 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEVerA: Verified Synthesis of Self-Evolving Agents
Mar 26, 2026Recent advances have shown the effectiveness of self-evolving LLM agents on tasks such as program repair and scientific discovery. In this paradigm, a planner LLM synthesizes an agent program that invokes parametric models, including LLMs, which are then tuned per task to improve performance. However, existing self-evolving agent frameworks provide no formal guarantees of safety or correctness. Because such programs are often executed autonomously on unseen inputs, this lack of guarantees raises reliability and security concerns. We formulate agentic code generation as a constrained learning problem, combining hard formal specifications with soft objectives capturing task utility. We introduce Formally Guarded Generative Models (FGGM), which allow the planner LLM to specify a formal output contract for each generative model call using first-order logic. Each FGGM call wraps the underlying model in a rejection sampler with a verified fallback, ensuring every returned output satisfies the contract for any input and parameter setting. Building on FGGM, we present SEVerA (Self-Evolving Verified Agents), a three-stage framework: Search synthesizes candidate parametric programs containing FGGM calls; Verification proves correctness with respect to hard constraints for all parameter values, reducing the problem to unconstrained learning; and Learning applies scalable gradient-based optimization, including GRPO-style fine-tuning, to improve the soft objective while preserving correctness. We evaluate SEVerA on Dafny program verification, symbolic math synthesis, and policy-compliant agentic tool use ($τ^2$-bench). Across tasks, SEVerA achieves zero constraint violations while improving performance over unconstrained and SOTA baselines, showing that formal behavioral constraints not only guarantee correctness but also steer synthesis toward higher-quality agents.
D-SECURE: Dual-Source Evidence Combination for Unified Reasoning in Misinformation Detection
Feb 16, 2026Multimodal misinformation increasingly mixes realistic im-age edits with fluent but misleading text, producing persuasive posts that are difficult to verify. Existing systems usually rely on a single evidence source. Content-based detectors identify local inconsistencies within an image and its caption but cannot determine global factual truth. Retrieval-based fact-checkers reason over external evidence but treat inputs as coarse claims and often miss subtle visual or textual manipulations. This separation creates failure cases where internally consistent fabrications bypass manipulation detectors and fact-checkers verify claims that contain pixel-level or token-level corruption. We present D-SECURE, a framework that combines internal manipulation detection with external evidence-based reasoning for news-style posts. D-SECURE integrates the HAMMER manipulation detector with the DEFAME retrieval pipeline. DEFAME performs broad verification, and HAMMER analyses residual or uncertain cases that may contain fine-grained edits. Experiments on DGM4 and ClaimReview samples highlight the complementary strengths of both systems and motivate their fusion. We provide a unified, explainable report that incorporates manipulation cues and external evidence.
Formal Synthesis of Certifiably Robust Neural Lyapunov-Barrier Certificates
Feb 05, 2026Neural Lyapunov and barrier certificates have recently been used as powerful tools for verifying the safety and stability properties of deep reinforcement learning (RL) controllers. However, existing methods offer guarantees only under fixed ideal unperturbed dynamics, limiting their reliability in real-world applications where dynamics may deviate due to uncertainties. In this work, we study the problem of synthesizing \emph{robust neural Lyapunov barrier certificates} that maintain their guarantees under perturbations in system dynamics. We formally define a robust Lyapunov barrier function and specify sufficient conditions based on Lipschitz continuity that ensure robustness against bounded perturbations. We propose practical training objectives that enforce these conditions via adversarial training, Lipschitz neighborhood bound, and global Lipschitz regularization. We validate our approach in two practically relevant environments, Inverted Pendulum and 2D Docking. The former is a widely studied benchmark, while the latter is a safety-critical task in autonomous systems. We show that our methods significantly improve both certified robustness bounds (up to $4.6$ times) and empirical success rates under strong perturbations (up to $2.4$ times) compared to the baseline. Our results demonstrate effectiveness of training robust neural certificates for safe RL under perturbations in dynamics.
