 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNarrative Flattening: How Post-Training Compresses Thematic, Affective, and Stylistic Variation in LLM Fiction
May 27, 2026Large language models produce fluent fiction, yet their creative output is widely seen as flat. We ask where this quality originates in the training and whether it affects different domains of human fiction equally. We construct a matched story-continuation paradigm across StoryStar (public-platform), TMAS (prompt-guided), and The New Yorker (professional literary)-and compare continuations from four OLMo 32B checkpoints (Base, SFT, DPO, RLVR) against matched human text. Because these checkpoints share architecture, scale, tokenizer, and pretraining, the design isolates the post-training effect. We measure each continuation along three sentence-level dimensions: thematic motion, affective prevalence, and linguistic diversity. Across all three, post-training compresses dynamic variation: thematic transitions become more uniform, high-intensity emotions give way to neutrality, and stylistic diversity across stories shrinks. We term this progressive loss narrative flattening. The effect is directionally stable across story domains but gap size depends on the human baseline: professional literary fiction is compressed most, while public-platform and prompt-guided stories show smaller gaps, consistent with their human baselines sitting closer to the model's default rhythm. Post-trained endpoints converge across domains, suggesting alignment produces a continuation regime largely insensitive to the source domain's narrative texture.
The MiniMax-M2 Series: Mini Activations Unleashing Max Real-World Intelligence
May 26, 2026We introduce the MiniMax-M2 series, a family of Mixture-of-Experts language models built around the principle that mini activations can unleash maximum real-world intelligence. The flagship M2 contains 229.9B total parameters with only 9.8B activated per token. Designed end-to-end for agentic deployment, the M2 series rests on three components: (i) agent-driven data pipelines producing large-scale, verifiable trajectories across agentic coding and agentic cowork, each grounded in an executable workspace and an artifact-aligned reward; (ii) Forge, a scalable agent-native RL system that adapts to long-horizon agent trajectories, paired with windowed-FIFO scheduling, prefix-tree merging, inference optimization, and a clean training-inference-agent decoupling that supports both white-box and black-box agents; (iii) the latest M2.7 checkpoint takes an early step toward self-evolution -- autonomously debugging training runs and modifying its own scaffold. Across M2 through M2.7, this combination translates a mini-activation footprint into frontier-tier performance on agentic coding, deep search, office-task, and reasoning benchmarks.
Audio-Cogito: Towards Deep Audio Reasoning in Large Audio Language Models
Apr 14, 2026Recent advances in reasoning models have driven significant progress in text and multimodal domains, yet audio reasoning remains relatively limited. Only a few Large Audio Language Models (LALMs) incorporate explicit Chain-of-Thought (CoT) reasoning, and their capabilities are often inconsistent and insufficient for complex tasks. To bridge this gap, we introduce Audio-Cogito, a fully open-source solution for deep audio reasoning. We develop Cogito-pipe for high-quality audio reasoning data curation, producing 545k reasoning samples that will be released after review. Based on this dataset, we adopt a self-distillation strategy for model fine-tuning. Experiments on the MMAR benchmark, the only audio benchmark evaluating the CoT process, show that our model achieves the best performance among open-source models and matches or surpasses certain closed-source models in specific metrics. Our approach also ranks among the top-tier systems in the Interspeech 2026 Audio Reasoning Challenge.
Temporal Leakage in Search-Engine Date-Filtered Web Retrieval: A Case Study from Retrospective Forecasting
Jan 31, 2026Search-engine date filters are widely used to enforce pre-cutoff retrieval in retrospective evaluations of search-augmented forecasters. We show this approach is unreliable: auditing Google Search with a before: filter, 71% of questions return at least one page containing strong post-cutoff leakage, and for 41%, at least one page directly reveals the answer. Using a large language model (LLM), gpt-oss-120b, to forecast with these leaky documents, we demonstrate an inflated prediction accuracy (Brier score 0.108 vs. 0.242 with leak-free documents). We characterize common leakage mechanisms, including updated articles, related-content modules, unreliable metadata/timestamps, and absence-based signals, and argue that date-restricted search is insufficient for temporal evaluation. We recommend stronger retrieval safeguards or evaluation on frozen, time-stamped web snapshots to ensure credible retrospective forecasting.
