 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAR-BENCH: Benchmarking Legal Reasoning with Judgment Error Detection, Classification and Correction
Jan 30, 2026Legal judgments may contain errors due to the complexity of case circumstances and the abstract nature of legal concepts, while existing appellate review mechanisms face efficiency pressures from a surge in case volumes. Although current legal AI research focuses on tasks like judgment prediction and legal document generation, the task of judgment review differs fundamentally in its objectives and paradigm: it centers on detecting, classifying, and correcting errors after a judgment is issued, constituting anomaly detection rather than prediction or generation. To address this research gap, we introduce a novel task APPELLATE REVIEW, aiming to assess models' diagnostic reasoning and reliability in legal practice. We also construct a novel dataset benchmark AR-BENCH, which comprises 8,700 finely annotated decisions and 34,617 supplementary corpora. By evaluating 14 large language models, we reveal critical limitations in existing models' ability to identify legal application errors, providing empirical evidence for future improvements.
ProCQA: A Large-scale Community-based Programming Question Answering Dataset for Code Search
Mar 25, 2024Retrieval-based code question answering seeks to match user queries in natural language to relevant code snippets. Previous approaches typically rely on pretraining models using crafted bi-modal and uni-modal datasets to align text and code representations. In this paper, we introduce ProCQA, a large-scale programming question answering dataset extracted from the StackOverflow community, offering naturally structured mixed-modal QA pairs. To validate its effectiveness, we propose a modality-agnostic contrastive pre-training approach to improve the alignment of text and code representations of current code language models. Compared to previous models that primarily employ bimodal and unimodal pairs extracted from CodeSearchNet for pre-training, our model exhibits significant performance improvements across a wide range of code retrieval benchmarks.
Knowledge-Driven CoT: Exploring Faithful Reasoning in LLMs for Knowledge-intensive Question Answering
Aug 25, 2023



Equipped with Chain-of-Thought (CoT), Large language models (LLMs) have shown impressive reasoning ability in various downstream tasks. Even so, suffering from hallucinations and the inability to access external knowledge, LLMs often come with incorrect or unfaithful intermediate reasoning steps, especially in the context of answering knowledge-intensive tasks such as KBQA. To alleviate this issue, we propose a framework called Knowledge-Driven Chain-of-Thought (KD-CoT) to verify and modify reasoning traces in CoT via interaction with external knowledge, and thus overcome the hallucinations and error propagation. Concretely, we formulate the CoT rationale process of LLMs into a structured multi-round QA format. In each round, LLMs interact with a QA system that retrieves external knowledge and produce faithful reasoning traces based on retrieved precise answers. The structured CoT reasoning of LLMs is facilitated by our developed KBQA CoT collection, which serves as in-context learning demonstrations and can also be utilized as feedback augmentation to train a robust retriever. Extensive experiments on WebQSP and ComplexWebQuestion datasets demonstrate the effectiveness of proposed KD-CoT in task-solving reasoning generation, which outperforms the vanilla CoT ICL with an absolute success rate of 8.0% and 5.1%. Furthermore, our proposed feedback-augmented retriever outperforms the state-of-the-art baselines for retrieving knowledge, achieving significant improvement in Hit performance.
Causal Intervention for Fairness in Multi-behavior Recommendation
Sep 10, 2022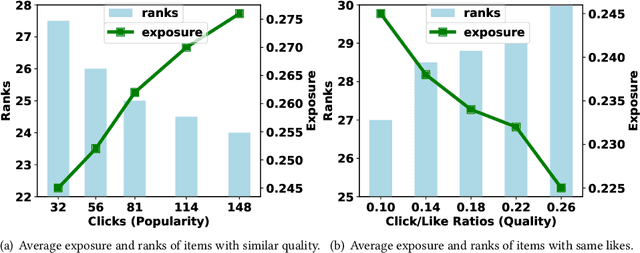

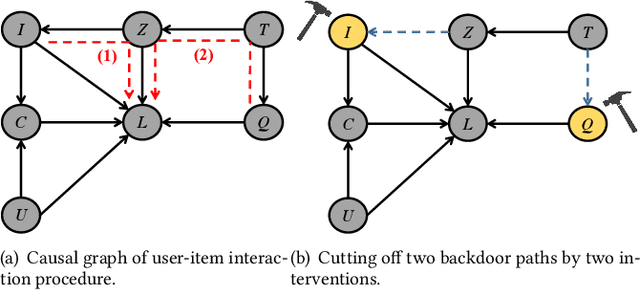
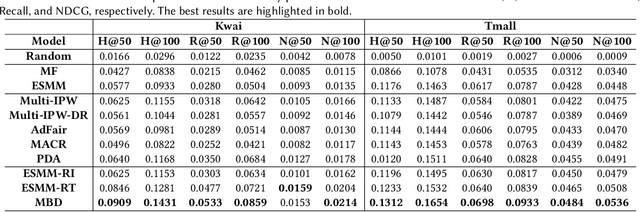
Recommender systems usually learn user interests from various user behaviors, including clicks and post-click behaviors (e.g., like and favorite). However, these behaviors inevitably exhibit popularity bias, leading to some unfairness issues: 1) for items with similar quality, more popular ones get more exposure; and 2) even worse the popular items with lower popularity might receive more exposure. Existing work on mitigating popularity bias blindly eliminates the bias and usually ignores the effect of item quality. We argue that the relationships between different user behaviors (e.g., conversion rate) actually reflect the item quality. Therefore, to handle the unfairness issues, we propose to mitigate the popularity bias by considering multiple user behaviors. In this work, we examine causal relationships behind the interaction generation procedure in multi-behavior recommendation. Specifically, we find that: 1) item popularity is a confounder between the exposed items and users' post-click interactions, leading to the first unfairness; and 2) some hidden confounders (e.g., the reputation of item producers) affect both item popularity and quality, resulting in the second unfairness. To alleviate these confounding issues, we propose a causal framework to estimate the causal effect, which leverages backdoor adjustment to block the backdoor paths caused by the confounders. In the inference stage, we remove the negative effect of popularity and utilize the good effect of quality for recommendation. Experiments on two real-world datasets validate the effectiveness of our proposed framework, which enhances fairness without sacrificing recommendation accuracy.