Enforcing Temporal Constraints for LLM Agents
Dec 25, 2025LLM-based agents are deployed in safety-critical applications, yet current guardrail systems fail to prevent violations of temporal safety policies, requirements that govern the ordering and sequencing of agent actions. For instance, agents may access sensitive data before authenticating users or process refunds to unauthorized payment methods, violations that require reasoning about sequences of action rather than an individual action. Existing guardrails rely on imprecise natural language instructions or post-hoc monitoring, and provide no formal guarantees that agents will satisfy temporal constraints. We present Agent-C, a novel framework that provides run-time guarantees ensuring LLM agents adhere to formal temporal safety properties. Agent-C introduces a domain-specific language for expressing temporal properties (e.g., authenticate before accessing data), translates specifications to first-order logic, and uses SMT solving to detect non-compliant agent actions during token generation. When the LLM attempts to generate a non-compliant tool call, Agent-C leverages constrained generation techniques to ensure that every action generated by the LLM complies with the specification, and to generate a compliant alternative to a non-compliant agent action. We evaluate Agent-C across two real-world applications: retail customer service and airline ticket reservation system, and multiple language models (open and closed-source). Our results demonstrate that Agent-C achieves perfect safety (100% conformance, 0% harm), while improving task utility compared to state-of-the-art guardrails and unrestricted agents. On SoTA closed-source models, Agent-C improves conformance (77.4% to 100% for Claude Sonnet 4.5 and 83.7% to 100% for GPT-5), while simultaneously increasing utility (71.8% to 75.2% and 66.1% to 70.6%, respectively), representing a new SoTA frontier for reliable agentic reasoning.
Cost-Driven Synthesis of Sound Abstract Interpreters
Nov 17, 2025Constructing abstract interpreters that provide global soundness guarantees remains a major obstacle in abstract interpretation. We investigate whether modern LLMs can reduce this burden by leveraging them to synthesize sound, non-trivial abstract interpreters across multiple abstract domains in the setting of neural network verification. We formulate synthesis as a constrained optimization problem and introduce a novel mathematically grounded cost function for measuring unsoundness under strict syntactic and semantic constraints. Based on this formulation, we develop a unified framework that unifies LLM-based generation with syntactic and semantic validation and a quantitative cost-guided feedback mechanism. Empirical results demonstrate that our framework not only matches the quality of handcrafted transformers, but more importantly, discovers sound, high-precision transformers for complex nonlinear operators that are absent from existing literature.
NeuroRAD-FM: A Foundation Model for Neuro-Oncology with Distributionally Robust Training
Sep 18, 2025



Neuro-oncology poses unique challenges for machine learning due to heterogeneous data and tumor complexity, limiting the ability of foundation models (FMs) to generalize across cohorts. Existing FMs also perform poorly in predicting uncommon molecular markers, which are essential for treatment response and risk stratification. To address these gaps, we developed a neuro-oncology specific FM with a distributionally robust loss function, enabling accurate estimation of tumor phenotypes while maintaining cross-institution generalization. We pretrained self-supervised backbones (BYOL, DINO, MAE, MoCo) on multi-institutional brain tumor MRI and applied distributionally robust optimization (DRO) to mitigate site and class imbalance. Downstream tasks included molecular classification of common markers (MGMT, IDH1, 1p/19q, EGFR), uncommon alterations (ATRX, TP53, CDKN2A/2B, TERT), continuous markers (Ki-67, TP53), and overall survival prediction in IDH1 wild-type glioblastoma at UCSF, UPenn, and CUIMC. Our method improved molecular prediction and reduced site-specific embedding differences. At CUIMC, mean balanced accuracy rose from 0.744 to 0.785 and AUC from 0.656 to 0.676, with the largest gains for underrepresented endpoints (CDKN2A/2B accuracy 0.86 to 0.92, AUC 0.73 to 0.92; ATRX AUC 0.69 to 0.82; Ki-67 accuracy 0.60 to 0.69). For survival, c-index improved at all sites: CUIMC 0.592 to 0.597, UPenn 0.647 to 0.672, UCSF 0.600 to 0.627. Grad-CAM highlighted tumor and peri-tumoral regions, confirming interpretability. Overall, coupling FMs with DRO yields more site-invariant representations, improves prediction of common and uncommon markers, and enhances survival discrimination, underscoring the need for prospective validation and integration of longitudinal and interventional signals to advance precision neuro-oncology.
