 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscRec: Disentangled Semantic-Collaborative Modeling for Generative Recommendation
Jun 18, 2025Generative recommendation is emerging as a powerful paradigm that directly generates item predictions, moving beyond traditional matching-based approaches. However, current methods face two key challenges: token-item misalignment, where uniform token-level modeling ignores item-level granularity that is critical for collaborative signal learning, and semantic-collaborative signal entanglement, where collaborative and semantic signals exhibit distinct distributions yet are fused in a unified embedding space, leading to conflicting optimization objectives that limit the recommendation performance. To address these issues, we propose DiscRec, a novel framework that enables Disentangled Semantic-Collaborative signal modeling with flexible fusion for generative Recommendation.First, DiscRec introduces item-level position embeddings, assigned based on indices within each semantic ID, enabling explicit modeling of item structure in input token sequences.Second, DiscRec employs a dual-branch module to disentangle the two signals at the embedding layer: a semantic branch encodes semantic signals using original token embeddings, while a collaborative branch applies localized attention restricted to tokens within the same item to effectively capture collaborative signals. A gating mechanism subsequently fuses both branches while preserving the model's ability to model sequential dependencies. Extensive experiments on four real-world datasets demonstrate that DiscRec effectively decouples these signals and consistently outperforms state-of-the-art baselines. Our codes are available on https://github.com/Ten-Mao/DiscRec.
Selecting Demonstrations for Many-Shot In-Context Learning via Gradient Matching
Jun 05, 2025



In-Context Learning (ICL) empowers Large Language Models (LLMs) for rapid task adaptation without Fine-Tuning (FT), but its reliance on demonstration selection remains a critical challenge. While many-shot ICL shows promising performance through scaled demonstrations, the selection method for many-shot demonstrations remains limited to random selection in existing work. Since the conventional instance-level retrieval is not suitable for many-shot scenarios, we hypothesize that the data requirements for in-context learning and fine-tuning are analogous. To this end, we introduce a novel gradient matching approach that selects demonstrations by aligning fine-tuning gradients between the entire training set of the target task and the selected examples, so as to approach the learning effect on the entire training set within the selected examples. Through gradient matching on relatively small models, e.g., Qwen2.5-3B or Llama3-8B, our method consistently outperforms random selection on larger LLMs from 4-shot to 128-shot scenarios across 9 diverse datasets. For instance, it surpasses random selection by 4% on Qwen2.5-72B and Llama3-70B, and by around 2% on 5 closed-source LLMs. This work unlocks more reliable and effective many-shot ICL, paving the way for its broader application.
Enhancing LLMs via High-Knowledge Data Selection
May 20, 2025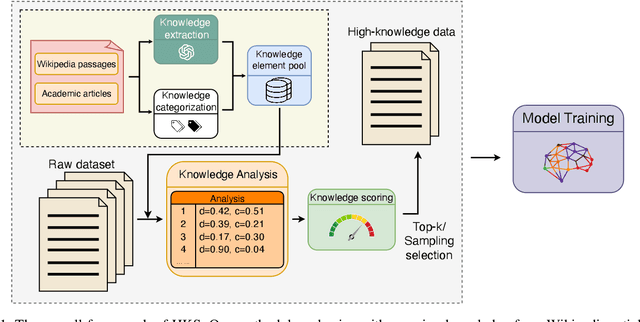
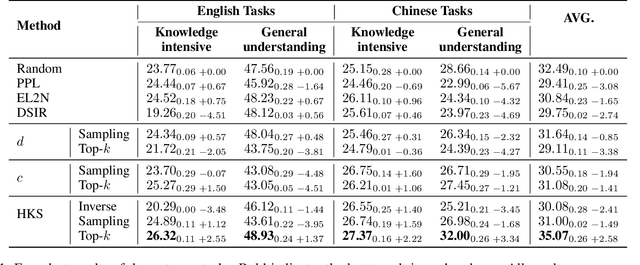
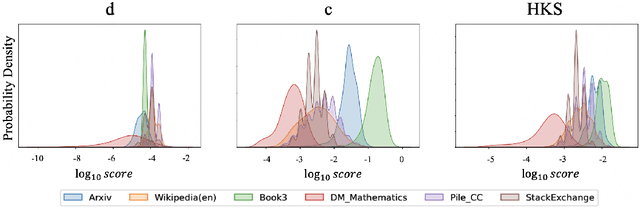
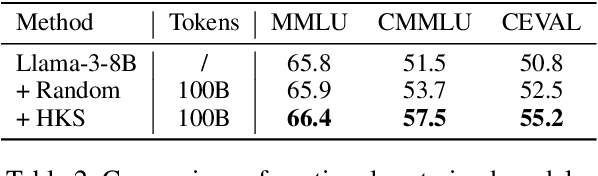
The performance of Large Language Models (LLMs) is intrinsically linked to the quality of its training data. Although several studies have proposed methods for high-quality data selection, they do not consider the importance of knowledge richness in text corpora. In this paper, we propose a novel and gradient-free High-Knowledge Scorer (HKS) to select high-quality data from the dimension of knowledge, to alleviate the problem of knowledge scarcity in the pre-trained corpus. We propose a comprehensive multi-domain knowledge element pool and introduce knowledge density and coverage as metrics to assess the knowledge content of the text. Based on this, we propose a comprehensive knowledge scorer to select data with intensive knowledge, which can also be utilized for domain-specific high-knowledge data selection by restricting knowledge elements to the specific domain. We train models on a high-knowledge bilingual dataset, and experimental results demonstrate that our scorer improves the model's performance in knowledge-intensive and general comprehension tasks, and is effective in enhancing both the generic and domain-specific capabilities of the model.
