 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Cross-Facility Federated Learning for Scientific Foundation Models on Multiple Supercomputers
Mar 20, 2026Artificial Intelligence for scientific applications increasingly requires training large models on data that cannot be centralized due to privacy constraints, data sovereignty, or the sheer volume of data generated. Federated learning (FL) addresses this by enabling collaborative training without centralizing raw data, but scientific applications demand model scales that requires extensive computing resources, typically offered at High Performance Computing (HPC) facilities. Deploying FL experiments across HPC facilities introduces challenges beyond cloud or enterprise settings. We present a comprehensive cross-facility FL framework for heterogeneous HPC environments, built on Advanced Privacy-Preserving Federated Learning (APPFL) framework with Globus Compute and Transfer orchestration, and evaluate it across four U.S. Department of Energy (DOE) leadership-class supercomputers. We demonstrate that FL experiments across HPC facilities are practically achievable, characterize key sources of heterogeneity impacting the training performance, and show that algorithmic choices matter significantly under realistic HPC scheduling conditions. We validate the scientific applicability by fine-tuning a large language model on a chemistry instruction dataset, and identify scheduler-aware algorithm design as a critical open challenge for future deployments.
LUMINA: Foundation Models for Topology Transferable ACOPF
Mar 04, 2026Foundation models in general promise to accelerate scientific computation by learning reusable representations across problem instances, yet constrained scientific systems, where predictions must satisfy physical laws and safety limits, pose unique challenges that stress conventional training paradigms. We derive design principles for constrained scientific foundation models through systematic investigation of AC optimal power flow (ACOPF), a representative optimization problem in power grid operations where power balance equations and operational constraints are non-negotiable. Through controlled experiments spanning architectures, training objectives, and system diversity, we extract three empirically grounded principles governing scientific foundation model design. These principles characterize three design trade-offs: learning physics-invariant representations while respecting system-specific constraints, optimizing accuracy while ensuring constraint satisfaction, and ensuring reliability in high-impact operating regimes. We present the LUMINA framework, including data processing and training pipelines to support reproducible research on physics-informed, feasibility-aware foundation models across scientific applications.
gridfm-datakit-v1: A Python Library for Scalable and Realistic Power Flow and Optimal Power Flow Data Generation
Dec 16, 2025We introduce gridfm-datakit-v1, a Python library for generating realistic and diverse Power Flow (PF) and Optimal Power Flow (OPF) datasets for training Machine Learning (ML) solvers. Existing datasets and libraries face three main challenges: (1) lack of realistic stochastic load and topology perturbations, limiting scenario diversity; (2) PF datasets are restricted to OPF-feasible points, hindering generalization of ML solvers to cases that violate operating limits (e.g., branch overloads or voltage violations); and (3) OPF datasets use fixed generator cost functions, limiting generalization across varying costs. gridfm-datakit addresses these challenges by: (1) combining global load scaling from real-world profiles with localized noise and supporting arbitrary N-k topology perturbations to create diverse yet realistic datasets; (2) generating PF samples beyond operating limits; and (3) producing OPF data with varying generator costs. It also scales efficiently to large grids (up to 10,000 buses). Comparisons with OPFData, OPF-Learn, PGLearn, and PF$Δ$ are provided. Available on GitHub at https://github.com/gridfm/gridfm-datakit under Apache 2.0 and via `pip install gridfm-datakit`.
A Randomized Zeroth-Order Hierarchical Framework for Heterogeneous Federated Learning
Apr 02, 2025



Heterogeneity in federated learning (FL) is a critical and challenging aspect that significantly impacts model performance and convergence. In this paper, we propose a novel framework by formulating heterogeneous FL as a hierarchical optimization problem. This new framework captures both local and global training process through a bilevel formulation and is capable of the following: (i) addressing client heterogeneity through a personalized learning framework; (ii) capturing pre-training process on server's side; (iii) updating global model through nonstandard aggregation; (iv) allowing for nonidentical local steps; and (v) capturing clients' local constraints. We design and analyze an implicit zeroth-order FL method (ZO-HFL), provided with nonasymptotic convergence guarantees for both the server-agent and the individual client-agents, and asymptotic guarantees for both the server-agent and client-agents in an almost sure sense. Notably, our method does not rely on standard assumptions in heterogeneous FL, such as the bounded gradient dissimilarity condition. We implement our method on image classification tasks and compare with other methods under different heterogeneous settings.