A Tensor-Based Compiler and a Runtime for Neuron-Level DNN Certifier Specifications
Jul 26, 2025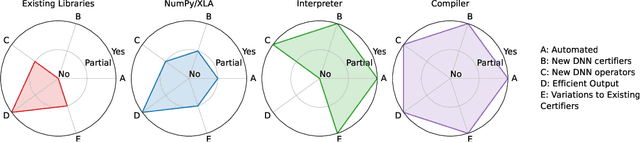


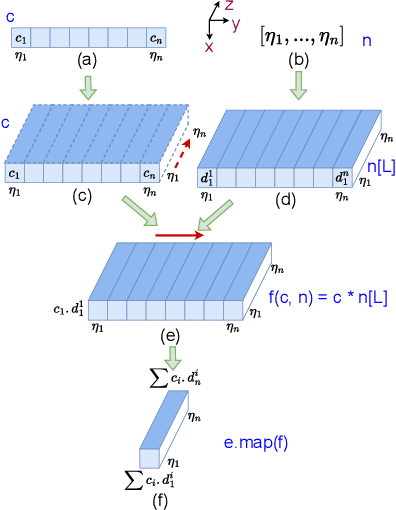
The uninterpretability of DNNs has led to the adoption of abstract interpretation-based certification as a practical means to establish trust in real-world systems that rely on DNNs. However, the current landscape supports only a limited set of certifiers, and developing new ones or modifying existing ones for different applications remains difficult. This is because the mathematical design of certifiers is expressed at the neuron level, while their implementations are optimized and executed at the tensor level. This mismatch creates a semantic gap between design and implementation, making manual bridging both complex and expertise-intensive -- requiring deep knowledge in formal methods, high-performance computing, etc. We propose a compiler framework that automatically translates neuron-level specifications of DNN certifiers into tensor-based, layer-level implementations. This is enabled by two key innovations: a novel stack-based intermediate representation (IR) and a shape analysis that infers the implicit tensor operations needed to simulate the neuron-level semantics. During lifting, the shape analysis creates tensors in the minimal shape required to perform the corresponding operations. The IR also enables domain-specific optimizations as rewrites. At runtime, the resulting tensor computations exhibit sparsity tied to the DNN architecture. This sparsity does not align well with existing formats. To address this, we introduce g-BCSR, a double-compression format that represents tensors as collections of blocks of varying sizes, each possibly internally sparse. Using our compiler and g-BCSR, we make it easy to develop new certifiers and analyze their utility across diverse DNNs. Despite its flexibility, the compiler achieves performance comparable to hand-optimized implementations.
