 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Investigation of Robustness of LLMs in Mathematical Reasoning: Benchmarking with Mathematically-Equivalent Transformation of Advanced Mathematical Problems
Aug 12, 2025In this paper, we introduce a systematic framework beyond conventional method to assess LLMs' mathematical-reasoning robustness by stress-testing them on advanced math problems that are mathematically equivalent but with linguistic and parametric variation. These transformations allow us to measure the sensitivity of LLMs to non-mathematical perturbations, thereby enabling a more accurate evaluation of their mathematical reasoning capabilities. Using this new evaluation methodology, we created PutnamGAP, a new benchmark dataset with multiple mathematically-equivalent variations of competition-level math problems. With the new dataset, we evaluate multiple families of representative LLMs and examine their robustness. Across 18 commercial and open-source models we observe sharp performance degradation on the variants. OpenAI's flagship reasoning model, O3, scores 49 % on the originals but drops by 4 percentage points on surface variants, and by 10.5 percentage points on core-step-based variants, while smaller models fare far worse. Overall, the results show that the proposed new evaluation methodology is effective for deepening our understanding of the robustness of LLMs and generating new insights for further improving their mathematical reasoning capabilities.
Atomic Reasoning for Scientific Table Claim Verification
Jun 08, 2025Scientific texts often convey authority due to their technical language and complex data. However, this complexity can sometimes lead to the spread of misinformation. Non-experts are particularly susceptible to misleading claims based on scientific tables due to their high information density and perceived credibility. Existing table claim verification models, including state-of-the-art large language models (LLMs), often struggle with precise fine-grained reasoning, resulting in errors and a lack of precision in verifying scientific claims. Inspired by Cognitive Load Theory, we propose that enhancing a model's ability to interpret table-based claims involves reducing cognitive load by developing modular, reusable reasoning components (i.e., atomic skills). We introduce a skill-chaining schema that dynamically composes these skills to facilitate more accurate and generalizable reasoning with a reduced cognitive load. To evaluate this, we create SciAtomicBench, a cross-domain benchmark with fine-grained reasoning annotations. With only 350 fine-tuning examples, our model trained by atomic reasoning outperforms GPT-4o's chain-of-thought method, achieving state-of-the-art results with far less training data.
VTool-R1: VLMs Learn to Think with Images via Reinforcement Learning on Multimodal Tool Use
May 25, 2025Reinforcement Learning Finetuning (RFT) has significantly advanced the reasoning capabilities of large language models (LLMs) by enabling long chains of thought, self-correction, and effective tool use. While recent works attempt to extend RFT to vision-language models (VLMs), these efforts largely produce text-only reasoning conditioned on static image inputs, falling short of true multimodal reasoning in the response. In contrast, test-time methods like Visual Sketchpad incorporate visual steps but lack training mechanisms. We introduce VTool-R1, the first framework that trains VLMs to generate multimodal chains of thought by interleaving text and intermediate visual reasoning steps. VTool-R1 integrates Python-based visual editing tools into the RFT process, enabling VLMs to learn when and how to generate visual reasoning steps that benefit final reasoning. Trained with outcome-based rewards tied to task accuracy, our approach elicits strategic visual tool use for reasoning without relying on process-based supervision. Experiments on structured visual question answering over charts and tables show that VTool-R1 enhances reasoning performance by teaching VLMs to "think with images" and generate multimodal chain of thoughts with tools.