Federated Low-Rank Tensor Estimation for Multimodal Image Reconstruction
Feb 04, 2025



Low-rank tensor estimation offers a powerful approach to addressing high-dimensional data challenges and can substantially improve solutions to ill-posed inverse problems, such as image reconstruction under noisy or undersampled conditions. Meanwhile, tensor decomposition has gained prominence in federated learning (FL) due to its effectiveness in exploiting latent space structure and its capacity to enhance communication efficiency. In this paper, we present a federated image reconstruction method that applies Tucker decomposition, incorporating joint factorization and randomized sketching to manage large-scale, multimodal data. Our approach avoids reconstructing full-size tensors and supports heterogeneous ranks, allowing clients to select personalized decomposition ranks based on prior knowledge or communication capacity. Numerical results demonstrate that our method achieves superior reconstruction quality and communication compression compared to existing approaches, thereby highlighting its potential for multimodal inverse problems in the FL setting.
From RNNs to Foundation Models: An Empirical Study on Commercial Building Energy Consumption
Nov 21, 2024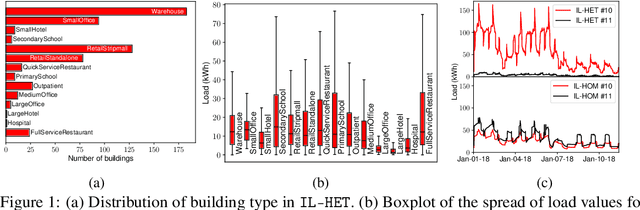
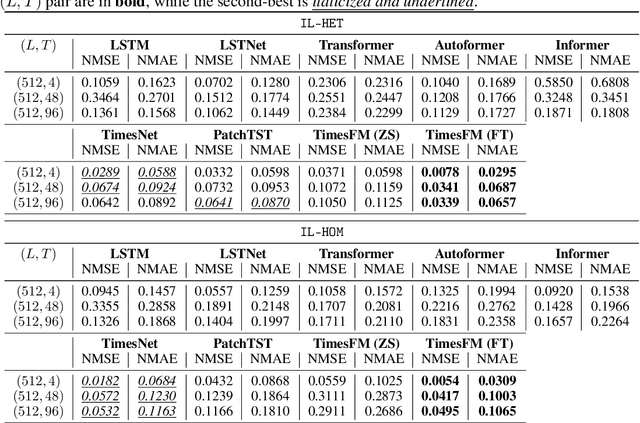
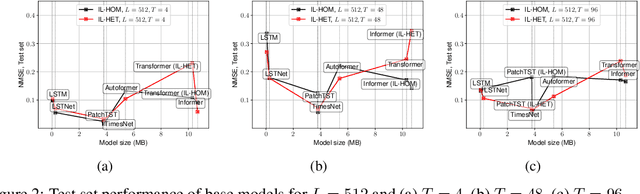

Accurate short-term energy consumption forecasting for commercial buildings is crucial for smart grid operations. While smart meters and deep learning models enable forecasting using past data from multiple buildings, data heterogeneity from diverse buildings can reduce model performance. The impact of increasing dataset heterogeneity in time series forecasting, while keeping size and model constant, is understudied. We tackle this issue using the ComStock dataset, which provides synthetic energy consumption data for U.S. commercial buildings. Two curated subsets, identical in size and region but differing in building type diversity, are used to assess the performance of various time series forecasting models, including fine-tuned open-source foundation models (FMs). The results show that dataset heterogeneity and model architecture have a greater impact on post-training forecasting performance than the parameter count. Moreover, despite the higher computational cost, fine-tuned FMs demonstrate competitive performance compared to base models trained from scratch.
