 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal Leakage in Search-Engine Date-Filtered Web Retrieval: A Case Study from Retrospective Forecasting
Jan 31, 2026Search-engine date filters are widely used to enforce pre-cutoff retrieval in retrospective evaluations of search-augmented forecasters. We show this approach is unreliable: auditing Google Search with a before: filter, 71% of questions return at least one page containing strong post-cutoff leakage, and for 41%, at least one page directly reveals the answer. Using a large language model (LLM), gpt-oss-120b, to forecast with these leaky documents, we demonstrate an inflated prediction accuracy (Brier score 0.108 vs. 0.242 with leak-free documents). We characterize common leakage mechanisms, including updated articles, related-content modules, unreliable metadata/timestamps, and absence-based signals, and argue that date-restricted search is insufficient for temporal evaluation. We recommend stronger retrieval safeguards or evaluation on frozen, time-stamped web snapshots to ensure credible retrospective forecasting.
Simulated Ignorance Fails: A Systematic Study of LLM Behaviors on Forecasting Problems Before Model Knowledge Cutoff
Jan 20, 2026Evaluating LLM forecasting capabilities is constrained by a fundamental tension: prospective evaluation offers methodological rigor but prohibitive latency, while retrospective forecasting (RF) -- evaluating on already-resolved events -- faces rapidly shrinking clean evaluation data as SOTA models possess increasingly recent knowledge cutoffs. Simulated Ignorance (SI), prompting models to suppress pre-cutoff knowledge, has emerged as a potential solution. We provide the first systematic test of whether SI can approximate True Ignorance (TI). Across 477 competition-level questions and 9 models, we find that SI fails systematically: (1) cutoff instructions leave a 52% performance gap between SI and TI; (2) chain-of-thought reasoning fails to suppress prior knowledge, even when reasoning traces contain no explicit post-cutoff references; (3) reasoning-optimized models exhibit worse SI fidelity despite superior reasoning trace quality. These findings demonstrate that prompts cannot reliably "rewind" model knowledge. We conclude that RF on pre-cutoff events is methodologically flawed; we recommend against using SI-based retrospective setups to benchmark forecasting capabilities.
Bridging Human Interpretation and Machine Representation: A Landscape of Qualitative Data Analysis in the LLM Era
Jan 16, 2026LLMs are increasingly used to support qualitative research, yet existing systems produce outputs that vary widely--from trace-faithful summaries to theory-mediated explanations and system models. To make these differences explicit, we introduce a 4$\times$4 landscape crossing four levels of meaning-making (descriptive, categorical, interpretive, theoretical) with four levels of modeling (static structure, stages/timelines, causal pathways, feedback dynamics). Applying the landscape to prior LLM-based automation highlights a strong skew toward low-level meaning and low-commitment representations, with few reliable attempts at interpretive/theoretical inference or dynamical modeling. Based on the revealed gap, we outline an agenda for applying and building LLM-systems that make their interpretive and modeling commitments explicit, selectable, and governable.
Beyond LLMs: A Linguistic Approach to Causal Graph Generation from Narrative Texts
Apr 10, 2025



We propose a novel framework for generating causal graphs from narrative texts, bridging high-level causality and detailed event-specific relationships. Our method first extracts concise, agent-centered vertices using large language model (LLM)-based summarization. We introduce an "Expert Index," comprising seven linguistically informed features, integrated into a Situation-Task-Action-Consequence (STAC) classification model. This hybrid system, combining RoBERTa embeddings with the Expert Index, achieves superior precision in causal link identification compared to pure LLM-based approaches. Finally, a structured five-iteration prompting process refines and constructs connected causal graphs. Experiments on 100 narrative chapters and short stories demonstrate that our approach consistently outperforms GPT-4o and Claude 3.5 in causal graph quality, while maintaining readability. The open-source tool provides an interpretable, efficient solution for capturing nuanced causal chains in narratives.
