 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThink Dense, Not Long: Dynamic Decoupled Conditional Advantage for Efficient Reasoning
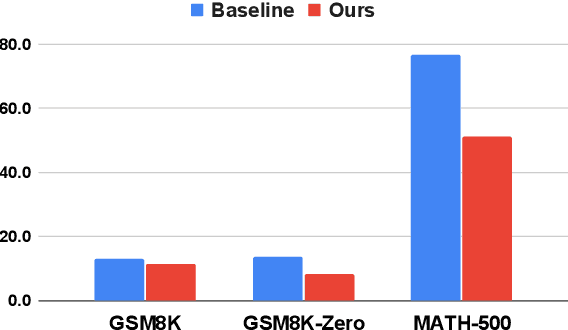
Feb 02, 2026Reinforcement Learning with Verifiable Rewards (RLVR) can elicit strong multi-step reasoning, yet it often encourages overly verbose traces. Moreover, naive length penalties in group-relative optimization can severely hurt accuracy. We attribute this failure to two structural issues: (i) Dilution of Length Baseline, where incorrect responses (with zero length reward) depress the group baseline and over-penalize correct solutions; and (ii) Difficulty-Penalty Mismatch, where a static penalty cannot adapt to problem difficulty, suppressing necessary reasoning on hard instances while leaving redundancy on easy ones. We propose Dynamic Decoupled Conditional Advantage (DDCA) to decouple efficiency optimization from correctness. DDCA computes length advantages conditionally within the correct-response cluster to eliminate baseline dilution, and dynamically scales the penalty strength using the group pass rate as a proxy for difficulty. Experiments on GSM8K, MATH500, AMC23, and AIME25 show that DDCA consistently improves the efficiency--accuracy trade-off relative to adaptive baselines, reducing generated tokens by approximately 60% on simpler tasks (e.g., GSM8K) versus over 20% on harder benchmarks (e.g., AIME25), thereby maintaining or improving accuracy. Code is available at https://github.com/alphadl/DDCA.
Revisiting Overthinking in Long Chain-of-Thought from the Perspective of Self-Doubt
May 29, 2025


Reasoning Large Language Models (RLLMs) have demonstrated impressive performance on complex tasks, largely due to the adoption of Long Chain-of-Thought (Long CoT) reasoning. However, they often exhibit overthinking -- performing unnecessary reasoning steps even after arriving at the correct answer. Prior work has largely focused on qualitative analyses of overthinking through sample-based observations of long CoTs. In contrast, we present a quantitative analysis of overthinking from the perspective of self-doubt, characterized by excessive token usage devoted to re-verifying already-correct answer. We find that self-doubt significantly contributes to overthinking. In response, we introduce a simple and effective prompting method to reduce the model's over-reliance on input questions, thereby avoiding self-doubt. Specifically, we first prompt the model to question the validity of the input question, and then respond concisely based on the outcome of that evaluation. Experiments on three mathematical reasoning tasks and four datasets with missing premises demonstrate that our method substantially reduces answer length and yields significant improvements across nearly all datasets upon 4 widely-used RLLMs. Further analysis demonstrates that our method effectively minimizes the number of reasoning steps and reduces self-doubt.
Enhancing Input-Label Mapping in In-Context Learning with Contrastive Decoding
Feb 19, 2025



Large language models (LLMs) excel at a range of tasks through in-context learning (ICL), where only a few task examples guide their predictions. However, prior research highlights that LLMs often overlook input-label mapping information in ICL, relying more on their pre-trained knowledge. To address this issue, we introduce In-Context Contrastive Decoding (ICCD), a novel method that emphasizes input-label mapping by contrasting the output distributions between positive and negative in-context examples. Experiments on 7 natural language understanding (NLU) tasks show that our ICCD method brings consistent and significant improvement (up to +2.1 improvement on average) upon 6 different scales of LLMs without requiring additional training. Our approach is versatile, enhancing performance with various demonstration selection methods, demonstrating its broad applicability and effectiveness. The code and scripts will be publicly released.