FedSpaLLM: Federated Pruning of Large Language Models
Oct 18, 2024



Large Language Models (LLMs) achieve state-of-the-art performance but are challenging to deploy due to their high computational and storage demands. Pruning can reduce model size, yet existing methods assume public access to calibration data, which is impractical for privacy-sensitive applications. To address the challenge of pruning LLMs in privacy-preserving settings, we propose FedSpaLLM, the first federated learning framework designed specifically for pruning LLMs. FedSpaLLM enables clients to prune their models locally based on private data while accounting for system heterogeneity and maintaining communication efficiency. Our framework introduces several key innovations: (1) a novel $\ell_0$-norm aggregation function that ensures only non-zero weights are averaged across clients, preserving important model parameters; (2) an adaptive mask expansion technique that meets global sparsity targets while accommodating client-specific pruning decisions; and (3) a layer sampling strategy that reduces communication overhead and personalizes the pruning process based on client resources. Extensive experiments show that FedSpaLLM improves pruning performance in diverse federated settings. The source code will be released upon publication.
Advances in APPFL: A Comprehensive and Extensible Federated Learning Framework
Sep 17, 2024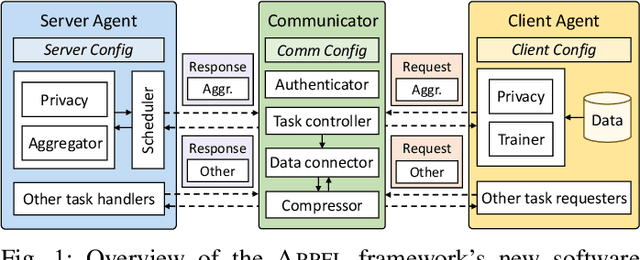


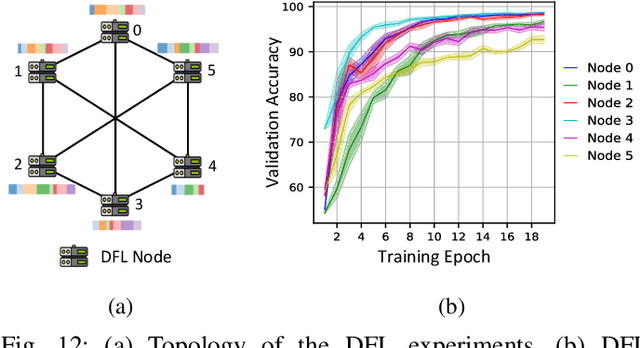
Federated learning (FL) is a distributed machine learning paradigm enabling collaborative model training while preserving data privacy. In today's landscape, where most data is proprietary, confidential, and distributed, FL has become a promising approach to leverage such data effectively, particularly in sensitive domains such as medicine and the electric grid. Heterogeneity and security are the key challenges in FL, however; most existing FL frameworks either fail to address these challenges adequately or lack the flexibility to incorporate new solutions. To this end, we present the recent advances in developing APPFL, an extensible framework and benchmarking suite for federated learning, which offers comprehensive solutions for heterogeneity and security concerns, as well as user-friendly interfaces for integrating new algorithms or adapting to new applications. We demonstrate the capabilities of APPFL through extensive experiments evaluating various aspects of FL, including communication efficiency, privacy preservation, computational performance, and resource utilization. We further highlight the extensibility of APPFL through case studies in vertical, hierarchical, and decentralized FL. APPFL is open-sourced at https://github.com/APPFL/APPFL.