ModelingAgent: Bridging LLMs and Mathematical Modeling for Real-World Challenges
May 21, 2025
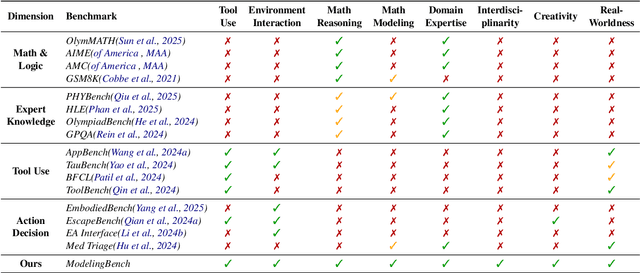
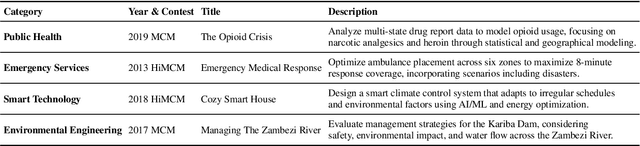
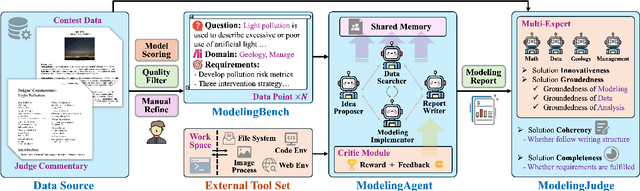
Recent progress in large language models (LLMs) has enabled substantial advances in solving mathematical problems. However, existing benchmarks often fail to reflect the complexity of real-world problems, which demand open-ended, interdisciplinary reasoning and integration of computational tools. To address this gap, we introduce ModelingBench, a novel benchmark featuring real-world-inspired, open-ended problems from math modeling competitions across diverse domains, ranging from urban traffic optimization to ecosystem resource planning. These tasks require translating natural language into formal mathematical formulations, applying appropriate tools, and producing structured, defensible reports. ModelingBench also supports multiple valid solutions, capturing the ambiguity and creativity of practical modeling. We also present ModelingAgent, a multi-agent framework that coordinates tool use, supports structured workflows, and enables iterative self-refinement to generate well-grounded, creative solutions. To evaluate outputs, we further propose ModelingJudge, an expert-in-the-loop system leveraging LLMs as domain-specialized judges assessing solutions from multiple expert perspectives. Empirical results show that ModelingAgent substantially outperforms strong baselines and often produces solutions indistinguishable from those of human experts. Together, our work provides a comprehensive framework for evaluating and advancing real-world problem-solving in open-ended, interdisciplinary modeling challenges.
Leveraging LLMs for Predicting Unknown Diagnoses from Clinical Notes
Mar 28, 2025Electronic Health Records (EHRs) often lack explicit links between medications and diagnoses, making clinical decision-making and research more difficult. Even when links exist, diagnosis lists may be incomplete, especially during early patient visits. Discharge summaries tend to provide more complete information, which can help infer accurate diagnoses, especially with the help of large language models (LLMs). This study investigates whether LLMs can predict implicitly mentioned diagnoses from clinical notes and link them to corresponding medications. We address two research questions: (1) Does majority voting across diverse LLM configurations outperform the best single configuration in diagnosis prediction? (2) How sensitive is majority voting accuracy to LLM hyperparameters such as temperature, top-p, and summary length? To evaluate, we created a new dataset of 240 expert-annotated medication-diagnosis pairs from 20 MIMIC-IV notes. Using GPT-3.5 Turbo, we ran 18 prompting configurations across short and long summary lengths, generating 8568 test cases. Results show that majority voting achieved 75 percent accuracy, outperforming the best single configuration at 66 percent. No single hyperparameter setting dominated, but combining deterministic, balanced, and exploratory strategies improved performance. Shorter summaries generally led to higher accuracy.In conclusion, ensemble-style majority voting with diverse LLM configurations improves diagnosis prediction in EHRs and offers a promising method to link medications and diagnoses in clinical texts.
Cache-of-Thought: Master-Apprentice Framework for Cost-Effective Vision Language Model Inference
Feb 27, 2025Vision Language Models (VLMs) have achieved remarkable success in a wide range of vision applications of increasing complexity and scales, yet choosing the right VLM model size involves a trade-off between response quality and cost. While smaller VLMs are cheaper to run, they typically produce responses only marginally better than random guessing on benchmarks such as MMMU. In this paper, we propose Cache of Thought (CoT), a master apprentice framework for collaborative inference between large and small VLMs. CoT manages high quality query results from large VLMs (master) in a cache, which are then selected via a novel multi modal retrieval and in-context learning to aid the performance of small VLMs (apprentice). We extensively evaluate CoT on various widely recognized and challenging general VQA benchmarks, and show that CoT increases overall VQA performance by up to 7.7% under the same budget, and specifically boosts the performance of apprentice VLMs by up to 36.6%.
