improved Length-Controlled win rate of the RLHF process in multiple LLM--RM combinations. Our method is computationally efficient and generalisable to other types of bias and RMs, offering a scalable and robust solution for mitigating biases in LLM alignment. Our code and results are available at https://github.com/ZeroYuHuang/Reward-Calibration.