AAKT: Enhancing Knowledge Tracing with Alternate Autoregressive Modeling
Feb 17, 2025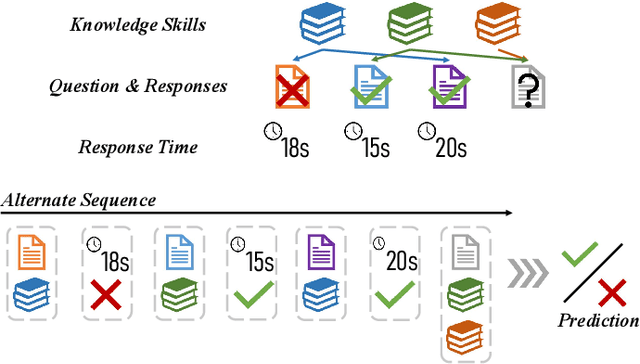
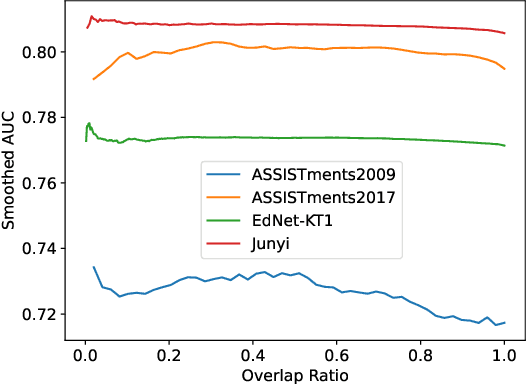
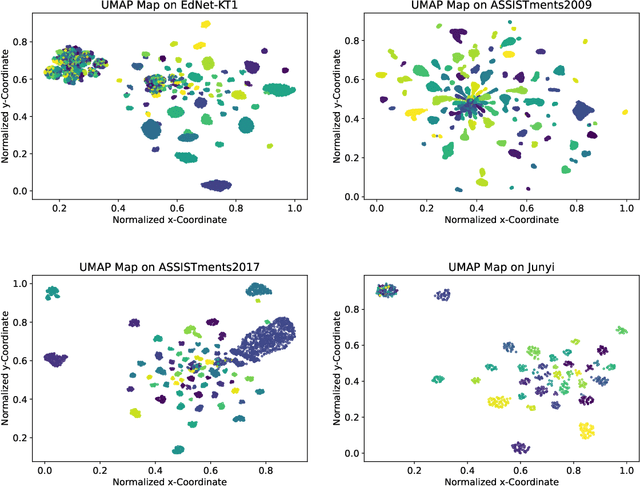
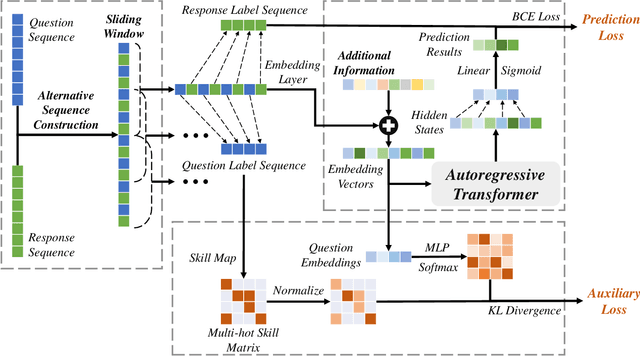
Knowledge Tracing (KT) aims to predict students' future performances based on their former exercises and additional information in educational settings. KT has received significant attention since it facilitates personalized experiences in educational situations. Simultaneously, the autoregressive modeling on the sequence of former exercises has been proven effective for this task. One of the primary challenges in autoregressive modeling for Knowledge Tracing is effectively representing the anterior (pre-response) and posterior (post-response) states of learners across exercises. Existing methods often employ complex model architectures to update learner states using question and response records. In this study, we propose a novel perspective on knowledge tracing task by treating it as a generative process, consistent with the principles of autoregressive models. We demonstrate that knowledge states can be directly represented through autoregressive encodings on a question-response alternate sequence, where model generate the most probable representation in hidden state space by analyzing history interactions. This approach underpins our framework, termed Alternate Autoregressive Knowledge Tracing (AAKT). Additionally, we incorporate supplementary educational information, such as question-related skills, into our framework through an auxiliary task, and include extra exercise details, like response time, as additional inputs. Our proposed framework is implemented using advanced autoregressive technologies from Natural Language Generation (NLG) for both training and prediction. Empirical evaluations on four real-world KT datasets indicate that AAKT consistently outperforms all baseline models in terms of AUC, ACC, and RMSE. Furthermore, extensive ablation studies and visualized analysis validate the effectiveness of key components in AAKT.