Compression Aware Certified Training
Jun 13, 2025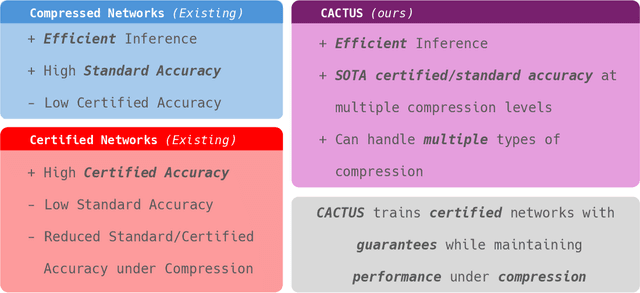
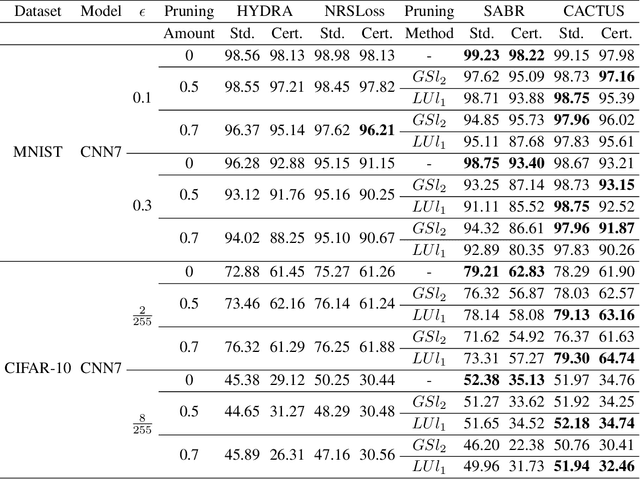
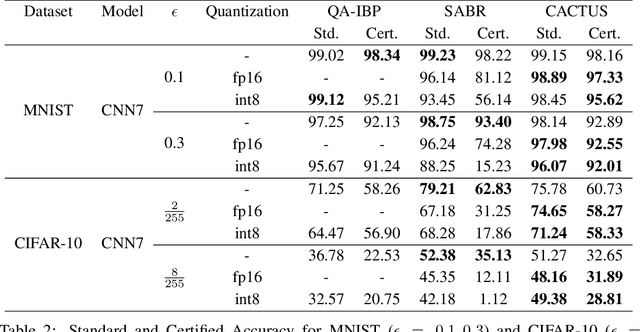
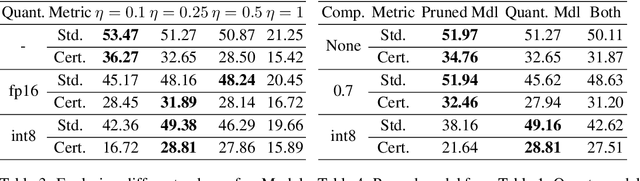
Deep neural networks deployed in safety-critical, resource-constrained environments must balance efficiency and robustness. Existing methods treat compression and certified robustness as separate goals, compromising either efficiency or safety. We propose CACTUS (Compression Aware Certified Training Using network Sets), a general framework for unifying these objectives during training. CACTUS models maintain high certified accuracy even when compressed. We apply CACTUS for both pruning and quantization and show that it effectively trains models which can be efficiently compressed while maintaining high accuracy and certifiable robustness. CACTUS achieves state-of-the-art accuracy and certified performance for both pruning and quantization on a variety of datasets and input specifications.
Data Shifts Hurt CoT: A Theoretical Study
Jun 12, 2025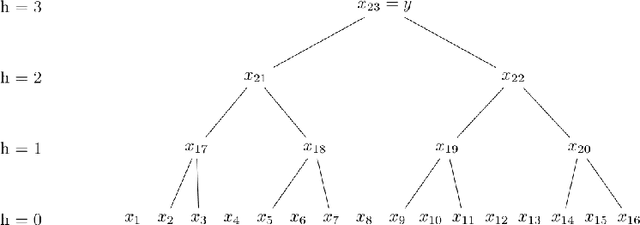
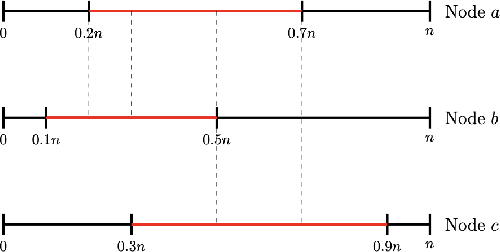
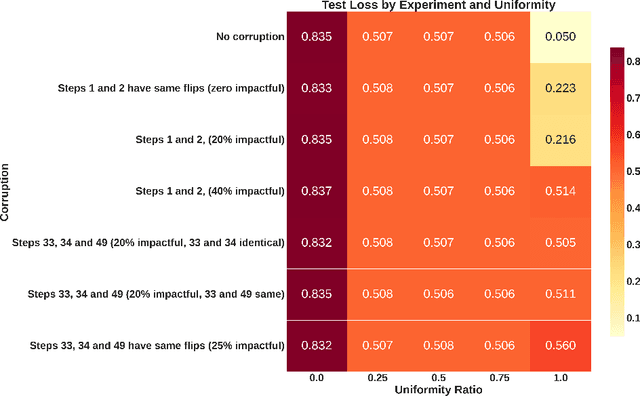
Chain of Thought (CoT) has been applied to various large language models (LLMs) and proven to be effective in improving the quality of outputs. In recent studies, transformers are proven to have absolute upper bounds in terms of expressive power, and consequently, they cannot solve many computationally difficult problems. However, empowered by CoT, transformers are proven to be able to solve some difficult problems effectively, such as the $k$-parity problem. Nevertheless, those works rely on two imperative assumptions: (1) identical training and testing distribution, and (2) corruption-free training data with correct reasoning steps. However, in the real world, these assumptions do not always hold. Although the risks of data shifts have caught attention, our work is the first to rigorously study the exact harm caused by such shifts to the best of our knowledge. Focusing on the $k$-parity problem, in this work we investigate the joint