 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSecure Federated Learning Across Heterogeneous Cloud and High-Performance Computing Resources -- A Case Study on Federated Fine-tuning of LLaMA 2
Feb 19, 2024


Federated learning enables multiple data owners to collaboratively train robust machine learning models without transferring large or sensitive local datasets by only sharing the parameters of the locally trained models. In this paper, we elaborate on the design of our Advanced Privacy-Preserving Federated Learning (APPFL) framework, which streamlines end-to-end secure and reliable federated learning experiments across cloud computing facilities and high-performance computing resources by leveraging Globus Compute, a distributed function as a service platform, and Amazon Web Services. We further demonstrate the use case of APPFL in fine-tuning a LLaMA 2 7B model using several cloud resources and supercomputers.
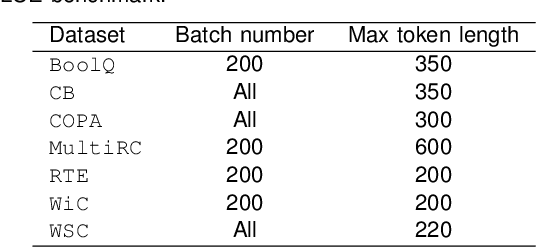
FedCompass: Efficient Cross-Silo Federated Learning on Heterogeneous Client Devices using a Computing Power Aware Scheduler
Sep 26, 2023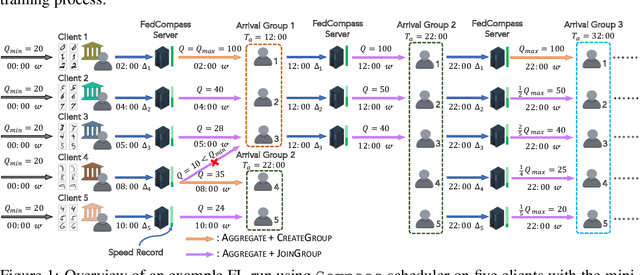

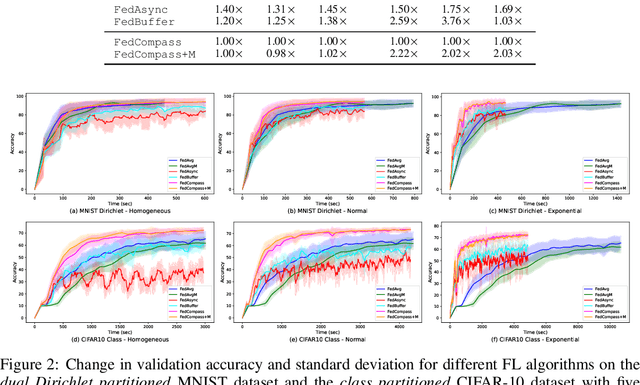

Cross-silo federated learning offers a promising solution to collaboratively train robust and generalized AI models without compromising the privacy of local datasets, e.g., healthcare, financial, as well as scientific projects that lack a centralized data facility. Nonetheless, because of the disparity of computing resources among different clients (i.e., device heterogeneity), synchronous federated learning algorithms suffer from degraded efficiency when waiting for straggler clients. Similarly, asynchronous federated learning algorithms experience degradation in the convergence rate and final model accuracy on non-identically and independently distributed (non-IID) heterogeneous datasets due to stale local models and client drift. To address these limitations in cross-silo federated learning with heterogeneous clients and data, we propose FedCompass, an innovative semi-asynchronous federated learning algorithm with a computing power aware scheduler on the server side, which adaptively assigns varying amounts of training tasks to different clients using the knowledge of the computing power of individual clients. FedCompass ensures that multiple locally trained models from clients are received almost simultaneously as a group for aggregation, effectively reducing the staleness of local models. At the same time, the overall training process remains asynchronous, eliminating prolonged waiting periods from straggler clients. Using diverse non-IID heterogeneous distributed datasets, we demonstrate that FedCompass achieves faster convergence and higher accuracy than other asynchronous algorithms while remaining more efficient than synchronous algorithms when performing federated learning on heterogeneous clients.
