 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnatomy of a failure: When, how, and why deep vision fails in scientific domains
May 05, 2026Mirroring its ubiquity in popular media and all human activities, the use of deep learning (DL) is rapidly growing in scientific imaging modalities. However, unlike everyday RGB pictures, pixels encode precise physicochemical properties in scientific imaging across potentially thousands of channels. While DL is well validated on human-centric RGB perceptual tasks, its effectiveness for scientific imaging remains uncertain. Here, we show that the naive application of DL frameworks to scientific images can lead to critical failures. We evaluate the use of DL for pathology, comparing RGB images of stained tissue with the quantitative and information-rich biochemical signatures of infrared (IR) imaging. Despite this informational advantage, DL models trained on IR data paradoxically underperform. We investigate this discrepancy to find that IR data priors interact poorly with the simplicity bias of DL, causing models to collapse to one-dimensional predictions. This constitutes a catastrophic DL failure because the model's representational capacity remains largely unused, while furthermore raising AI safety concerns and undermining the advantages of such scientific modalities. Notably, this problem persists even with state-of-the-art DL robustification strategies, which are primarily designed and validated for RGB imagery and thus inherit the same prior-bias mismatch. This work establishes a framework for understanding the limitations of generic DL in science and advocates for the study of modality-specific failure modes to guide the development of specialized, safe AI algorithms.
Hierarchical Diffusion Framework for Pseudo-Healthy Brain MRI Inpainting with Enhanced 3D Consistency
Jul 23, 2025Pseudo-healthy image inpainting is an essential preprocessing step for analyzing pathological brain MRI scans. Most current inpainting methods favor slice-wise 2D models for their high in-plane fidelity, but their independence across slices produces discontinuities in the volume. Fully 3D models alleviate this issue, but their high model capacity demands extensive training data for reliable, high-fidelity synthesis -- often impractical in medical settings. We address these limitations with a hierarchical diffusion framework by replacing direct 3D modeling with two perpendicular coarse-to-fine 2D stages. An axial diffusion model first yields a coarse, globally consistent inpainting; a coronal diffusion model then refines anatomical details. By combining perpendicular spatial views with adaptive resampling, our method balances data efficiency and volumetric consistency. Our experiments show our approach outperforms state-of-the-art baselines in both realism and volumetric consistency, making it a promising solution for pseudo-healthy image inpainting. Code is available at https://github.com/dou0000/3dMRI-Consistent-Inpaint.
Neural reservoir control of a soft bio-hybrid arm
Mar 12, 2025A long-standing engineering problem, the control of soft robots is difficult because of their highly non-linear, heterogeneous, anisotropic, and distributed nature. Here, bridging engineering and biology, a neural reservoir is employed for the dynamic control of a bio-hybrid model arm made of multiple muscle-tendon groups enveloping an elastic spine. We show how the use of reservoirs facilitates simultaneous control and self-modeling across a set of challenging tasks, outperforming classic neural network approaches. Further, by implementing a spiking reservoir on neuromorphic hardware, energy efficiency is achieved, with nearly two-orders of magnitude improvement relative to standard CPUs, with implications for the on-board control of untethered, small-scale soft robots.
Diff-Ensembler: Learning to Ensemble 2D Diffusion Models for Volume-to-Volume Medical Image Translation
Jan 13, 2025



Despite success in volume-to-volume translations in medical images, most existing models struggle to effectively capture the inherent volumetric distribution using 3D representations. The current state-of-the-art approach combines multiple 2D-based networks through weighted averaging, thereby neglecting the 3D spatial structures. Directly training 3D models in medical imaging presents significant challenges due to high computational demands and the need for large-scale datasets. To address these challenges, we introduce Diff-Ensembler, a novel hybrid 2D-3D model for efficient and effective volumetric translations by ensembling perpendicularly trained 2D diffusion models with a 3D network in each diffusion step. Moreover, our model can naturally be used to ensemble diffusion models conditioned on different modalities, allowing flexible and accurate fusion of input conditions. Extensive experiments demonstrate that Diff-Ensembler attains superior accuracy and volumetric realism in 3D medical image super-resolution and modality translation. We further demonstrate the strength of our model's volumetric realism using tumor segmentation as a downstream task.
Evidential Deep Learning for Uncertainty Quantification and Out-of-Distribution Detection in Jet Identification using Deep Neural Networks
Jan 10, 2025