The Law of Knowledge Overshadowing: Towards Understanding, Predicting, and Preventing LLM Hallucination
Feb 22, 2025



Hallucination is a persistent challenge in large language models (LLMs), where even with rigorous quality control, models often generate distorted facts. This paradox, in which error generation continues despite high-quality training data, calls for a deeper understanding of the underlying LLM mechanisms. To address it, we propose a novel concept: knowledge overshadowing, where model's dominant knowledge can obscure less prominent knowledge during text generation, causing the model to fabricate inaccurate details. Building on this idea, we introduce a novel framework to quantify factual hallucinations by modeling knowledge overshadowing. Central to our approach is the log-linear law, which predicts that the rate of factual hallucination increases linearly with the logarithmic scale of (1) Knowledge Popularity, (2) Knowledge Length, and (3) Model Size. The law provides a means to preemptively quantify hallucinations, offering foresight into their occurrence even before model training or inference. Built on overshadowing effect, we propose a new decoding strategy CoDa, to mitigate hallucinations, which notably enhance model factuality on Overshadow (27.9%), MemoTrap (13.1%) and NQ-Swap (18.3%). Our findings not only deepen understandings of the underlying mechanisms behind hallucinations but also provide actionable insights for developing more predictable and controllable language models.
ORBIT: Cost-Effective Dataset Curation for Large Language Model Domain Adaptation with an Astronomy Case Study
Dec 19, 2024



Recent advances in language modeling demonstrate the need for high-quality domain-specific training data, especially for tasks that require specialized knowledge. General-purpose models, while versatile, often lack the depth needed for expert-level tasks because of limited domain-specific information. Domain adaptation training can enhance these models, but it demands substantial, high-quality data. To address this, we propose ORBIT, a cost-efficient methodology for curating massive, high-quality domain-specific datasets from noisy web sources, tailored for training specialist large language models. Using astronomy as a primary case study, we refined the 1.3T-token FineWeb-Edu dataset into a high-quality, 10B-token subset focused on astronomy. Fine-tuning \textsc{LLaMA-3-8B} on a 1B-token astronomy subset improved performance on the MMLU astronomy benchmark from 69\% to 76\% and achieved top results on AstroBench, an astronomy-specific benchmark. Moreover, our model (Orbit-LLaMA) outperformed \textsc{LLaMA-3-8B-base}, with GPT-4o evaluations preferring it in 73\% of cases across 1000 astronomy-specific questions. Additionally, we validated ORBIT's generalizability by applying it to law and medicine, achieving a significant improvement of data quality compared to an unfiltered baseline. We open-source the ORBIT methodology, including the curated datasets, the codebase, and the resulting model at \href{https://github.com/ModeEric/ORBIT-Llama}{https://github.com/ModeEric/ORBIT-Llama}.