APPFLx: Providing Privacy-Preserving Cross-Silo Federated Learning as a Service
Aug 17, 2023



Cross-silo privacy-preserving federated learning (PPFL) is a powerful tool to collaboratively train robust and generalized machine learning (ML) models without sharing sensitive (e.g., healthcare of financial) local data. To ease and accelerate the adoption of PPFL, we introduce APPFLx, a ready-to-use platform that provides privacy-preserving cross-silo federated learning as a service. APPFLx employs Globus authentication to allow users to easily and securely invite trustworthy collaborators for PPFL, implements several synchronous and asynchronous FL algorithms, streamlines the FL experiment launch process, and enables tracking and visualizing the life cycle of FL experiments, allowing domain experts and ML practitioners to easily orchestrate and evaluate cross-silo FL under one platform. APPFLx is available online at https://appflx.link
FAIR principles for AI models, with a practical application for accelerated high energy diffraction microscopy
Jul 14, 2022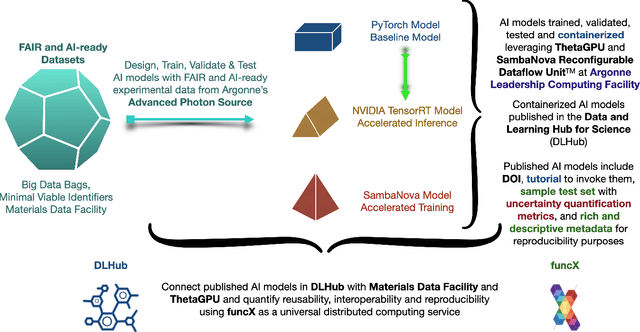
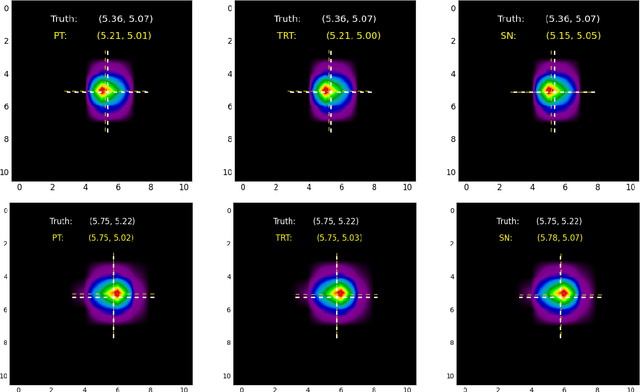
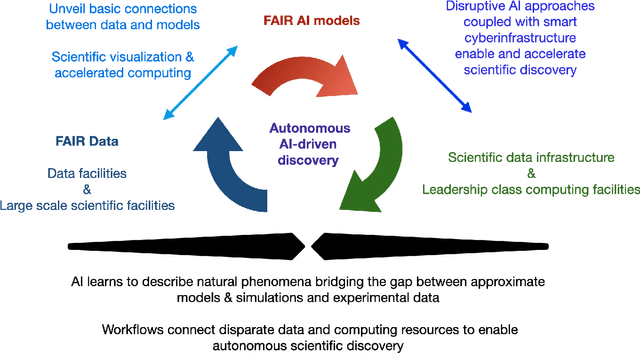
A concise and measurable set of FAIR (Findable, Accessible, Interoperable and Reusable) principles for scientific data is transforming the state-of-practice for data management and stewardship, supporting and enabling discovery and innovation. Learning from this initiative, and acknowledging the impact of artificial intelligence (AI) in the practice of science and engineering, we introduce a set of practical, concise, and measurable FAIR principles for AI models. We showcase how to create and share FAIR data and AI models within a unified computational framework combining the following elements: the Advanced Photon Source at Argonne National Laboratory, the Materials Data Facility, the Data and Learning Hub for Science, and funcX, and the Argonne Leadership Computing Facility (ALCF), in particular the ThetaGPU supercomputer and the SambaNova DataScale system at the ALCF AI Testbed. We describe how this domain-agnostic computational framework may be harnessed to enable autonomous AI-driven discovery.