UOUO: Uncontextualized Uncommon Objects for Measuring Knowledge Horizons of Vision Language Models
Jul 25, 2024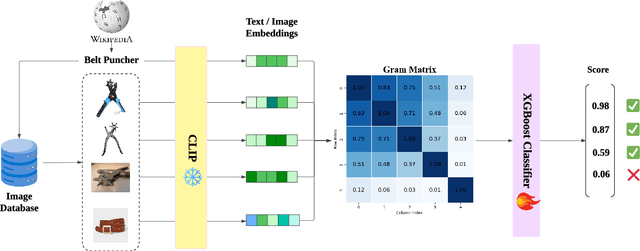
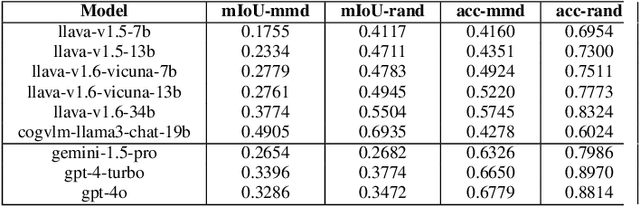
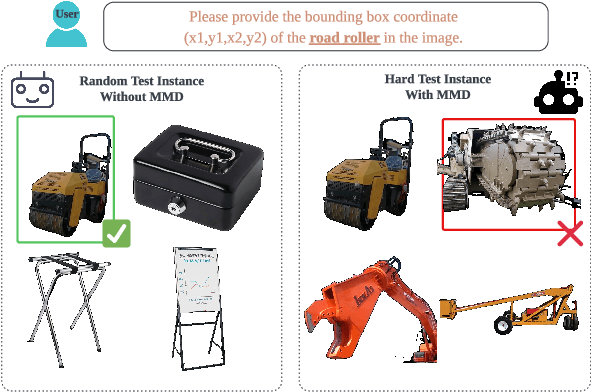
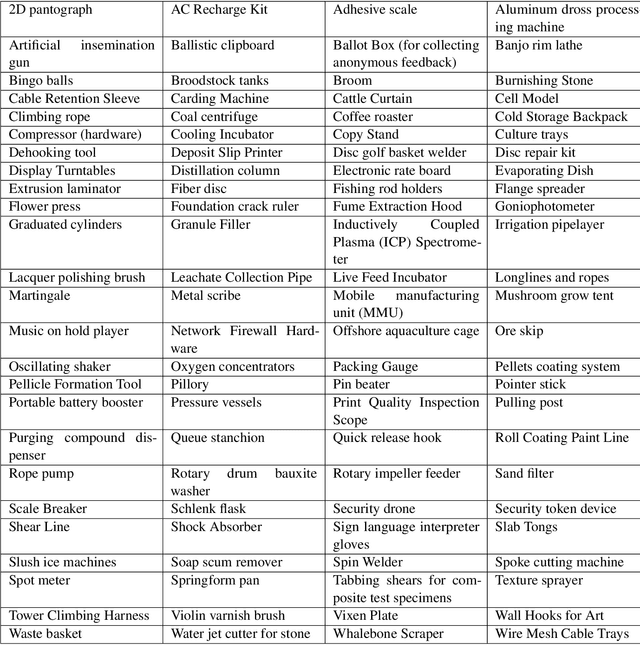
Smaller-scale Vision-Langauge Models (VLMs) often claim to perform on par with larger models in general-domain visual grounding and question-answering benchmarks while offering advantages in computational efficiency and storage. However, their ability to handle rare objects, which fall into the long tail of data distributions, is less understood. To rigorously evaluate this aspect, we introduce the "Uncontextualized Uncommon Objects" (UOUO) benchmark. This benchmark focuses on systematically testing VLMs with both large and small parameter counts on rare and specialized objects. Our comprehensive analysis reveals that while smaller VLMs maintain competitive performance on common datasets, they significantly underperform on tasks involving uncommon objects. We also propose an advanced, scalable pipeline for data collection and cleaning, ensuring the UOUO benchmark provides high-quality, challenging instances. These findings highlight the need to consider long-tail distributions when assessing the true capabilities of VLMs.