What Makes In-context Learning Effective for Mathematical Reasoning: A Theoretical Analysis
Dec 11, 2024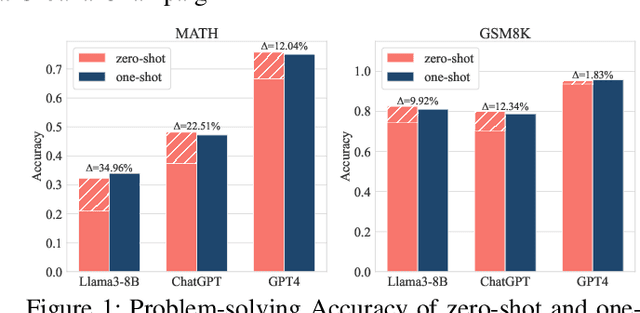
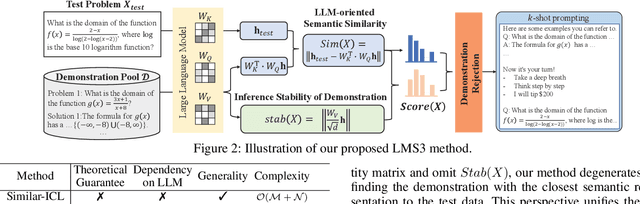
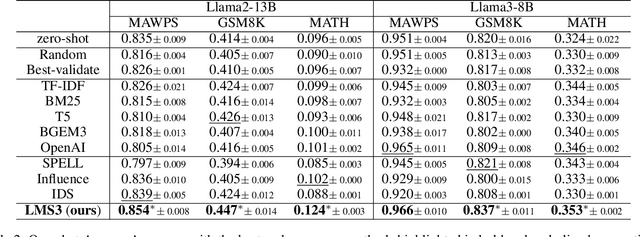
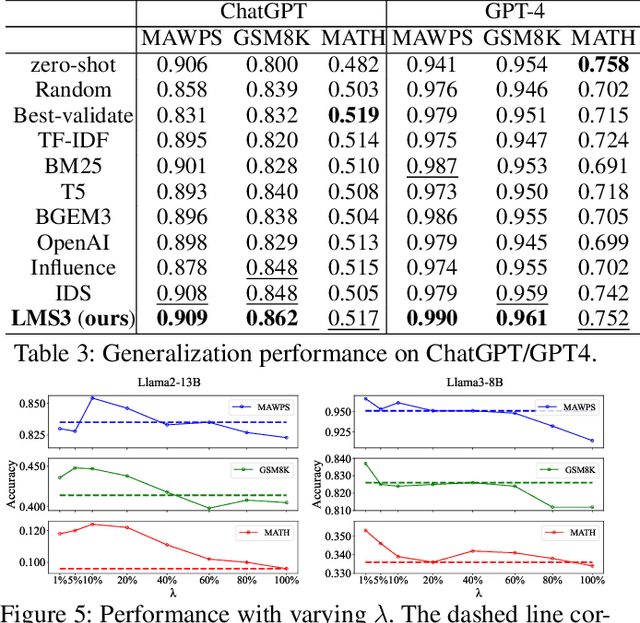
Owing to the capability of in-context learning, large language models (LLMs) have shown impressive performance across diverse mathematical reasoning benchmarks. However, we find that few-shot demonstrations can sometimes bring negative performance and their effectiveness on LLMs' reasoning abilities remains unreliable. To this end, in this paper, we aim to theoretically analyze the impact of in-context demonstrations on LLMs' reasoning performance. We prove that the reasoning efficacy (measured by empirical prediction loss) can be bounded by a LLM-oriented semantic similarity and an inference stability of demonstrations, which is general for both one-shot and few-shot scenarios. Based on this finding, we propose a straightforward, generalizable, and low-complexity demonstration selection method named LMS3. It can adaptively facilitate to select the most pertinent samples for different LLMs and includes a novel demonstration rejection mechanism to automatically filter out samples that are unsuitable for few-shot learning. Through experiments on three representative benchmarks, two LLM backbones, and multiple few-shot settings, we verify that our LMS3 has superiority and achieves consistent improvements on all datasets, which existing methods have been unable to accomplish.
Learning by Analogy: Enhancing Few-Shot Prompting for Math Word Problem Solving with Computational Graph-Based Retrieval
Nov 25, 2024



Large language models (LLMs) are known to struggle with complicated reasoning tasks such as math word problems (MWPs). In this paper, we present how analogy from similarly structured questions can improve LLMs' problem-solving capabilities for MWPs. Specifically, we rely on the retrieval of problems with similar computational graphs to the given question to serve as exemplars in the prompt, providing the correct reasoning path for the generation model to refer to. Empirical results across six math word problem datasets demonstrate the effectiveness of our proposed method, which achieves a significant improvement of up to 6.7 percent on average in absolute value, compared to baseline methods. These results highlight our method's potential in addressing the reasoning challenges in current LLMs.