Explainable Few-shot Knowledge Tracing
May 23, 2024



Knowledge tracing (KT), aiming to mine students' mastery of knowledge by their exercise records and predict their performance on future test questions, is a critical task in educational assessment. While researchers achieved tremendous success with the rapid development of deep learning techniques, current knowledge tracing tasks fall into the cracks from real-world teaching scenarios. Relying heavily on extensive student data and solely predicting numerical performances differs from the settings where teachers assess students' knowledge state from limited practices and provide explanatory feedback. To fill this gap, we explore a new task formulation: Explainable Few-shot Knowledge Tracing. By leveraging the powerful reasoning and generation abilities of large language models (LLMs), we then propose a cognition-guided framework that can track the student knowledge from a few student records while providing natural language explanations. Experimental results from three widely used datasets show that LLMs can perform comparable or superior to competitive deep knowledge tracing methods. We also discuss potential directions and call for future improvements in relevant topics.
Wasserstein Dependent Graph Attention Network for Collaborative Filtering with Uncertainty
Apr 09, 2024



Collaborative filtering (CF) is an essential technique in recommender systems that provides personalized recommendations by only leveraging user-item interactions. However, most CF methods represent users and items as fixed points in the latent space, lacking the ability to capture uncertainty. In this paper, we propose a novel approach, called the Wasserstein dependent Graph ATtention network (W-GAT), for collaborative filtering with uncertainty. We utilize graph attention network and Wasserstein distance to address the limitations of LightGCN and Kullback-Leibler divergence (KL) divergence to learn Gaussian embedding for each user and item. Additionally, our method incorporates Wasserstein-dependent mutual information further to increase the similarity between positive pairs and to tackle the challenges induced by KL divergence. Experimental results on three benchmark datasets show the superiority of W-GAT compared to several representative baselines. Extensive experimental analysis validates the effectiveness of W-GAT in capturing uncertainty by modeling the range of user preferences and categories associated with items.
ProCQA: A Large-scale Community-based Programming Question Answering Dataset for Code Search
Mar 25, 2024Retrieval-based code question answering seeks to match user queries in natural language to relevant code snippets. Previous approaches typically rely on pretraining models using crafted bi-modal and uni-modal datasets to align text and code representations. In this paper, we introduce ProCQA, a large-scale programming question answering dataset extracted from the StackOverflow community, offering naturally structured mixed-modal QA pairs. To validate its effectiveness, we propose a modality-agnostic contrastive pre-training approach to improve the alignment of text and code representations of current code language models. Compared to previous models that primarily employ bimodal and unimodal pairs extracted from CodeSearchNet for pre-training, our model exhibits significant performance improvements across a wide range of code retrieval benchmarks.