Towards Robustness of Text-to-SQL Models Against Natural and Realistic Adversarial Table Perturbation
Dec 20, 2022The robustness of Text-to-SQL parsers against adversarial perturbations plays a crucial role in delivering highly reliable applications. Previous studies along this line primarily focused on perturbations in the natural language question side, neglecting the variability of tables. Motivated by this, we propose the Adversarial Table Perturbation (ATP) as a new attacking paradigm to measure the robustness of Text-to-SQL models. Following this proposition, we curate ADVETA, the first robustness evaluation benchmark featuring natural and realistic ATPs. All tested state-of-the-art models experience dramatic performance drops on ADVETA, revealing models' vulnerability in real-world practices. To defend against ATP, we build a systematic adversarial training example generation framework tailored for better contextualization of tabular data. Experiments show that our approach not only brings the best robustness improvement against table-side perturbations but also substantially empowers models against NL-side perturbations. We release our benchmark and code at: https://github.com/microsoft/ContextualSP.
LogiGAN: Learning Logical Reasoning via Adversarial Pre-training
May 18, 2022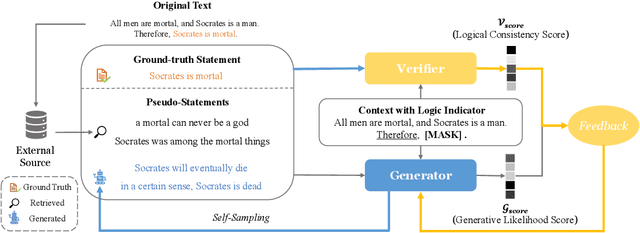
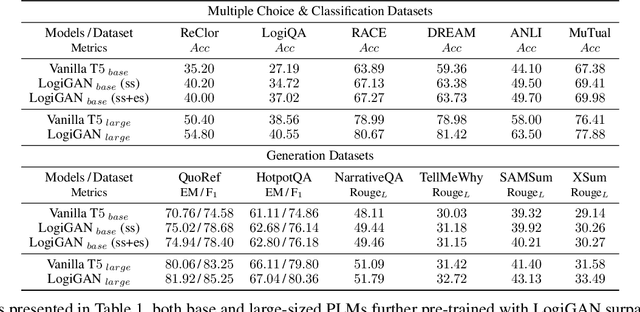
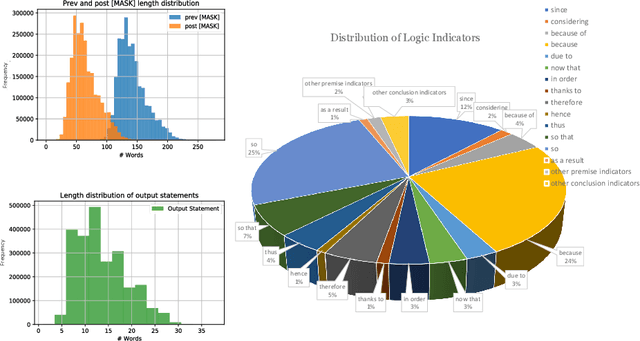
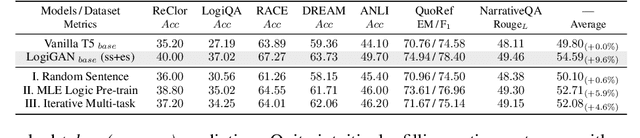
We present LogiGAN, an unsupervised adversarial pre-training framework for improving logical reasoning abilities of language models. Upon automatic identifying logical reasoning phenomena in massive text corpus via detection heuristics, we train language models to predict the masked-out logical statements. Inspired by the facilitation effect of reflective thinking in human learning, we analogically simulate the learning-thinking process with an adversarial Generator-Verifier architecture to assist logic learning. LogiGAN implements a novel sequential GAN approach that (a) circumvents the non-differentiable challenge of the sequential GAN by leveraging the Generator as a sentence-level generative likelihood scorer with a learning objective of reaching scoring consensus with the Verifier; (b) is computationally feasible for large-scale pre-training with arbitrary target length. Both base and large size language models pre-trained with LogiGAN demonstrate obvious performance improvement on 12 datasets requiring general reasoning abilities, revealing the fundamental role of logic in broad reasoning, as well as the effectiveness of LogiGAN. Ablation studies on LogiGAN components reveal the relative orthogonality between linguistic and logic abilities and suggest that reflective thinking's facilitation effect might also generalize to machine learning.