Inference-optimized AI and high performance computing for gravitational wave detection at scale
Jan 26, 2022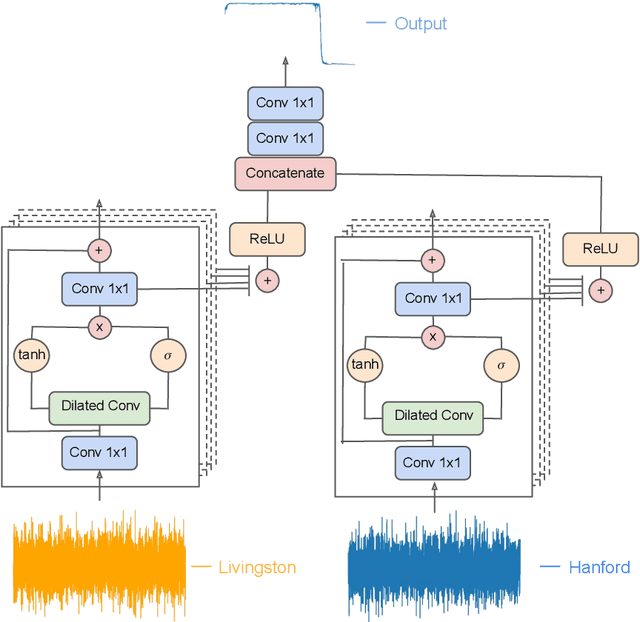
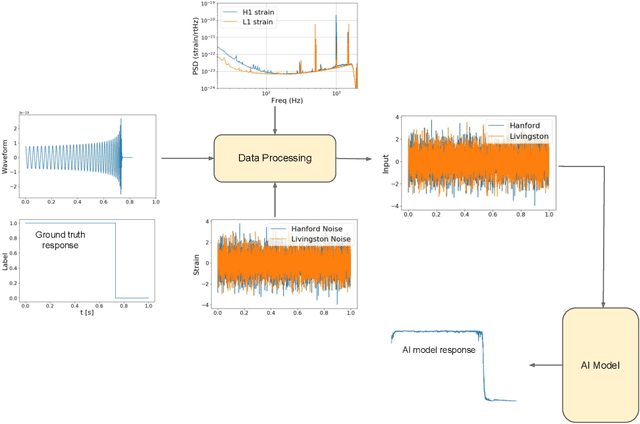
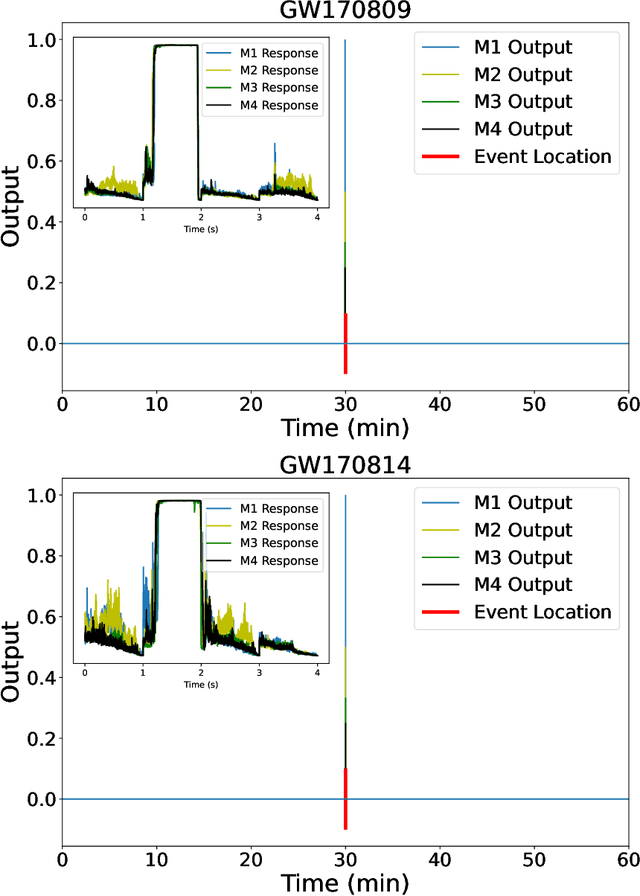
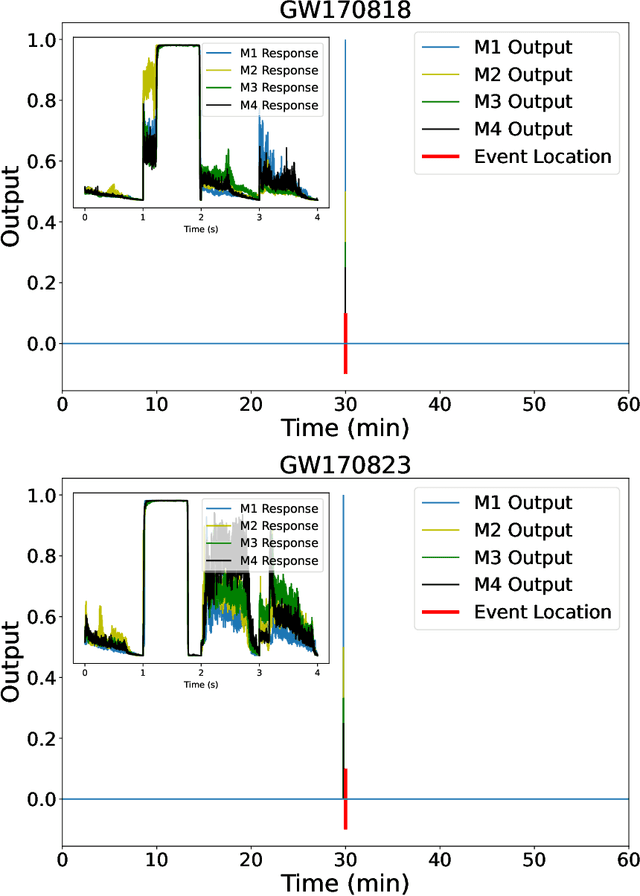
We introduce an ensemble of artificial intelligence models for gravitational wave detection that we trained in the Summit supercomputer using 32 nodes, equivalent to 192 NVIDIA V100 GPUs, within 2 hours. Once fully trained, we optimized these models for accelerated inference using NVIDIA TensorRT. We deployed our inference-optimized AI ensemble in the ThetaGPU supercomputer at Argonne Leadership Computer Facility to conduct distributed inference. Using the entire ThetaGPU supercomputer, consisting of 20 nodes each of which has 8 NVIDIA A100 Tensor Core GPUs and 2 AMD Rome CPUs, our NVIDIA TensorRT-optimized AI ensemble porcessed an entire month of advanced LIGO data (including Hanford and Livingston data streams) within 50 seconds. Our inference-optimized AI ensemble retains the same sensitivity of traditional AI models, namely, it identifies all known binary black hole mergers previously identified in this advanced LIGO dataset and reports no misclassifications, while also providing a 3X inference speedup compared to traditional artificial intelligence models. We used time slides to quantify the performance of our AI ensemble to process up to 5 years worth of advanced LIGO data. In this synthetically enhanced dataset, our AI ensemble reports an average of one misclassification for every month of searched advanced LIGO data. We also present the receiver operating characteristic curve of our AI ensemble using this 5 year long advanced LIGO dataset. This approach provides the required tools to conduct accelerated, AI-driven gravitational wave detection at scale.