From Horizontal Layering to Vertical Integration: A Comparative Study of the AI-Driven Software Development Paradigm
Jan 30, 2026This paper examines the organizational implications of Generative AI adoption in software engineering through a multiple-case comparative study. We contrast two development environments: a traditional enterprise (brownfield) and an AI-native startup (greenfield). Our analysis reveals that transitioning from Horizontal Layering (functional specialization) to Vertical Integration (end-to-end ownership) yields 8-fold to 33-fold reductions in resource consumption. We attribute these gains to the emergence of Super Employees, AI-augmented engineers who span traditional role boundaries, and the elimination of inter-functional coordination overhead. Theoretically, we propose Human-AI Collaboration Efficacy as the primary optimization target for engineering organizations, supplanting individual productivity metrics. Our Total Factor Productivity analysis identifies an AI Distortion Effect that diminishes returns to labor scale while amplifying technological leverage. We conclude with managerial strategies for organizational redesign, including the reactivation of idle cognitive bandwidth in senior engineers and the suppression of blind scale expansion.
Simulated Ignorance Fails: A Systematic Study of LLM Behaviors on Forecasting Problems Before Model Knowledge Cutoff
Jan 20, 2026Evaluating LLM forecasting capabilities is constrained by a fundamental tension: prospective evaluation offers methodological rigor but prohibitive latency, while retrospective forecasting (RF) -- evaluating on already-resolved events -- faces rapidly shrinking clean evaluation data as SOTA models possess increasingly recent knowledge cutoffs. Simulated Ignorance (SI), prompting models to suppress pre-cutoff knowledge, has emerged as a potential solution. We provide the first systematic test of whether SI can approximate True Ignorance (TI). Across 477 competition-level questions and 9 models, we find that SI fails systematically: (1) cutoff instructions leave a 52% performance gap between SI and TI; (2) chain-of-thought reasoning fails to suppress prior knowledge, even when reasoning traces contain no explicit post-cutoff references; (3) reasoning-optimized models exhibit worse SI fidelity despite superior reasoning trace quality. These findings demonstrate that prompts cannot reliably "rewind" model knowledge. We conclude that RF on pre-cutoff events is methodologically flawed; we recommend against using SI-based retrospective setups to benchmark forecasting capabilities.
A Unified Spoken Language Model with Injected Emotional-Attribution Thinking for Human-like Interaction
Jan 08, 2026This paper presents a unified spoken language model for emotional intelligence, enhanced by a novel data construction strategy termed Injected Emotional-Attribution Thinking (IEAT). IEAT incorporates user emotional states and their underlying causes into the model's internal reasoning process, enabling emotion-aware reasoning to be internalized rather than treated as explicit supervision. The model is trained with a two-stage progressive strategy. The first stage performs speech-text alignment and emotional attribute modeling via self-distillation, while the second stage conducts end-to-end cross-modal joint optimization to ensure consistency between textual and spoken emotional expressions. Experiments on the Human-like Spoken Dialogue Systems Challenge (HumDial) Emotional Intelligence benchmark demonstrate that the proposed approach achieves top-ranked performance across emotional trajectory modeling, emotional reasoning, and empathetic response generation under both LLM-based and human evaluations.
TELEVAL: A Dynamic Benchmark Designed for Spoken Language Models in Chinese Interactive Scenarios
Jul 24, 2025Spoken language models (SLMs) have seen rapid progress in recent years, along with the development of numerous benchmarks for evaluating their performance. However, most existing benchmarks primarily focus on evaluating whether SLMs can perform complex tasks comparable to those tackled by large language models (LLMs), often failing to align with how users naturally interact in real-world conversational scenarios. In this paper, we propose TELEVAL, a dynamic benchmark specifically designed to evaluate SLMs' effectiveness as conversational agents in realistic Chinese interactive settings. TELEVAL defines three evaluation dimensions: Explicit Semantics, Paralinguistic and Implicit Semantics, and System Abilities. It adopts a dialogue format consistent with real-world usage and evaluates text and audio outputs separately. TELEVAL particularly focuses on the model's ability to extract implicit cues from user speech and respond appropriately without additional instructions. Our experiments demonstrate that despite recent progress, existing SLMs still have considerable room for improvement in natural conversational tasks. We hope that TELEVAL can serve as a user-centered evaluation framework that directly reflects the user experience and contributes to the development of more capable dialogue-oriented SLMs.
BoSS: Beyond-Semantic Speech
Jul 23, 2025Human communication involves more than explicit semantics, with implicit signals and contextual cues playing a critical role in shaping meaning. However, modern speech technologies, such as Automatic Speech Recognition (ASR) and Text-to-Speech (TTS) often fail to capture these beyond-semantic dimensions. To better characterize and benchmark the progression of speech intelligence, we introduce Spoken Interaction System Capability Levels (L1-L5), a hierarchical framework illustrated the evolution of spoken dialogue systems from basic command recognition to human-like social interaction. To support these advanced capabilities, we propose Beyond-Semantic Speech (BoSS), which refers to the set of information in speech communication that encompasses but transcends explicit semantics. It conveys emotions, contexts, and modifies or extends meanings through multidimensional features such as affective cues, contextual dynamics, and implicit semantics, thereby enhancing the understanding of communicative intentions and scenarios. We present a formalized framework for BoSS, leveraging cognitive relevance theories and machine learning models to analyze temporal and contextual speech dynamics. We evaluate BoSS-related attributes across five different dimensions, reveals that current spoken language models (SLMs) are hard to fully interpret beyond-semantic signals. These findings highlight the need for advancing BoSS research to enable richer, more context-aware human-machine communication.