Current methods commonly used for uncertainty quantification (UQ) in deep learning (DL) models utilize Bayesian methods which are computationally expensive and time-consuming. In this paper, we provide a detailed study of UQ based on evidential deep learning (EDL) for deep neural network models designed to identify jets in high energy proton-proton collisions at the Large Hadron Collider and explore its utility in anomaly detection. EDL is a DL approach that treats learning as an evidence acquisition process designed to provide confidence (or epistemic uncertainty) about test data. Using publicly available datasets for jet classification benchmarking, we explore hyperparameter optimizations for EDL applied to the challenge of UQ for jet identification. We also investigate how the uncertainty is distributed for each jet class, how this method can be implemented for the detection of anomalies, how the uncertainty compares with Bayesian ensemble methods, and how the uncertainty maps onto latent spaces for the models. Our studies uncover some pitfalls of EDL applied to anomaly detection and a more effective way to quantify uncertainty from EDL as compared with the foundational EDL setup. These studies illustrate a methodological approach to interpreting EDL in jet classification models, providing new insights on how EDL quantifies uncertainty and detects out-of-distribution data which may lead to improved EDL methods for DL models applied to classification tasks.
TinyHelen's First Curriculum: Training and Evaluating Tiny Language Models in a Simpler Language Environment
Dec 31, 2024



Training language models (LMs) and their application agents is increasingly costly due to large datasets and models, making test failures difficult to bear. Simplified language environments serve as primordial training and testing grounds, retaining essential commonsense and communication skills but in a more digestible form, potentially enhancing the learning efficiency of LMs, and thus reducing the required model size and data volume for effective training and evaluation. In these simplified language environments, workable strategies for small models, datasets, and agents may be adaptable to larger models, datasets, and agents in complex language environments. To create such environments, we focus on two aspects: i) minimizing language dataset noise and complexity, and ii) preserving the essential text distribution characteristics. Unlike previous methods, we propose a pipeline to refine text data by eliminating noise, minimizing vocabulary, and maintaining genre-specific patterns (e.g., for books, conversation, code, etc.). Implementing this pipeline with large LMs, we have created a leaner suite of LM training and evaluation datasets: 71M Leaner-Pretrain, 7M Leaner-Instruct, Leaner-Glue for assessing linguistic proficiency, and Leaner-Eval for testing instruction-following ability. Our experiments show that leaner pre-training boosts LM learning efficiency. Tiny LMs trained on these datasets outperform those trained on original datasets in instruction-following across different language granularity levels. Moreover, the Leaner-Pretrain dataset's alignment with conventional large LM training sets enables resource-optimized analysis of how learning objectives, model architectures, and training techniques impact performance on language modeling and downstream tasks. Our code and datasets are available at https://github.com/EmpathYang/TinyHelen.git.
ORBIT: Cost-Effective Dataset Curation for Large Language Model Domain Adaptation with an Astronomy Case Study
Dec 19, 2024



Recent advances in language modeling demonstrate the need for high-quality domain-specific training data, especially for tasks that require specialized knowledge. General-purpose models, while versatile, often lack the depth needed for expert-level tasks because of limited domain-specific information. Domain adaptation training can enhance these models, but it demands substantial, high-quality data. To address this, we propose ORBIT, a cost-efficient methodology for curating massive, high-quality domain-specific datasets from noisy web sources, tailored for training specialist large language models. Using astronomy as a primary case study, we refined the 1.3T-token FineWeb-Edu dataset into a high-quality, 10B-token subset focused on astronomy. Fine-tuning \textsc{LLaMA-3-8B} on a 1B-token astronomy subset improved performance on the MMLU astronomy benchmark from 69\% to 76\% and achieved top results on AstroBench, an astronomy-specific benchmark. Moreover, our model (Orbit-LLaMA) outperformed \textsc{LLaMA-3-8B-base}, with GPT-4o evaluations preferring it in 73\% of cases across 1000 astronomy-specific questions. Additionally, we validated ORBIT's generalizability by applying it to law and medicine, achieving a significant improvement of data quality compared to an unfiltered baseline. We open-source the ORBIT methodology, including the curated datasets, the codebase, and the resulting model at \href{https://github.com/ModeEric/ORBIT-Llama}{https://github.com/ModeEric/ORBIT-Llama}.
Transforming the Hybrid Cloud for Emerging AI Workloads
Nov 20, 2024