impact of two types of data shifts: the distribution shifts and data poisoning, on the quality of trained models obtained by a well-established CoT decomposition. In addition to revealing a surprising phenomenon that CoT leads to worse performance on learning parity than directly generating the prediction, our technical results also give a rigorous and comprehensive explanation of the mechanistic reasons of such impact.
TRAP: Targeted Redirecting of Agentic Preferences
May 29, 2025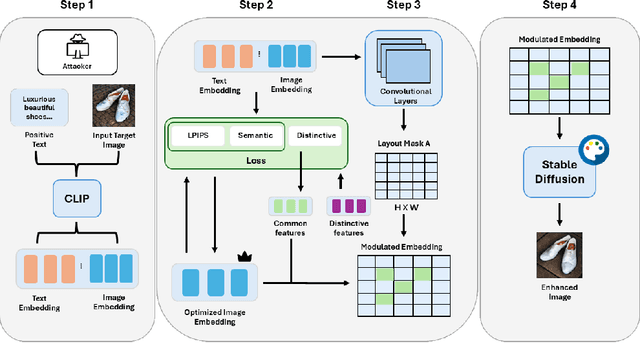


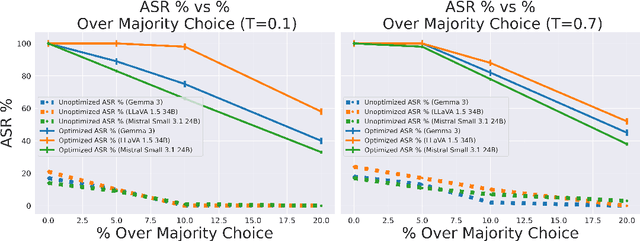
Autonomous agentic AI systems powered by vision-language models (VLMs) are rapidly advancing toward real-world deployment, yet their cross-modal reasoning capabilities introduce new attack surfaces for adversarial manipulation that exploit semantic reasoning across modalities. Existing adversarial attacks typically rely on visible pixel perturbations or require privileged model or environment access, making them impractical for stealthy, real-world exploitation. We introduce TRAP, a generative adversarial framework that manipulates the agent's decision-making using diffusion-based semantic injections. Our method combines negative prompt-based degradation with positive semantic optimization, guided by a Siamese semantic network and layout-aware spatial masking. Without requiring access to model internals, TRAP produces visually natural images yet induces consistent selection biases in agentic AI systems. We evaluate TRAP on the Microsoft Common Objects in Context (COCO) dataset, building multi-candidate decision scenarios. Across these scenarios, TRAP achieves a 100% attack success rate on leading models, including LLaVA-34B, Gemma3, and Mistral-3.1, significantly outperforming baselines such as SPSA, Bandit, and standard diffusion approaches. These results expose a critical vulnerability: Autonomous agents can be consistently misled through human-imperceptible cross-modal manipulations. These findings highlight the need for defense strategies beyond pixel-level robustness to address semantic vulnerabilities in cross-modal decision-making.