A Review of Data Mining in Personalized Education: Current Trends and Future Prospects
Feb 27, 2024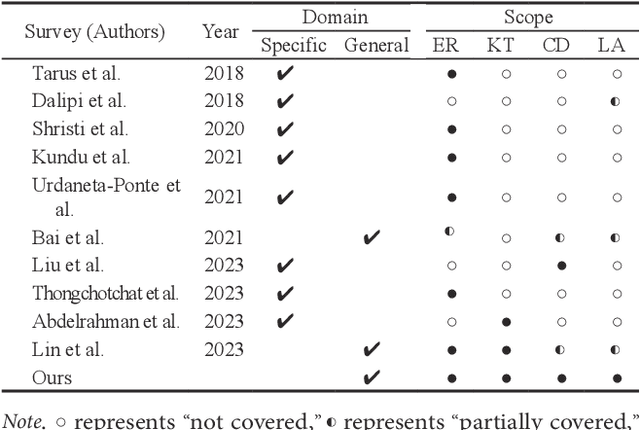
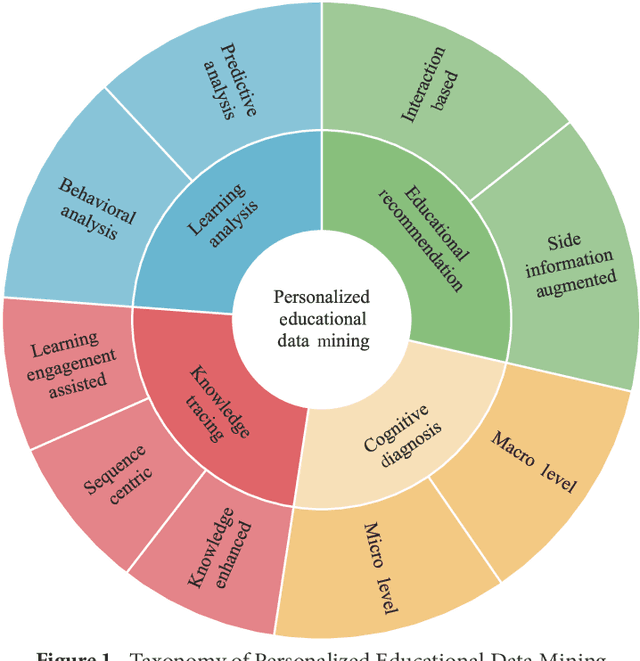
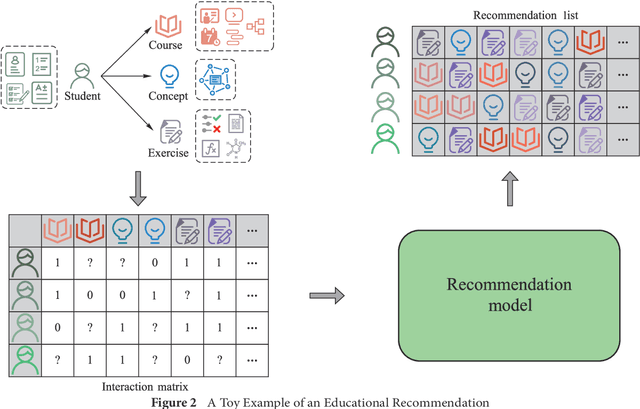
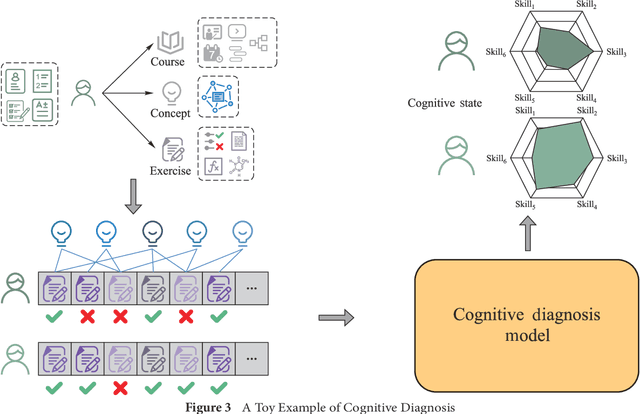
Personalized education, tailored to individual student needs, leverages educational technology and artificial intelligence (AI) in the digital age to enhance learning effectiveness. The integration of AI in educational platforms provides insights into academic performance, learning preferences, and behaviors, optimizing the personal learning process. Driven by data mining techniques, it not only benefits students but also provides educators and institutions with tools to craft customized learning experiences. To offer a comprehensive review of recent advancements in personalized educational data mining, this paper focuses on four primary scenarios: educational recommendation, cognitive diagnosis, knowledge tracing, and learning analysis. This paper presents a structured taxonomy for each area, compiles commonly used datasets, and identifies future research directions, emphasizing the role of data mining in enhancing personalized education and paving the way for future exploration and innovation.