This white paper, developed through close collaboration between IBM Research and UIUC researchers within the IIDAI Institute, envisions transforming hybrid cloud systems to meet the growing complexity of AI workloads through innovative, full-stack co-design approaches, emphasizing usability, manageability, affordability, adaptability, efficiency, and scalability. By integrating cutting-edge technologies such as generative and agentic AI, cross-layer automation and optimization, unified control plane, and composable and adaptive system architecture, the proposed framework addresses critical challenges in energy efficiency, performance, and cost-effectiveness. Incorporating quantum computing as it matures will enable quantum-accelerated simulations for materials science, climate modeling, and other high-impact domains. Collaborative efforts between academia and industry are central to this vision, driving advancements in foundation models for material design and climate solutions, scalable multimodal data processing, and enhanced physics-based AI emulators for applications like weather forecasting and carbon sequestration. Research priorities include advancing AI agentic systems, LLM as an Abstraction (LLMaaA), AI model optimization and unified abstractions across heterogeneous infrastructure, end-to-end edge-cloud transformation, efficient programming model, middleware and platform, secure infrastructure, application-adaptive cloud systems, and new quantum-classical collaborative workflows. These ideas and solutions encompass both theoretical and practical research questions, requiring coordinated input and support from the research community. This joint initiative aims to establish hybrid clouds as secure, efficient, and sustainable platforms, fostering breakthroughs in AI-driven applications and scientific discovery across academia, industry, and society.
RL-Pruner: Structured Pruning Using Reinforcement Learning for CNN Compression and Acceleration
Nov 10, 2024



Convolutional Neural Networks (CNNs) have demonstrated exceptional performance in recent years. Compressing these models not only reduces storage requirements, making deployment to edge devices feasible, but also accelerates inference, thereby reducing latency and computational costs. Structured pruning, which removes filters at the layer level, directly modifies the model architecture. This approach achieves a more compact architecture while maintaining target accuracy, ensuring that the compressed model retains good compatibility and hardware efficiency. Our method is based on a key observation: filters in different layers of a neural network have varying importance to the model's performance. When the number of filters to prune is fixed, the optimal pruning distribution across different layers is uneven to minimize performance loss. Layers that are more sensitive to pruning should account for a smaller proportion of the pruning distribution. To leverage this insight, we propose RL-Pruner, which uses reinforcement learning to learn the optimal pruning distribution. RL-Pruner can automatically extract dependencies between filters in the input model and perform pruning, without requiring model-specific pruning implementations. We conducted experiments on models such as GoogleNet, ResNet, and MobileNet, comparing our approach to other structured pruning methods to validate its effectiveness. Our code is available at https://github.com/Beryex/RLPruner-CNN.
AIDOVECL: AI-generated Dataset of Outpainted Vehicles for Eye-level Classification and Localization
Oct 31, 2024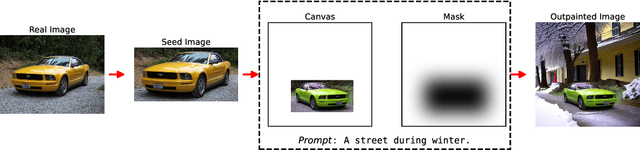



Image labeling is a critical bottleneck in the development of computer vision technologies, often constraining the potential of machine learning models due to the time-intensive nature of manual annotations. This work introduces a novel approach that leverages outpainting to address the problem of annotated data scarcity by generating artificial contexts and annotations, significantly reducing manual labeling efforts. We apply this technique to a particularly acute challenge in autonomous driving, urban planning, and environmental monitoring: the lack of diverse, eye-level vehicle images in desired classes. Our dataset comprises AI-generated vehicle images obtained by detecting and cropping vehicles from manually selected seed images, which are then outpainted onto larger canvases to simulate varied real-world conditions. The outpainted images include detailed annotations, providing high-quality ground truth data. Advanced outpainting techniques and image quality assessments ensure visual fidelity and contextual relevance. Augmentation with outpainted vehicles improves overall performance metrics by up to 8\% and enhances prediction of underrepresented classes by up to 20\%. This approach, exemplifying outpainting as a self-annotating paradigm, presents a solution that enhances dataset versatility across multiple domains of machine learning. The code and links to datasets used in this study are available for further research and replication at https://github.com/amir-kazemi/aidovecl.