Beyond One-Size-Fits-All: Inversion Learning for Highly Effective NLG Evaluation Prompts
Apr 29, 2025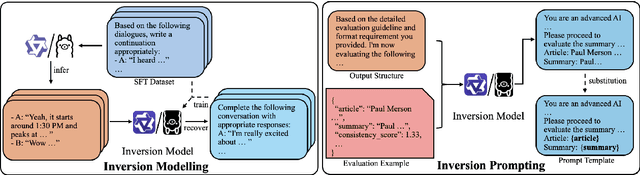
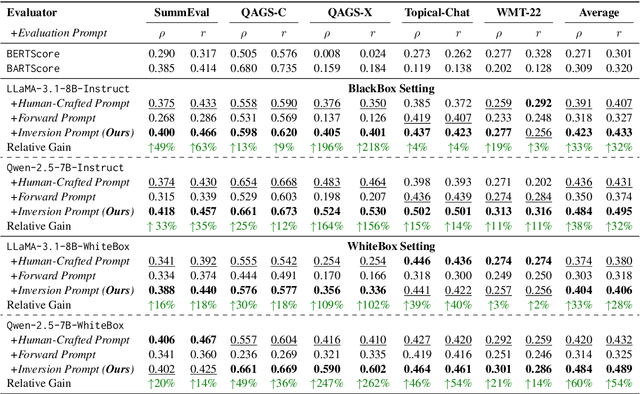

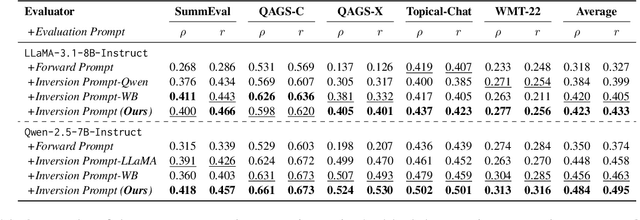
Evaluating natural language generation (NLG) systems is challenging due to the diversity of valid outputs. While human evaluation is the gold standard, it suffers from inconsistencies, lack of standardisation, and demographic biases, limiting reproducibility. LLM-based evaluation offers a scalable alternative but is highly sensitive to prompt design, where small variations can lead to significant discrepancies. In this work, we propose an inversion learning method that learns effective reverse mappings from model outputs back to their input instructions, enabling the automatic generation of highly effective, model-specific evaluation prompts. Our method requires only a single evaluation sample and eliminates the need for time-consuming manual prompt engineering, thereby improving both efficiency and robustness. Our work contributes toward a new direction for more robust and efficient LLM-based evaluation.