Multi-Label Classification with Generative AI Models in Healthcare: A Case Study of Suicidality and Risk Factors
Jul 22, 2025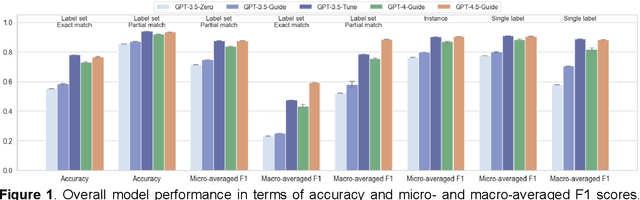
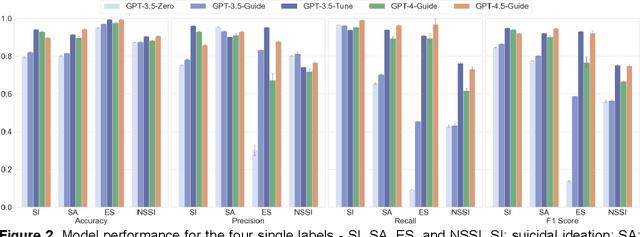
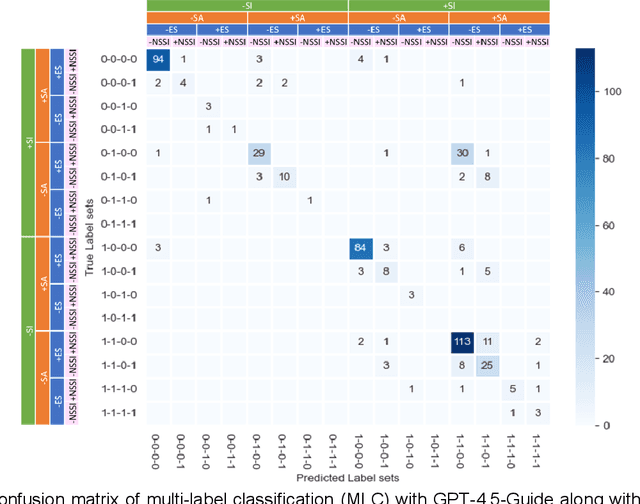
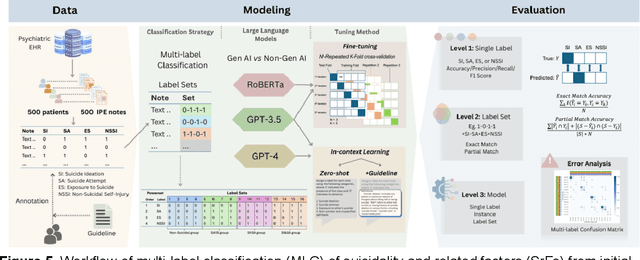
Suicide remains a pressing global health crisis, with over 720,000 deaths annually and millions more affected by suicide ideation (SI) and suicide attempts (SA). Early identification of suicidality-related factors (SrFs), including SI, SA, exposure to suicide (ES), and non-suicidal self-injury (NSSI), is critical for timely intervention. While prior studies have applied AI to detect SrFs in clinical notes, most treat suicidality as a binary classification task, overlooking the complexity of cooccurring risk factors. This study explores the use of generative large language models (LLMs), specifically GPT-3.5 and GPT-4.5, for multi-label classification (MLC) of SrFs from psychiatric electronic health records (EHRs). We present a novel end to end generative MLC pipeline and introduce advanced evaluation methods, including label set level metrics and a multilabel confusion matrix for error analysis. Finetuned GPT-3.5 achieved top performance with 0.94 partial match accuracy and 0.91 F1 score, while GPT-4.5 with guided prompting showed superior performance across label sets, including rare or minority label sets, indicating a more balanced and robust performance. Our findings reveal systematic error patterns, such as the conflation of SI and SA, and highlight the models tendency toward cautious over labeling. This work not only demonstrates the feasibility of using generative AI for complex clinical classification tasks but also provides a blueprint for structuring unstructured EHR data to support large scale clinical research and evidence based medicine.