Reasoning Like Program Executors
Jan 27, 2022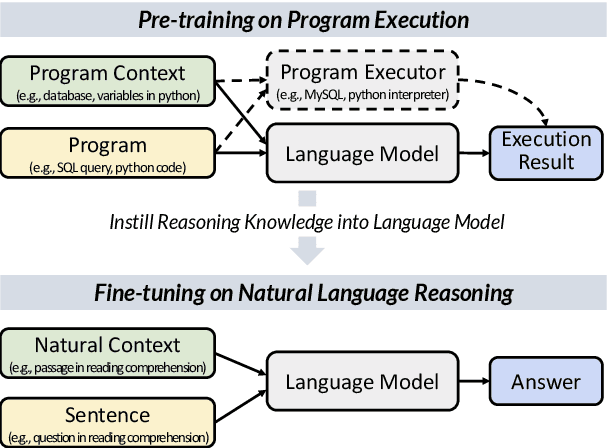

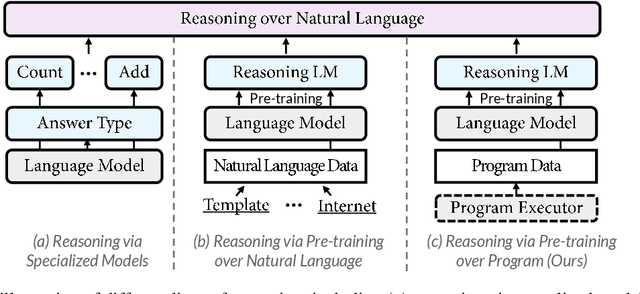
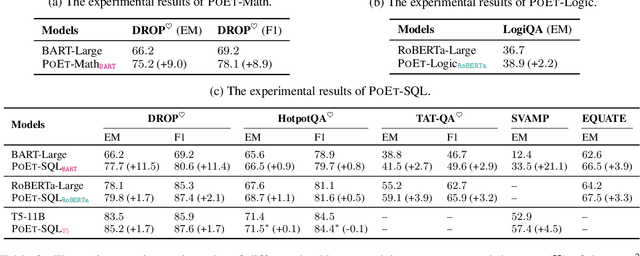
Reasoning over natural language is a long-standing goal for the research community. However, studies have shown that existing language models are inadequate in reasoning. To address the issue, we present POET, a new pre-training paradigm. Through pre-training language models with programs and their execution results, POET empowers language models to harvest the reasoning knowledge possessed in program executors via a data-driven approach. POET is conceptually simple and can be instantiated by different kinds of programs. In this paper, we show three empirically powerful instances, i.e., POET-Math, POET-Logic, and POET-SQL. Experimental results on six benchmarks demonstrate that POET can significantly boost model performance on natural language reasoning, such as numerical reasoning, logical reasoning, and multi-hop reasoning. Taking the DROP benchmark as a representative example, POET improves the F1 metric of BART from 69.2% to 80.6%. Furthermore, POET shines in giant language models, pushing the F1 metric of T5-11B to 87.6% and achieving a new state-of-the-art performance on DROP. POET opens a new gate on reasoning-enhancement pre-training and we hope our analysis would shed light on the future research of reasoning like program executors.