* 25 pages, 5 figures
Revisiting Demonstration Selection Strategies in In-Context Learning
Jan 22, 2024



Large language models (LLMs) have shown an impressive ability to perform a wide range of tasks using in-context learning (ICL), where a few examples are used to describe a task to the model. However, the performance of ICL varies significantly with the choice of demonstrations, and it is still unclear why this happens or what factors will influence its choice. In this work, we first revisit the factors contributing to this variance from both data and model aspects, and find that the choice of demonstration is both data- and model-dependent. We further proposed a data- and model-dependent demonstration selection method, \textbf{TopK + ConE}, based on the assumption that \textit{the performance of a demonstration positively correlates with its contribution to the model's understanding of the test samples}, resulting in a simple and effective recipe for ICL. Empirically, our method yields consistent improvements in both language understanding and generation tasks with different model scales. Further analyses confirm that, besides the generality and stability under different circumstances, our method provides a unified explanation for the effectiveness of previous methods. Code will be released.
Towards Making the Most of ChatGPT for Machine Translation
Mar 24, 2023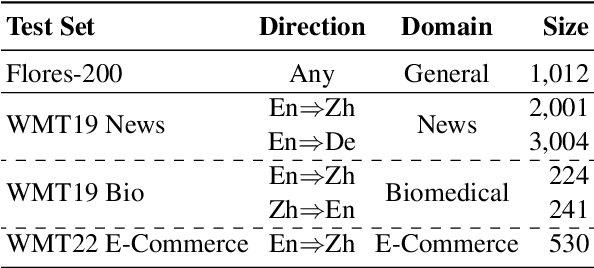
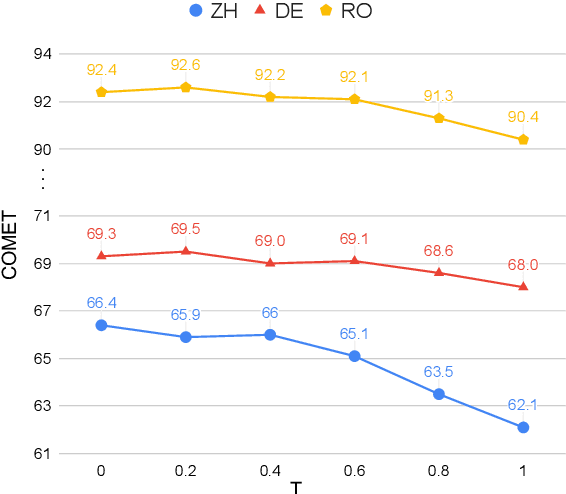

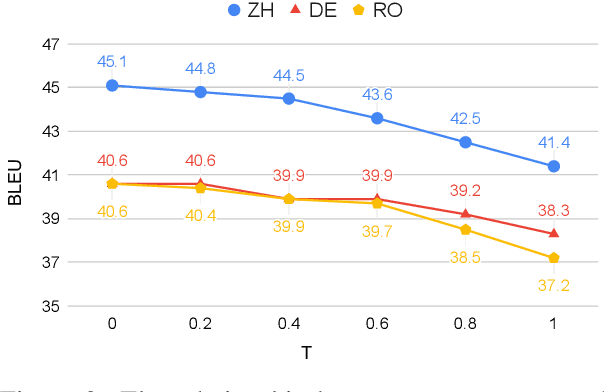
ChatGPT shows remarkable capabilities for machine translation (MT). Several prior studies have shown that it achieves comparable results to commercial systems for high-resource languages, but lags behind in complex tasks, e.g, low-resource and distant-language-pairs translation. However, they usually adopt simple prompts which can not fully elicit the capability of ChatGPT. In this report, we aim to further mine ChatGPT's translation ability by revisiting several aspects: temperature, task information, and domain information, and correspondingly propose two (simple but effective) prompts: Task-Specific Prompts (TSP) and Domain-Specific Prompts (DSP). We show that: 1) The performance of ChatGPT depends largely on temperature, and a lower temperature usually can achieve better performance; 2) Emphasizing the task information further improves ChatGPT's performance, particularly in complex MT tasks; 3) Introducing domain information can elicit ChatGPT's generalization ability and improve its performance in the specific domain; 4) ChatGPT tends to generate hallucinations for non-English-centric MT tasks, which can be partially addressed by our proposed prompts but still need to be highlighted for the MT/NLP community. We also explore the effects of advanced in-context learning strategies and find a (negative but interesting) observation: the powerful chain-of-thought prompt leads to word-by-word translation behavior, thus bringing significant translation degradation.