AAKT: Enhancing Knowledge Tracing with Alternate Autoregressive Modeling
Feb 17, 2025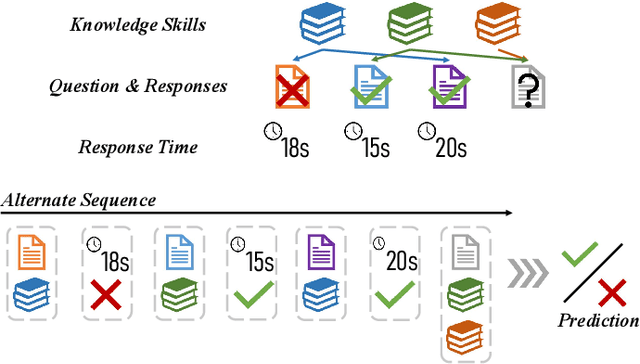
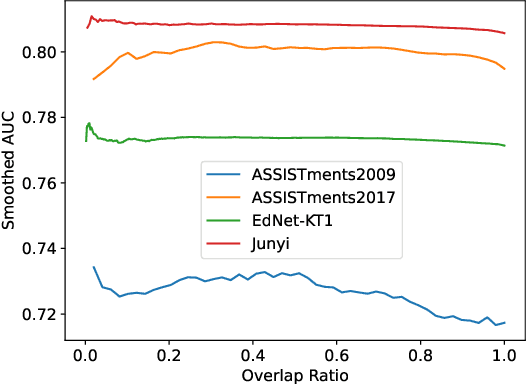
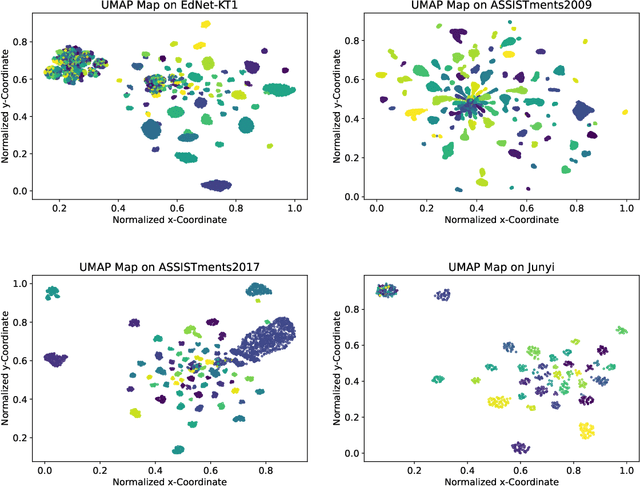
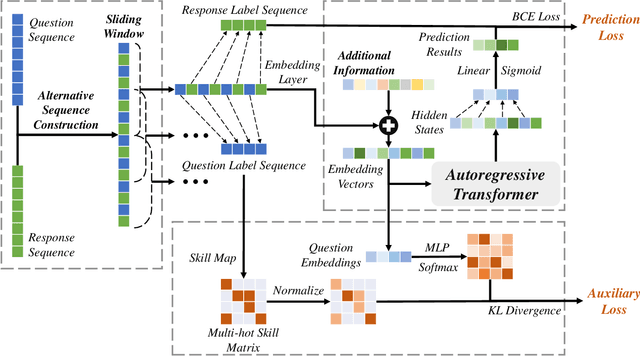
Knowledge Tracing (KT) aims to predict students' future performances based on their former exercises and additional information in educational settings. KT has received significant attention since it facilitates personalized experiences in educational situations. Simultaneously, the autoregressive modeling on the sequence of former exercises has been proven effective for this task. One of the primary challenges in autoregressive modeling for Knowledge Tracing is effectively representing the anterior (pre-response) and posterior (post-response) states of learners across exercises. Existing methods often employ complex model architectures to update learner states using question and response records. In this study, we propose a novel perspective on knowledge tracing task by treating it as a generative process, consistent with the principles of autoregressive models. We demonstrate that knowledge states can be directly represented through autoregressive encodings on a question-response alternate sequence, where model generate the most probable representation in hidden state space by analyzing history interactions. This approach underpins our framework, termed Alternate Autoregressive Knowledge Tracing (AAKT). Additionally, we incorporate supplementary educational information, such as question-related skills, into our framework through an auxiliary task, and include extra exercise details, like response time, as additional inputs. Our proposed framework is implemented using advanced autoregressive technologies from Natural Language Generation (NLG) for both training and prediction. Empirical evaluations on four real-world KT datasets indicate that AAKT consistently outperforms all baseline models in terms of AUC, ACC, and RMSE. Furthermore, extensive ablation studies and visualized analysis validate the effectiveness of key components in AAKT.
Disentangling Preference Representation and Text Generation for Efficient Individual Preference Alignment
Dec 30, 2024Aligning Large Language Models (LLMs) with general human preferences has been proved crucial in improving the interaction quality between LLMs and human. However, human values are inherently diverse among different individuals, making it insufficient to align LLMs solely with general preferences. To address this, personalizing LLMs according to individual feedback emerges as a promising solution. Nonetheless, this approach presents challenges in terms of the efficiency of alignment algorithms. In this work, we introduce a flexible paradigm for individual preference alignment. Our method fundamentally improves efficiency by disentangling preference representation from text generation in LLMs. We validate our approach across multiple text generation tasks and demonstrate that it can produce aligned quality as well as or better than PEFT-based methods, while reducing additional training time for each new individual preference by $80\%$ to $90\%$ in comparison with them.