A Perspective on Foundation Models for the Electric Power Grid
Jul 12, 2024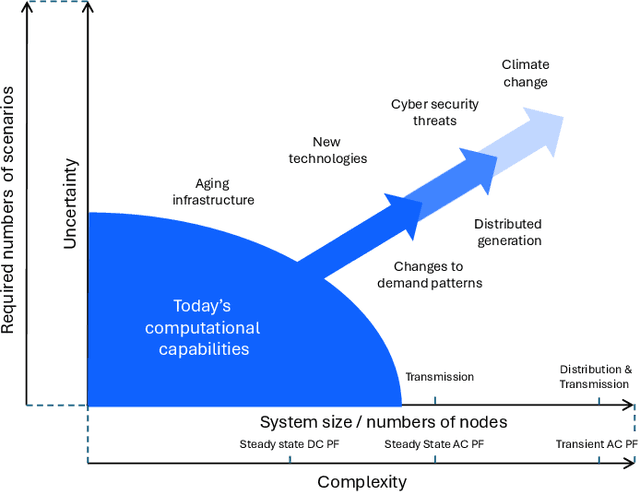
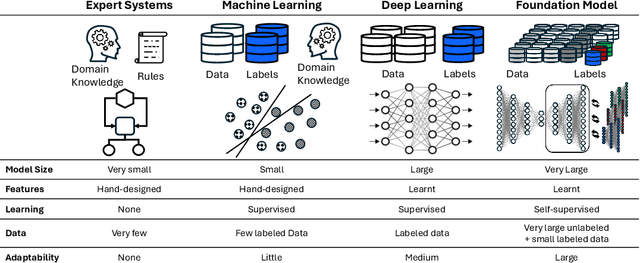
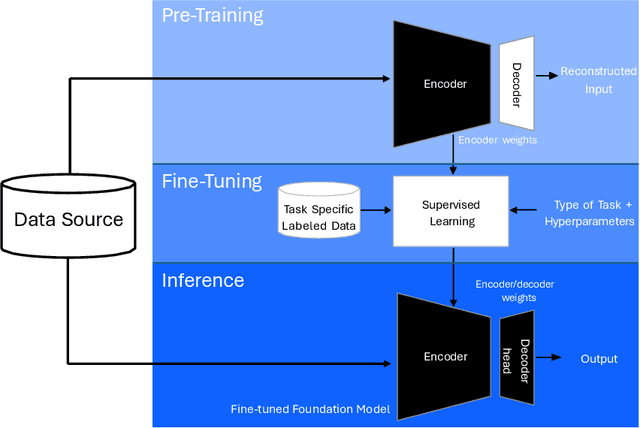
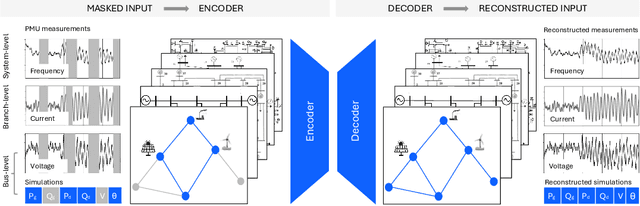
Foundation models (FMs) currently dominate news headlines. They employ advanced deep learning architectures to extract structural information autonomously from vast datasets through self-supervision. The resulting rich representations of complex systems and dynamics can be applied to many downstream applications. Therefore, FMs can find uses in electric power grids, challenged by the energy transition and climate change. In this paper, we call for the development of, and state why we believe in, the potential of FMs for electric grids. We highlight their strengths and weaknesses amidst the challenges of a changing grid. We argue that an FM learning from diverse grid data and topologies could unlock transformative capabilities, pioneering a new approach in leveraging AI to redefine how we manage complexity and uncertainty in the electric grid. Finally, we discuss a power grid FM concept, namely GridFM, based on graph neural networks and show how different downstream tasks benefit.
Asynchronous Federated Stochastic Optimization with Exact Averaging for Heterogeneous Local Objectives
May 16, 2024



Federated learning (FL) was recently proposed to securely train models with data held over multiple locations ("clients") under the coordination of a central server. Two major challenges hindering the performance of FL algorithms are long training times caused by straggling clients and a decrease in training accuracy induced by non-iid local distributions ("client drift"). In this work we propose and analyze AREA, a new stochastic (sub)gradient algorithm that is robust to client drift and utilizes asynchronous communication to speed up convergence in the presence of stragglers. Moreover, AREA is, to the best of our knowledge, the first method that is both guaranteed to converge under arbitrarily long delays, and converges to an error neighborhood whose size depends only on the variance of the stochastic (sub)gradients used and thus is independent of both the heterogeneity between the local datasets and the length of client delays, without the use of delay-adaptive stepsizes. Our numerical results confirm our theoretical analysis and suggest that AREA outperforms state-of-the-art methods when local data are highly non-iid.