HelloBench: Evaluating Long Text Generation Capabilities of Large Language Models
Sep 24, 2024



In recent years, Large Language Models (LLMs) have demonstrated remarkable capabilities in various tasks (e.g., long-context understanding), and many benchmarks have been proposed. However, we observe that long text generation capabilities are not well investigated. Therefore, we introduce the Hierarchical Long Text Generation Benchmark (HelloBench), a comprehensive, in-the-wild, and open-ended benchmark to evaluate LLMs' performance in generating long text. Based on Bloom's Taxonomy, HelloBench categorizes long text generation tasks into five subtasks: open-ended QA, summarization, chat, text completion, and heuristic text generation. Besides, we propose Hierarchical Long Text Evaluation (HelloEval), a human-aligned evaluation method that significantly reduces the time and effort required for human evaluation while maintaining a high correlation with human evaluation. We have conducted extensive experiments across around 30 mainstream LLMs and observed that the current LLMs lack long text generation capabilities. Specifically, first, regardless of whether the instructions include explicit or implicit length constraints, we observe that most LLMs cannot generate text that is longer than 4000 words. Second, we observe that while some LLMs can generate longer text, many issues exist (e.g., severe repetition and quality degradation). Third, to demonstrate the effectiveness of HelloEval, we compare HelloEval with traditional metrics (e.g., ROUGE, BLEU, etc.) and LLM-as-a-Judge methods, which show that HelloEval has the highest correlation with human evaluation. We release our code in https://github.com/Quehry/HelloBench.
Leveraging Estimated Transferability Over Human Intuition for Model Selection in Text Ranking
Sep 24, 2024


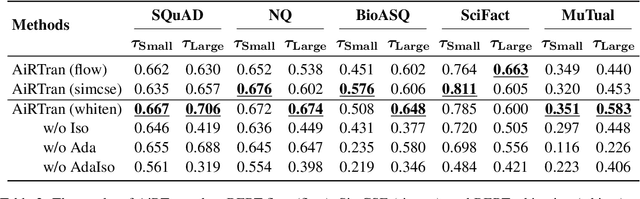
Text ranking has witnessed significant advancements, attributed to the utilization of dual-encoder enhanced by Pre-trained Language Models (PLMs). Given the proliferation of available PLMs, selecting the most effective one for a given dataset has become a non-trivial challenge. As a promising alternative to human intuition and brute-force fine-tuning, Transferability Estimation (TE) has emerged as an effective approach to model selection. However, current TE methods are primarily designed for classification tasks, and their estimated transferability may not align well with the objectives of text ranking. To address this challenge, we propose to compute the expected rank as transferability, explicitly reflecting the model's ranking capability. Furthermore, to mitigate anisotropy and incorporate training dynamics, we adaptively scale isotropic sentence embeddings to yield an accurate expected rank score. Our resulting method, Adaptive Ranking Transferability (AiRTran), can effectively capture subtle differences between models. On challenging model selection scenarios across various text ranking datasets, it demonstrates significant improvements over previous classification-oriented TE methods, human intuition, and ChatGPT with minor time consumption.
PFME: A Modular Approach for Fine-grained Hallucination Detection and Editing of Large Language Models
Jun 29, 2024



Large Language Models (LLMs) excel in fluency but risk producing inaccurate content, called "hallucinations." This paper outlines a standardized process for categorizing fine-grained hallucination types and proposes an innovative framework--the Progressive Fine-grained Model Editor (PFME)--specifically designed to detect and correct fine-grained hallucinations in LLMs. PFME consists of two collaborative modules: the Real-time Fact Retrieval Module and the Fine-grained Hallucination Detection and Editing Module. The former identifies key entities in the document and retrieves the latest factual evidence from credible sources. The latter further segments the document into sentence-level text and, based on relevant evidence and previously edited context, identifies, locates, and edits each sentence's hallucination type. Experimental results on FavaBench and FActScore demonstrate that PFME outperforms existing methods in fine-grained hallucination detection tasks. Particularly, when using the Llama3-8B-Instruct model, PFME's performance in fine-grained hallucination detection with external knowledge assistance improves by 8.7 percentage points (pp) compared to ChatGPT. In editing tasks, PFME further enhances the FActScore of FActScore-Alpaca13B and FActScore-ChatGPT datasets, increasing by 16.2pp and 4.6pp, respectively.
Enhancing 3D Lane Detection and Topology Reasoning with 2D Lane Priors
Jun 05, 2024



3D lane detection and topology reasoning are essential tasks in autonomous driving scenarios, requiring not only detecting the accurate 3D coordinates on lane lines, but also reasoning the relationship between lanes and traffic elements. Current vision-based methods, whether explicitly constructing BEV features or not, all establish the lane anchors/queries in 3D space while ignoring the 2D lane priors. In this study, we propose Topo2D, a novel framework based on Transformer, leveraging 2D lane instances to initialize 3D queries and 3D positional embeddings. Furthermore, we explicitly incorporate 2D lane features into the recognition of topology relationships among lane centerlines and between lane centerlines and traffic elements. Topo2D achieves 44.5% OLS on multi-view topology reasoning benchmark OpenLane-V2 and 62.6% F-Socre on single-view 3D lane detection benchmark OpenLane, exceeding the performance of existing state-of-the-art methods.